Opensearch의 분산 아키텍처 구성 요소
클러스터 (cluster)
여러 개의 노드가 모인 것
노드 (node)
클러스터를 구성하는 하나의 (JVM) 인스턴스
- 하나의 머신도 여러 개의 노드로 구성할 수도 있음
- availability를 높이기 위해 여러 개의 노드를 구성하기 때문에 보통 하나의 노드는 하나의 머신으로 구성
- TCP 통신을 수행
- 다양한 노드 종류가 있고, 노드의 종류에 따라 수행하는 역할이 달라짐
샤드 (shard)
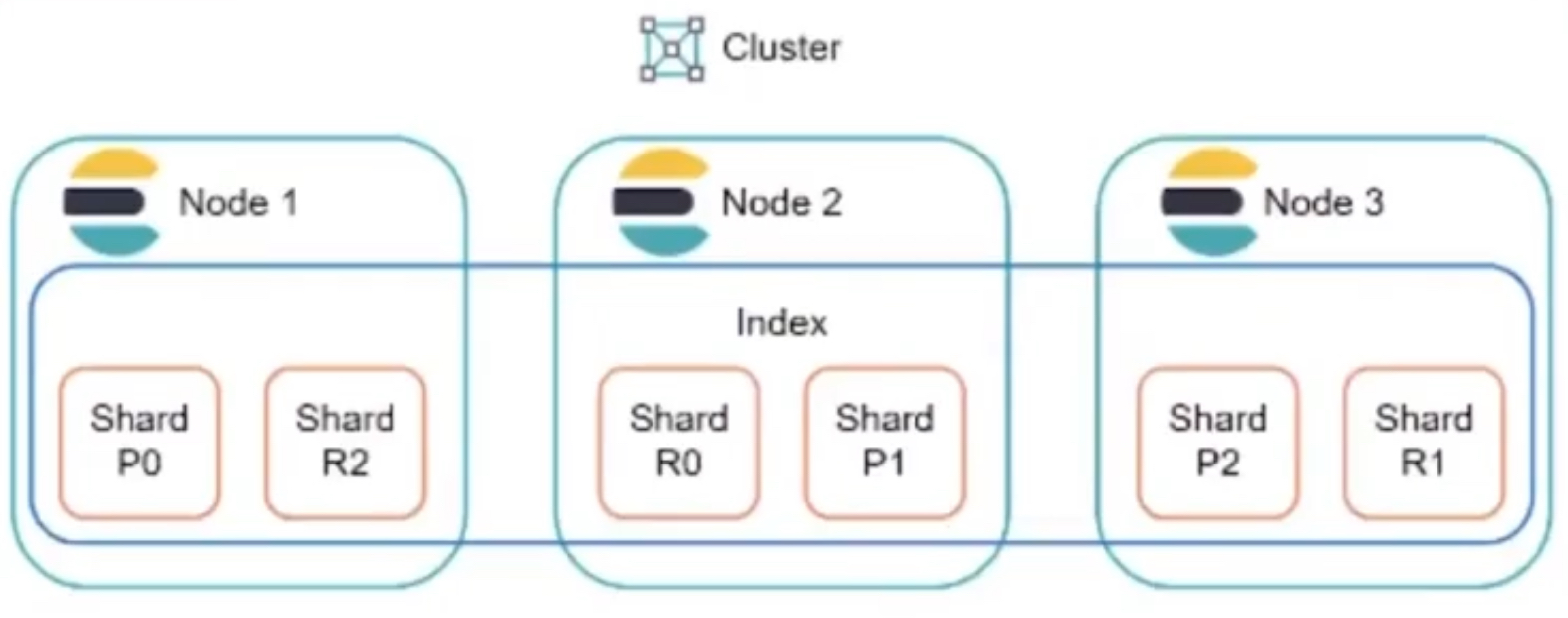
- 샤드 : 샤딩을 통해 나뉘어진 데이터 블록
- 샤딩은 데이터를 여러 개 조각(샤드)으로 나누어 분산 저장하여 관리하는 기술
- 인덱스는 논리적 단위이며, 도큐먼트 인덱싱과 검색은 샤드에서 이뤄짐
- 인덱스는 분산된 샤드를 하나의 논리적 단위로 묶은 것
- 복제본을 만들 수 있음
- 기본적으로 인덱스 하나에 5개의 샤드가 생성되고 인덱스 생성후에는 샤드 개수를 변경할 수 없음 ( 라우팅 방식)
- 장점
- 여러 물리 장비를 활용해 수평적 확장이 가능
- 동일한 인덱스에 대한 요청을 병렬적으로 처리 가능
- 레플리카 샤드를 이용해 고가용성과 빠른 속도 처리가 가능
라우팅
shard = hash(_routing) % $(primary shard num)- 도큐먼트를 저장할 샤드를 결정하는 것
- 기본적으로 저장하려는 도큐먼트의 ID와 동일
커스텀 라우팅
- "_routing"을 직접 지정
- 같은 "_routing"을 공유하는 도큐먼트들을 동일한 샤드에 저장 가능
세그먼트 (segment)
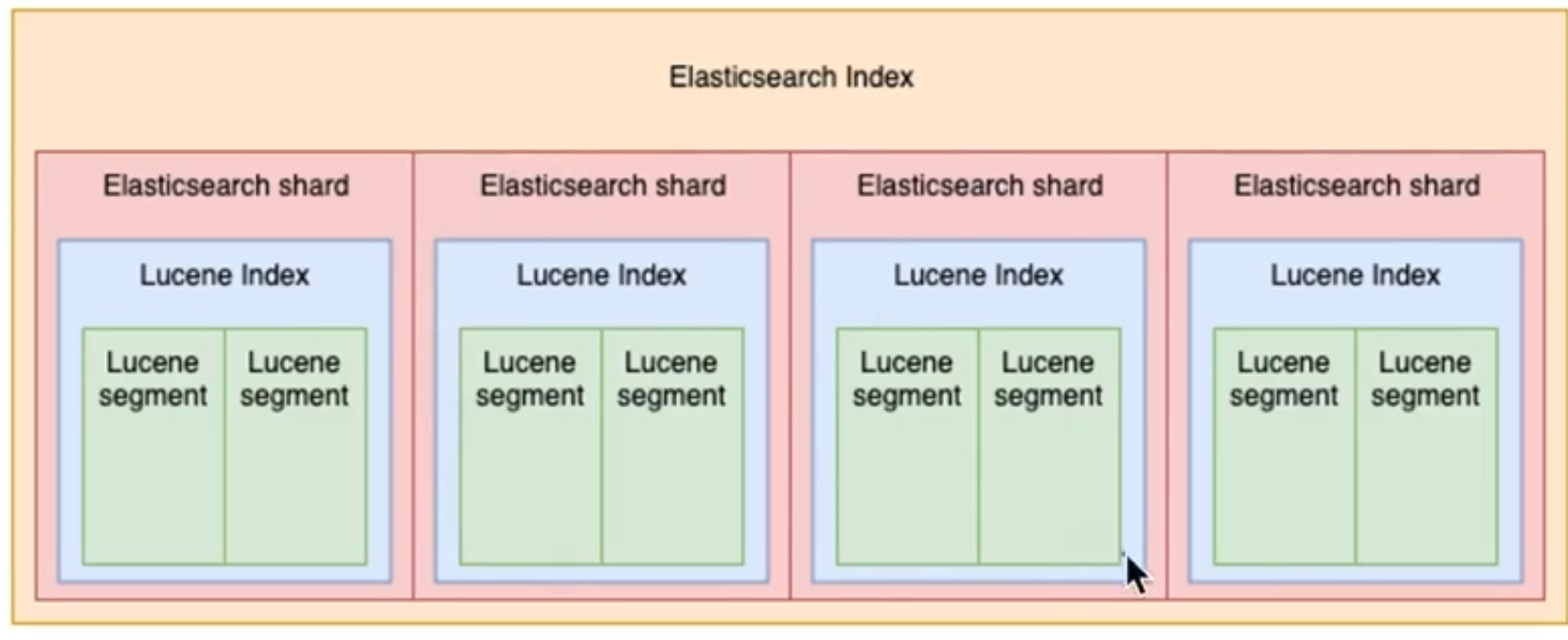
- 하나의 샤드 안에 하나의 "Lucene Index"를 가짐
- "Lucene Index"는 여러 개의 세그먼트를 포함
- 세그먼트는 인덱스가 물리적으로 저장되는 가장 작은 단위
- 한 번 만들어진 후에는 변경 불가능(immutable)
- 수정을 하려면 lock을 걸어야 하는데, lock을 사용하면 검색 성능이 떨어짐
- lock을 사용하지 않기 위해 수정 방식을 사용하지 않음
- 세그먼트를 수정하지 않고, 수정 사항이 반영된 새로운 세그먼트를 생성하는 방법 사용
- https://lucene.apache.org/core/9_4_2/index.html
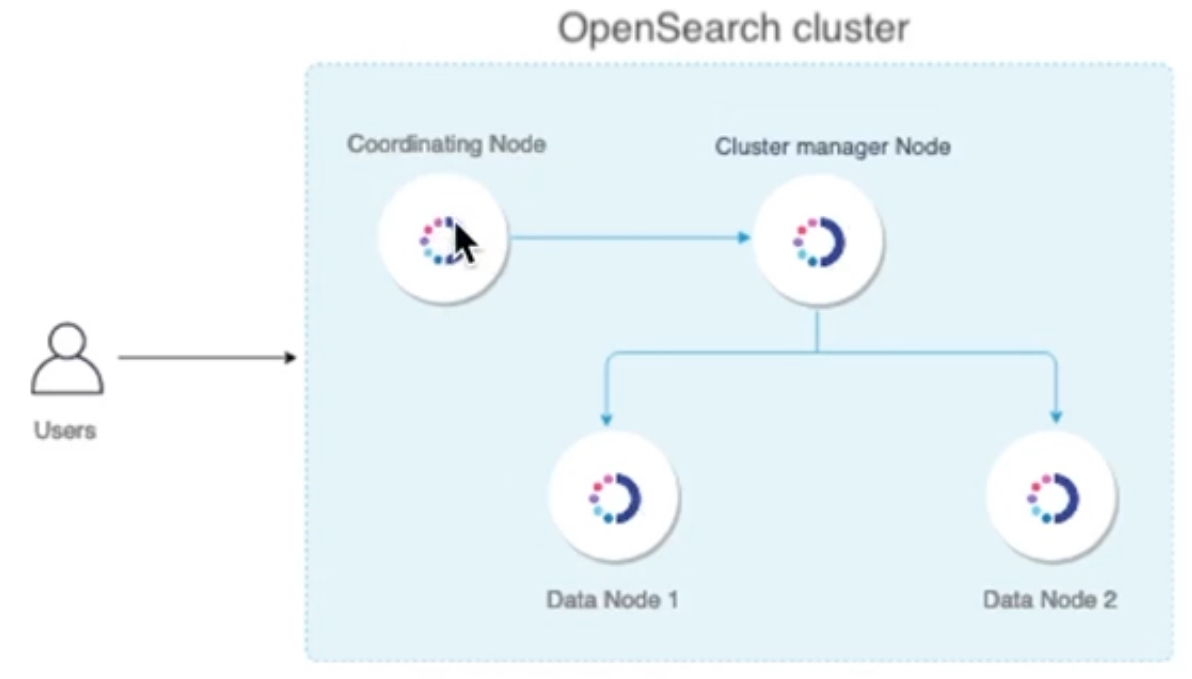
노드 타입과 역할
- 모든 노드는 어떤 타입도 될 수 있음
- 전용 노드: 설정 파일에서 노드 타입을 지정하면, 하나의 역할만 수행 가능
클러스터 매니저 노드 (Cluster Manager Node)
- 클러스터는 반드시 하나의 매니저 노드를 가짐
- 노드에 샤드를 할당하는 역할 수행
- 어떤 노드에 어떤 샤드가 있는지를 알 수 있음
- 클러스터 상태 정보(클러스터 설정, 인덱스 설정, 물리적 위치), 노드 상태 등을 포함
- 매니저 노드는 ping을 이용해 노드 상태를 확인
클러스터 매니저 후보 노드(Cluster Manager eligible Node)
- 매니저 노드가 죽거나 매니저 노드가 선정되지 않은 경우, 후보 노드들이 선출 과정에 참여
- 매니저와 매니저 후보 노드를 합쳐 최소 3대 이상의 노드가 있어야 함
- 선출 과정
- 후보 노드끼리 서로 투표
- 과반수 득표를 얻은 노드가 매니저 노드가 됨
- 선출된 매니저 노드가 클러스터에서 이탈할 경우, 위 과정을 반복해 노드를 다시 선출
데이터 노드(Data Node)
- 모든 데이터 관련 작업(인덱싱, 검색, 집계)을 담당
- 실질적인 데이터 처리를 담당하기 때문에 부하가 가장 큰 노드 타입
- 다른 타입의 노드보다 더 많은 컴퓨터 리소스를 사용
- 부하 상태를 체크하는 것이 중요
- 클러스터를 구성할 때 매니저 노드와 데이터 노드는 별도로 구성하는 것이 좋음
인제스트 노드(Ingest Node)
- 인제스트 파이프라인을 실행하는 역할
- 도큐먼트를 인덱싱하기 전 도큐먼트를 전처리하는 역할
- 데이터 노드의 역할을 분산시켜주기 때문에 인제스트 노드를 이용해 전처리하는 것이 효율적
- CPU 자원을 사용
코디네이터 노드(Codinator Node)
- 외부 클라이언트로부터 http 요청을 받아서 처리해주는 역할
레플리카 샤드
샤드를 복제하는 이유
- 하나의 노드가 죽었을 때 가용성을 높이기 위해 다른 노드에 복제본을 저장해놓는 것
- primary 샤드와 다른 노드에 저장해야 함
- 백업 용도 이외에도 read 요청에 대해 부하 분산이 가능함 (load balance 역할)
- 완전한 병렬처리는 불가능
- 부하를 분산하여 노드들에 대해 성능을 고르게 나오도록 할 수 있음
- 인덱스를 생성할 때 정의됨
샤드 동기화
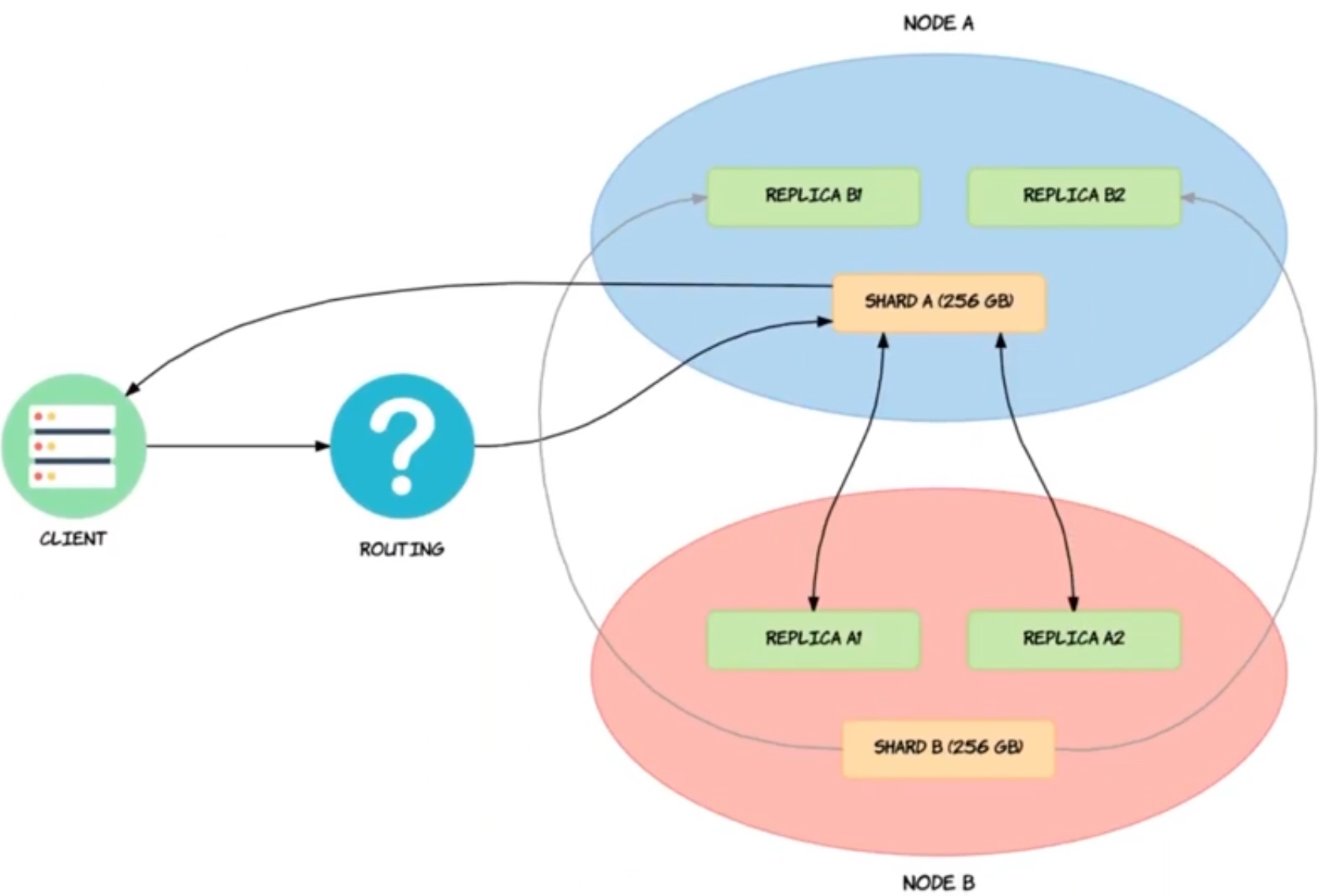
- read 요청에 대해 load balance 역할을 수행하기 위해서는 동기화가 필요
- request는 routing 로직을 통해 primary 샤드로 전달
- 동작
- primary 샤드는 요청이 유효한지 검증
- primary 샤드에서 작업 진행
- 레플리카 샤드에 대해 동기화 요청
- in-sync replica 샤드에 등록
- 장애
- primary 샤드 : 클러스터 매니저가 레플리카 샤드를 primary 샤드로 승격
- node : node의 상태를 알 수 없기 때문에 레플리카 샤드를 primary 샤드로 승격
- replica 샤드 : in-sync replica 샤드에서 제거함
클러스터 시각화
json 요청을 텍스트로 확인하는 것은 한계가 있기 때문에 시각화를 이용
클러스터 시각화 클라이언트
Elasticvue는 다음과 같은 기능을 제공하는 Opensearch 클라이언트
- 클러스터, 노드, 샤드 상태 확인
- 인덱스 관리
- REST API 인터페이스
- 스냅샷 관리
크롬 확장 프로그램으로 쉽게 설치가 가능하고, 복잡한 환경 설정이 필요 없다는 장점
설치 링크
public IP를 사용해 성공적으로 연결하면 위와 같은 메세지가 출력
멀티 노드 클러스터 구성
- 여러 대의 EC2 인스턴스 위에 Opensearch 인스터스를 설치하여 멀티 노드 클러스터를 구
성 - AWS의 AMI를 사용하면 Opensearch가 미리 설치된 EC2 인스턴스를 시작 가능
AMI 생성
# opensearch 설치
$ cd /home/ubuntu
$ sudo apt update
$ sudo apt install build-essential -y
$ wget https://artifacts.opensearch.org/releases/bundle/opensearch/2.4.0/opensearch-2.4.0-linux-x64.tar.gz
$ tar -xvf opensearch-2.4.0-linux-x64.tar.gz
$ echo 'export OPENSEARCH_HOME=/home/ubuntu/opensearch-2.4.0' >> ~/.bashrc
$ source ~/.bashrc
$ sudo swapoff -a
$ sudo vi /etc/sysctl.conf
vm.max_map_count=262144
$ sudo sysctl -p # Reload
$ cat /proc/sys/vm/max_map_count # 변경값 확인
# systemctl 등록
$ sudo vi /etc/systemd/system/opensearch.service
[Unit]
Description=OpenSearch
Wants=network-online.target
After=network-online.target
[Service]
Type=forking
RuntimeDirectory=data
WorkingDirectory=/home/ubuntu/opensearch-2.4.0
ExecStart=/home/ubuntu/opensearch-2.4.0/bin/opensearch -d
User=ubuntu
Group=ubuntu
StandardOutput=journal
StandardError=inherit
LimitNOFILE=65535
LimitNPROC=4096
LimitAS=infinity
LimitFSIZE=infinity
TimeoutStopSec=0
KillSignal=SIGTERM
KillMode=process
SendSIGKILL=no
SuccessExitStatus=143
TimeoutStartSec=75
[Install]
WantedBy=multi-user.target
$ sudo systemctl daemon-reload
$ sudo systemctl enable opensearch.serviceAMI(이미지) 생성: 인스턴스 > 작업 > 이미지 및 템플릿 > 이미지 생성
이미지로부터 인스턴스 생성: 이미지 > AMI > AMI로 인스턴스 시작
- 하나의 매니저 노드, 2개의 데이터 노드, 1개의 코디네이터 노드를 생성
- t2.medium으로 설정
manager node 설정
ssh를 통해 접속한 후
$ vi $OPENSEARCH_HOME/config/opensearch.yml
plugins.security.disabled: true
cluster.name: opensearch-cluster
node.name: opensearch-cluster_manager
node.roles: [ cluster_manager ]
network.host: 0.0.0.0
discovery.seed_hosts: [0.0.0.0]
cluster.initial_cluster_manager_nodes: ["opensearch-cluster_manager"]
$ sudo systemctl restart opensearch.service- cluster.name: 클러스터 이름
- 클러스터 이름을 설정하지 않으면 opensearch라는 이름의 클러스터가 생성
- 프로덕션 환경에서는 클러스터 이름을 지정하는 것이 좋음
- node.name: 노드 이름, 논리적 이름
- node.roles: 노드 타입
- network.host: 노드의 IP 주소
- discovery.seed_hosts: 클러스터에 속한 클러스터 매니저 또는 후보 노드의 IP주소 목록
- 노드가 처음 실행될 때 discovery.seed_hosts에 설정된 IP주소로 클러스터 매니저 또는 후보 노드를 탐색
- 디스커버리: 탐색한 노드를 클러스터로 바인딩하는 과정
- IP주소로 노드를 찾았을 때, 클러스터 이름이 일치하지 않거나 탐색한 노드가 클러스터 매니저 또는 후보 노드가 아니라면 다른 IP주소로 디스커버리 과정 반복
- 노드가 처음 실행될 때 discovery.seed_hosts에 설정된 IP주소로 클러스터 매니저 또는 후보 노드를 탐색
data node1
$ vi $OPENSEARCH_HOME/config/opensearch.yml
plugins.security.disabled: true
cluster.name: opensearch-cluster
node.name: opensearch-d1
node.roles: [ data, ingest ]
network.host: 0.0.0.0
discovery.seed_hosts: [$manager-public-ip]
$ sudo systemctl restart opensearch.serviceelasticvue를 확인하면 data node가 하나 증가한 것을 확인할 수 있다
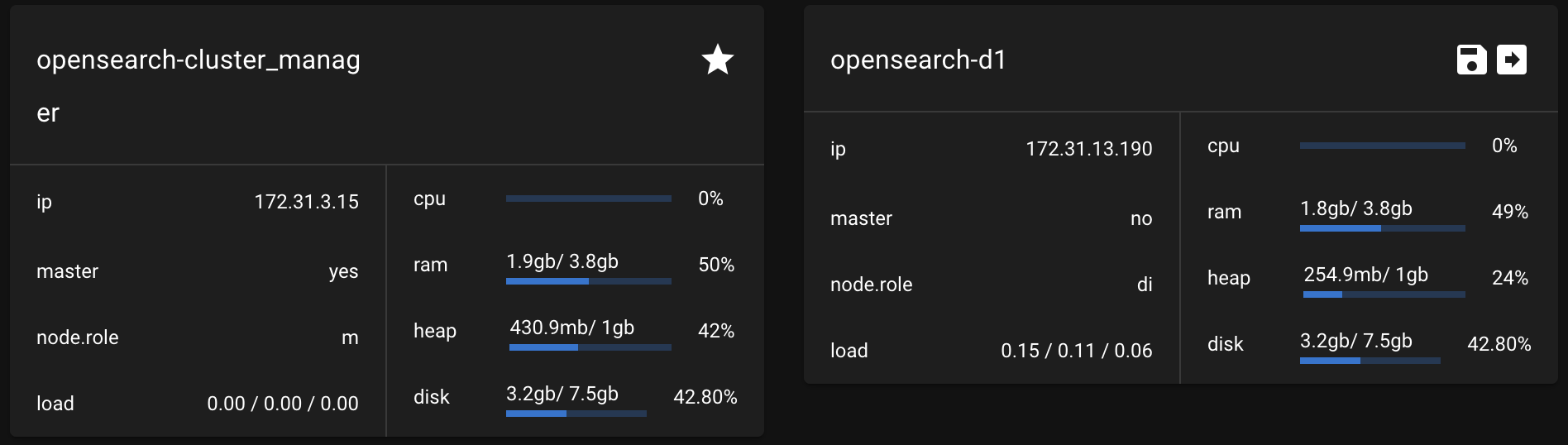
data node2
$ vi $OPENSEARCH_HOME/config/opensearch.yml
plugins.security.disabled: true
cluster.name: opensearch-cluster
node.name: opensearch-d2
node.roles: [ data, ingest ]
network.host: 0.0.0.0
discovery.seed_hosts: [$manager-public-ip]
$ sudo systemctl restart opensearch.servicecoordinator node
$ vi $OPENSEARCH_HOME/config/opensearch.yml
plugins.security.disabled: true
cluster.name: opensearch-cluster
node.name: opensearch-d2
node.roles: [] # 비어있는 경우 cordinator node
network.host: 0.0.0.0
discovery.seed_hosts: [$manager-public-ip]
$ sudo systemctl restart opensearch.service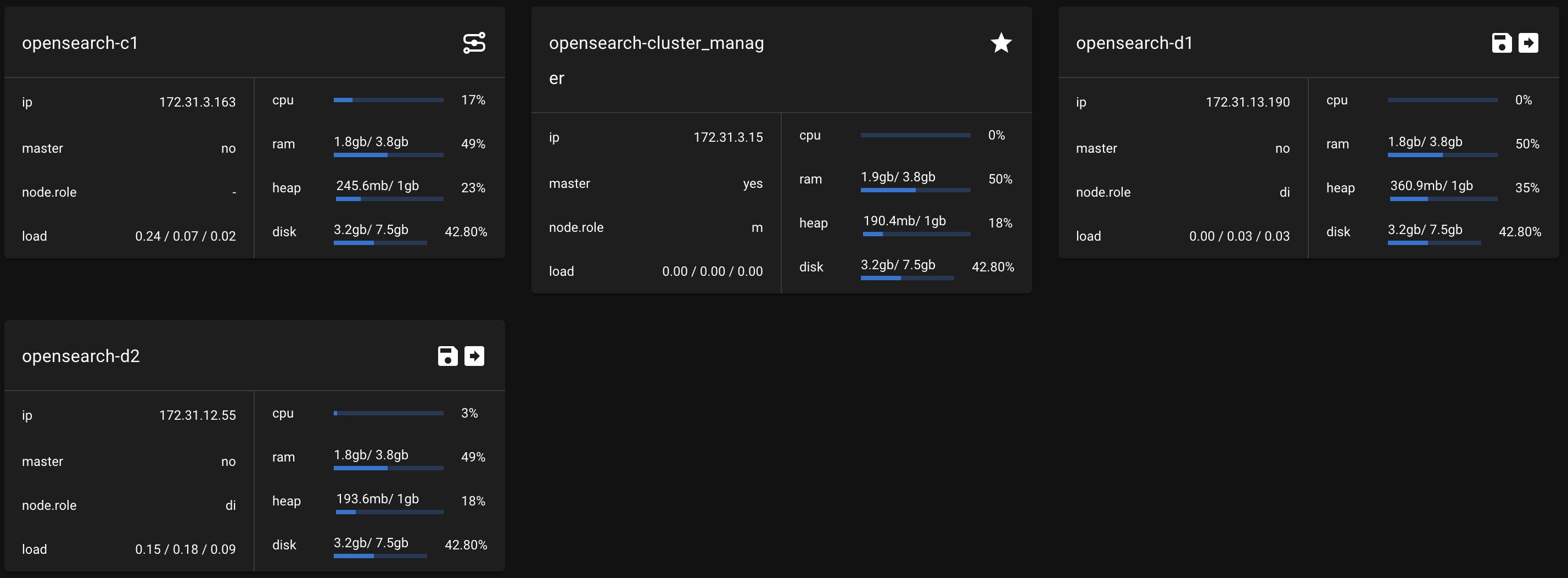
클러스터 매니저 노드 재선출
sudo systemctl stop opensearch.servicemanager 노드에 접속하여 매니저 노드를 중지

- elasticvue를 들어가면 모든 노드에 접속이 불가능한 상태인 것을 확인할 수 있음
-manager 노드의 IP만이 주어졌기 때문에
elasticvue에 coordinator 노드의 IP 주소를 주어도 클러스터 전체 정보를 확인할 수 없음
→ cluster 정보는 manager 노드만 갖고 있기 때문에
data node에 cluster_manager 역할을 주는 경우?
plugins.security.disabled: true
cluster.name: opensearch-cluster
node.name: opensearch-d2
node.roles: [ data, ingest, cluster_manager ] // cluster_manager 역할을 줌
network.host: 0.0.0.0
discovery.seed_hosts: [$cluster_managerIP]data node에 cluster_manager 역할을 주더라도 coordinator는 전체 클러스터 구조를 알 수 없음
→ 여전히 seed_hosts로 manager node의 IP주소를 보고 있기 때문에
manager node에서 seed_host 설정
seed_host를 data node2의 IP 주소로 설정
plugins.security.disabled: true
cluster.name: opensearch-cluster
node.name: opensearch-cluster_manager
node.roles: [ cluster_manager ]
network.host: 0.0.0.0
discovery.seed_hosts: [43.202.53.111] # seed host를 data node2로 설정
cluster.initial_cluster_manager_nodes: ["opensearch-d2"] # initial cluster manager를 data2 node로 설정data node1과 2에 cluster_manager를 할당
data node1
plugins.security.disabled: true
cluster.name: opensearch-cluster
node.name: opensearch-d1
node.roles: [ data, ingest, cluster_manager ]
network.host: 0.0.0.0
discovery.seed_hosts: ["$cluster_managerIP"]data node2
plugins.security.disabled: true
cluster.name: opensearch-cluster
node.name: opensearch-d2
node.roles: [ data, ingest, cluster_manager ]
network.host: 0.0.0.0
discovery.seed_hosts: ["3.34.49.212"]- cluster manager 노드가 정지되었을 때, data node2에만 cluster manager 역할이 부여되어 있으면 투표를 받지 못하기 때문에 cluster manager node로 승격되지 않음
- data node1에도 cluster_manager 역할을 주면 투표로 data node2를 cluster manager node로 사용 가능
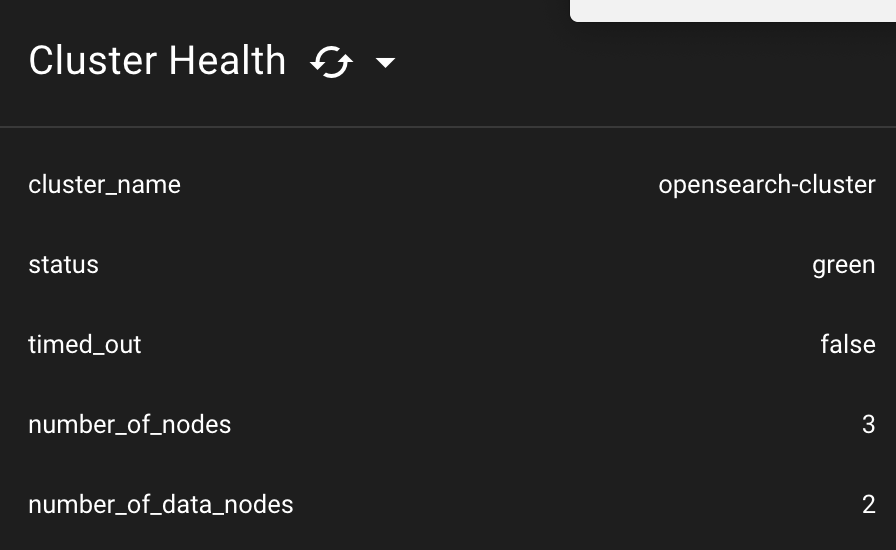
→ cluster manager node가 죽어도 coordinator node로 정상적으로 cluster에 접근이 가능
voting_only
- Elasticsearch에서 투표 전용 노드를 만들고 싶을 때는 voting_only를 사용 가능
- voting_only는 투표만 가능하고 cluster_manager가 될 수는 없음
- Opensearch에서는 아직 이 기능이 update되지 않음 → ?
node.roles: [ cluster_manager, voting_only ]Ingest node 파이프라인 설정
- opensearch cluster에서 데이터가 들어올 때 전처리를 수행하는 노드
- data node에서 전처리를 수행하면 조회, 저장 처리가 오래 걸릴 수 있음
- data를 bulk로 밀어넣을 때 ingest node를 사용
curl -XPUT "$OPENSEARCH_REST_API/_ingest/pipeline/test-pipeline?pretty=true" \
-H "Content-Type: application/json" \
-d '
{
"processors": [
{
"set": {
"field": "field1",
"value": 10
}
},
{
"lowercase": {
"field": "field2"
}
}
]
'
스터디를 해보자