현재 AI 업계를 가장 큰 화두에 올린 장본인인 openAI의 chatGPT의 핵심적인 뇌 구조! 그 구조의 핵심이 되는 기본, Attention 과 Transformer 구조를 함께 공부해보자!
피드백은 언제나 환영입니다 :) 제가 잘못 안 게 있다면 언제든 알려주세요 !
Introduction & Abstract
저번에 공부했던 Seq2Seq 를 발전시킨 Attention 이라는 구조를 기본적으로 이해하고 들어가야 한다.
About 'Attention'
- Seq2Seq 은 단어의 사이즈가 클 때 문제가 생겼음!
- Seq 가 길어지면, 모든 정보를 함축하기에, context vector 가 부족하다는 것.
- Encoder 단에서의 충분한 정보가 없기 때문에, 기계번역이 어려워지는 경향
이전 Encoder 단에서 활용한 Context vector V는 마지막 LSTM 의 hidden state 값이었음!
--> 수학적으로는 모든 문맥 정보를 조금씩 함축하고 있어야 하기는 하나, 저번 seq2seq 리뷰 마지막에서 볼 수 있듯 실질적으로는 그렇지 못했음
: 그렇다면 모든 RNN cell 각각의 state들을 모두 활용하여, context vector 를 만들면 좋지 않을까?
고정된 사이즈의 문맥벡터 탈출 !
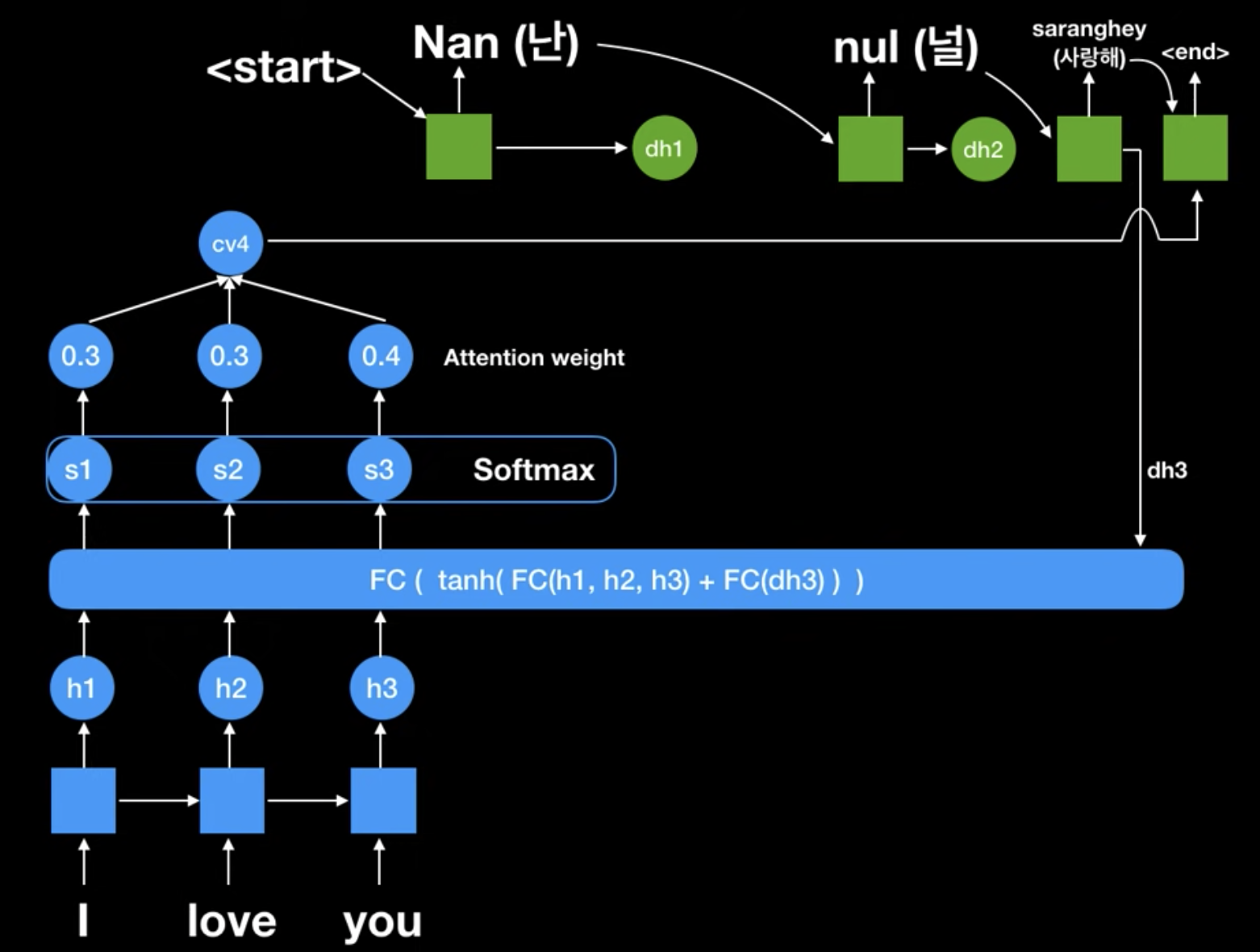
위 구조를 집중해서 봐보자!
Seq2Seq + Attention 구조를 활용해서
I love you -> 난 널 사랑해 로 기계번역 하는 과정이다.
이 구조를 어렵게 보지말고, 크게 두 가지에 집중해보자.
- Encoder 에서 hidden state 가 얼마나, 어떻게 넘어가고 있는지
- 못보던 층 구조는 무엇인지
1. Encoder 의 hidden states
- 일단 딱 봐도 원래 seq2seq 처럼 하나의 context vector 가 아니다!
- 각 RNN cell 에서 나오는 hidden state 값이 모두 FC layer 에 들어간다.
- sequence 전체의 state 값을 사용하여 task에 활용한다고 보면 되겠다.
2. FC + Softmax와 Attention weight
- FC layer 는 모든 seq 의 hidden state 값 + Decoder의 전 state 값을 받아 seq 별 score 를 계산한다.
- 이때 이 score 는 지금 문맥상으로, 어떤 seq의 hidden state에 보다 더 집중을 해야 하는지를 알 수 있게 해준다.
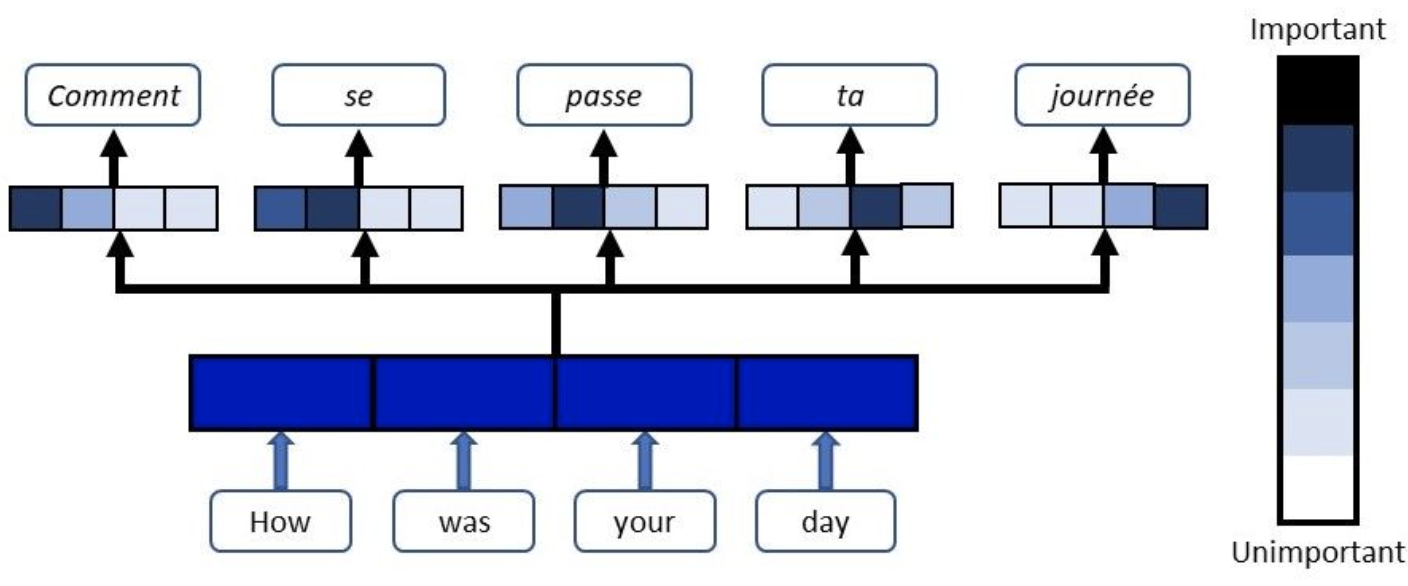
- Softmax 는 FC layer 의 값(score) 을 확률화 시켜주는 부분이다.
그리고 softmax 를 거져 나온 score 값이 바로, Attention weight이다!
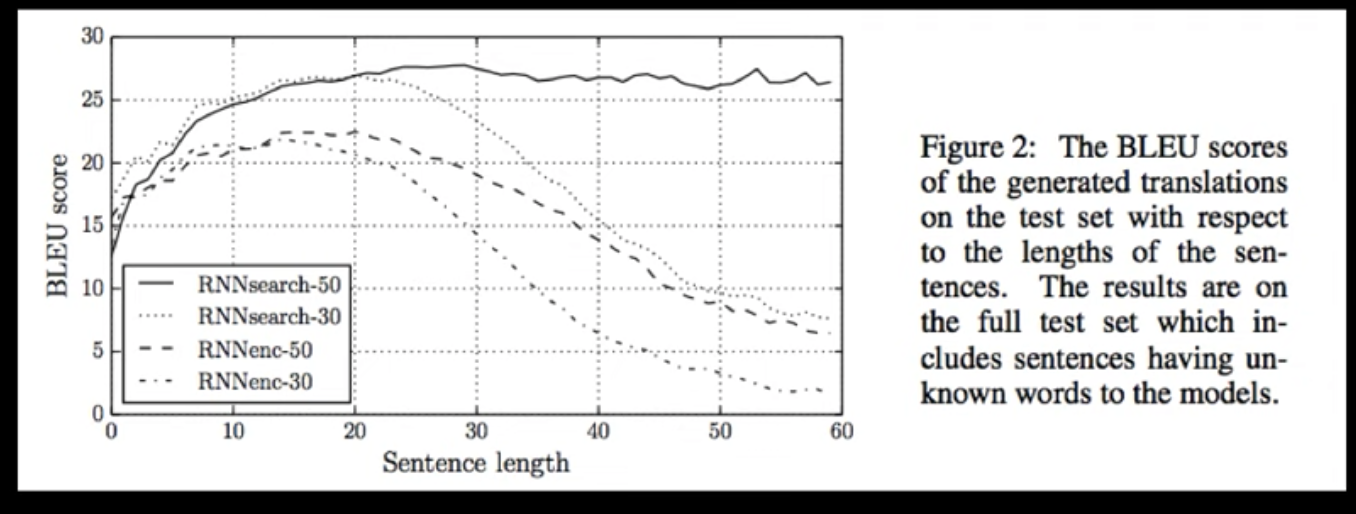
이를 통해 기존의 RNNenc (Seq2Seq 구조) 에서, RNNSearch (seq2seq + attn ) 으로의 비약적인 성능 향상을 이루어 냄
그런데, 아직도 RNN 을 순차적으로 돌아서 계산을 해나가야 하는 단점과 성능향상에서의 잠재력이 보였던 구조.
순환 신경망을 없애버리면 어떨까?
About Transformer
Transformer 는 sequencial data 를 다룰 때, Encoder - Decoder 구조를 그대로 가져가되 RNN 을 사용하지 않는다.
seq의 token 하나 당 하나의 셀에 들어가 계산을 하고 그 다음 token이 그 다음 계산을 하고 하는 과정을 획기적으로 간파한다.
지금부터 그 과정을 살펴보자.
Positional Embedding
RNN 을 사용했던 이유는 Sequencial 한 data 를 다룰 때 , 그 순서가 정말 중요하기 때문인데, RNN 을 사용하지 않고 그걸 어떻게 할까?
바로 positional embedding 이다.
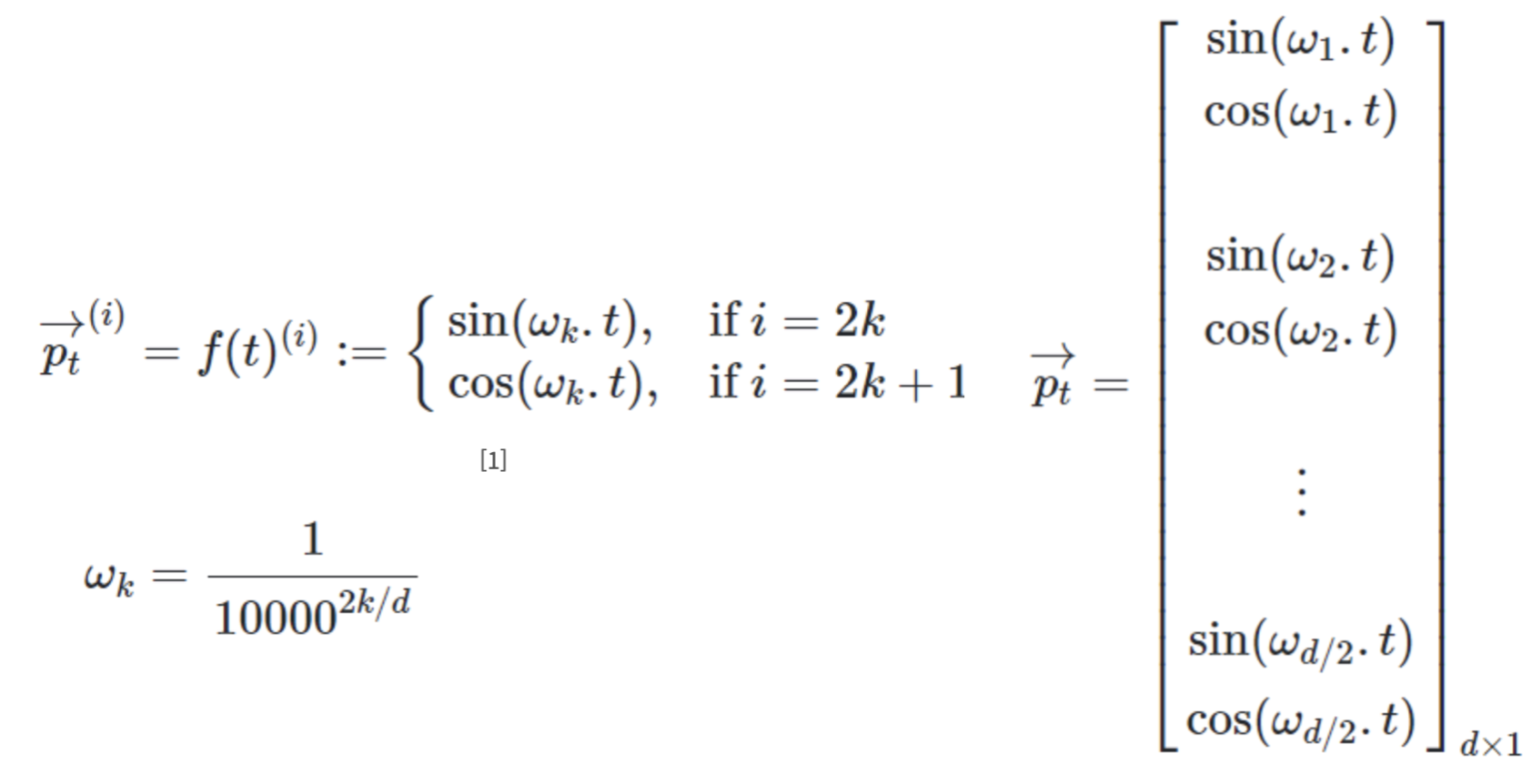
인코더 및 디코더의 입력값 마다 해당 값의 sequence 내 상대적인 위치를 인코딩해주는 것!
: 위 식을 보면 알 수 있듯이, t번째 값에 t번째 요소를 곱해주는 벡터의 형태
: 각 요소들은 w_k 값에 의해 각 좌표계 정의역에 linespace 하게 됨
이를 활용해 transformer 는 RNN 없이도, 해당 값의 문맥 내 위치정보를 더해줄 수 있다.
Self Attention
Transformer 에서 일어나는 Attention 연산은 바로 이 Self - Attention 이다. 한번 공부해보자.
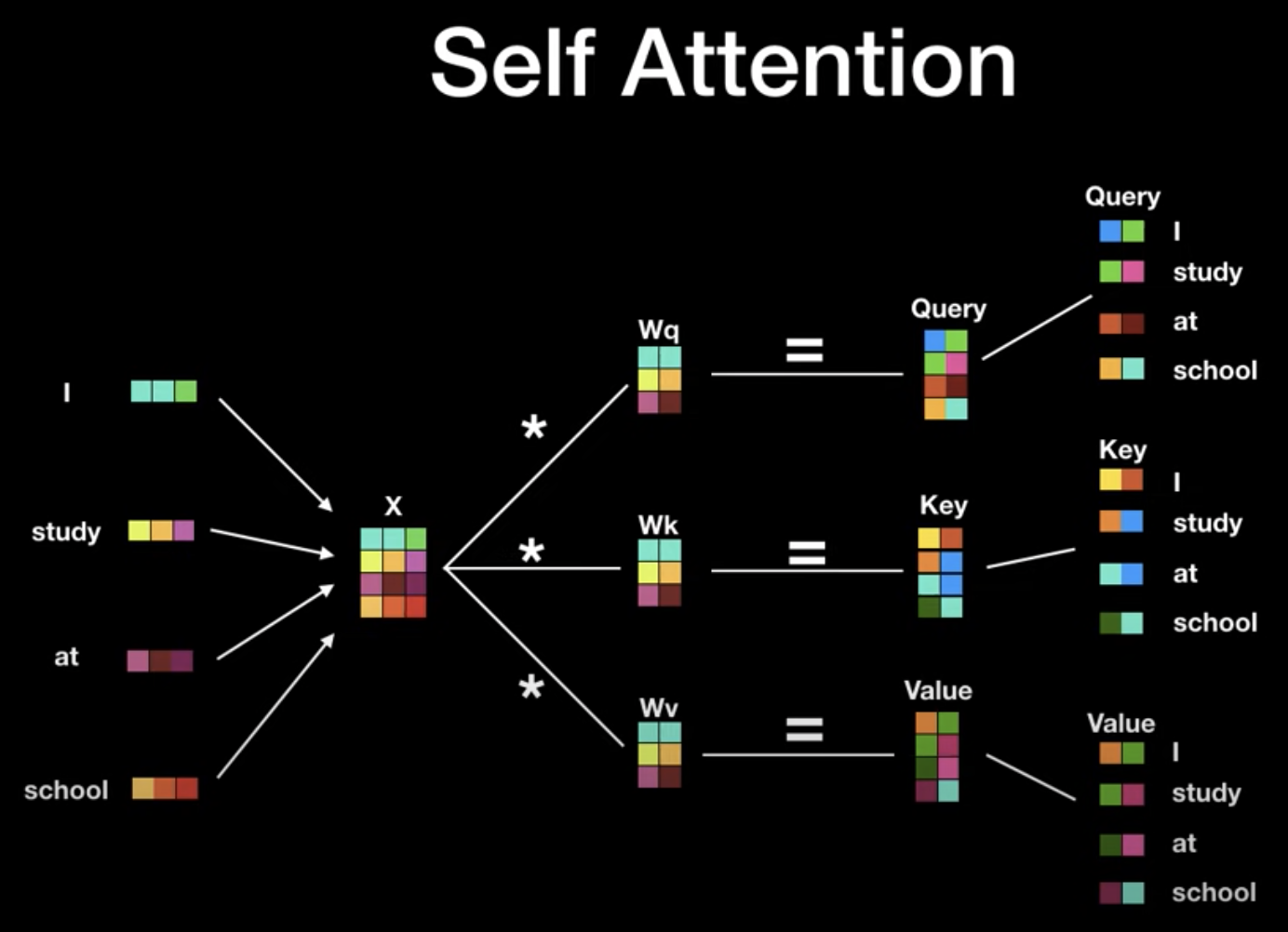
Self attention 은 위와 같이 Wq ,Wk , Wv 라는 weight matrix 를 학습하고 갱신하는 과정으로 Query,Key,Value(Q,K,V) 를 개선시키는 방식으로 진행된다.
- 각 값들에 대한 Q,K,V 가 벡터로 생성된다.
- 이 Q,K,V 는 Attention Score 를 구하는데 사용된다.
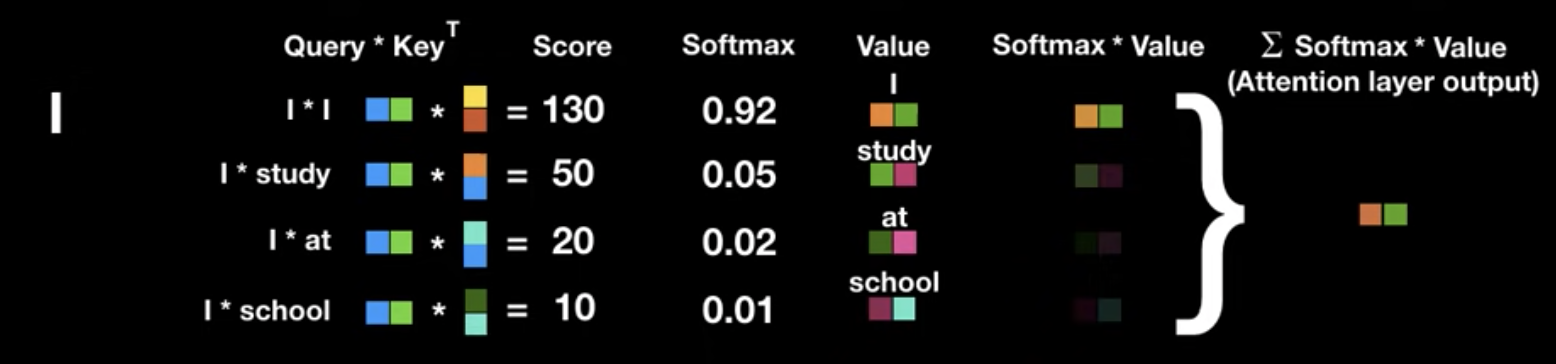
- Attention Score 란 해당 부분을 해석할 때, 얼마나 집중을 해야하는지를 보여주는 값! (잘 모르겠다면 위에 다시 ! )
- Query 와 Key 의 벡터곱으로 Attn score 산출하고 확률화 시킴
그리고 value 와 attn score 를 합성곱하여 최종 결과를 산출!
-> 위 계산 과정이 복잡해 보이지만, 행렬의 연산으로 생각하면, 정말 빠르다.
일어나는 연산은
DATA x Weight Matrix (Q,K,V)
Softmax( Query Mat x Key Mat ^ T ) x Value 의 SUM
그렇게 간단하게 표현하지도 않았는데 이게 끝이다.
RNN의 순차적이고 귀찮은 동적인 Attention 구조를 다음과 같이 병렬적인 연산으로 처리한 것이다.
Multi-head Attention
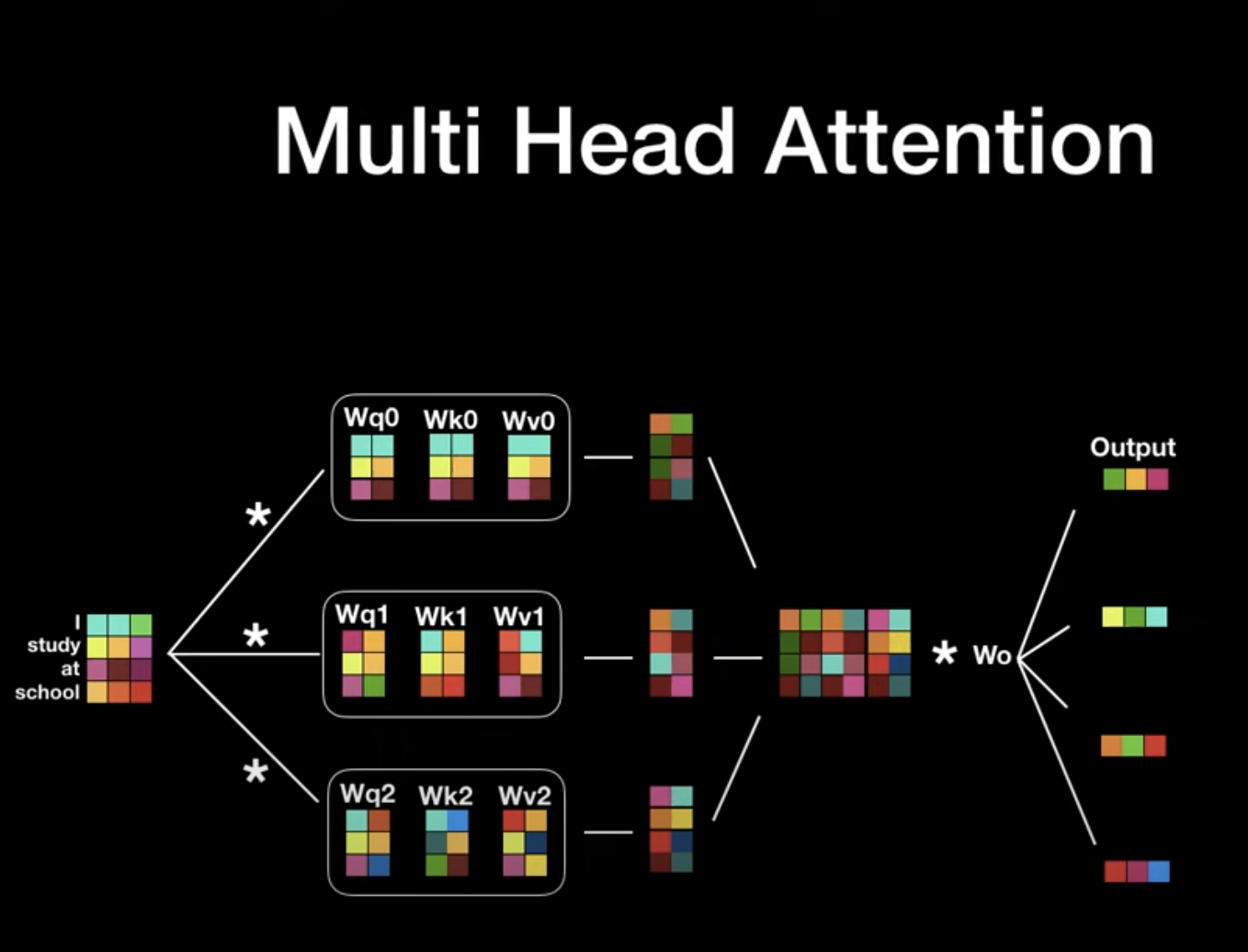
Multi-head Attention 은 transformer 내의 여러 self-attention 을 병렬적으로 활용함으로써, (논문에서는 8개를 활용) 문장의 모호함에 강건하게 대비할 수 있도록 함.
-> 여러가지 의견을 제시받는 것과 비슷한 느낌
Architecture - Encoder
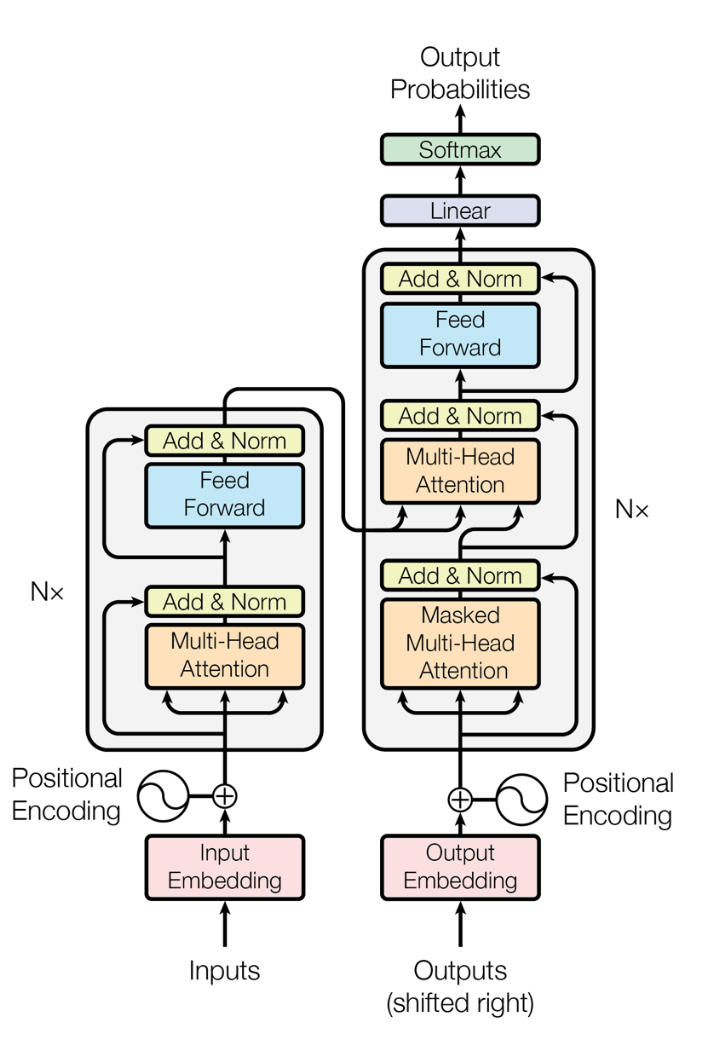
위 그림이 Transformer 의 Encoder - Decoder 구조이다!
일단 Encoder 부분만 보면 거의 다 우리가 배운 것들이다.
중간중간 Add 하고 정규화 하는 부분으로 넘어가는 화살표는, 아래와 같이 학습 시 역전파 과정에서 seq 내의 위치정보가 흐려지기 때문에 그걸 방지해주고자 Residual Connection 으로 Positional Embedding 값을 더해주는 부분이다.
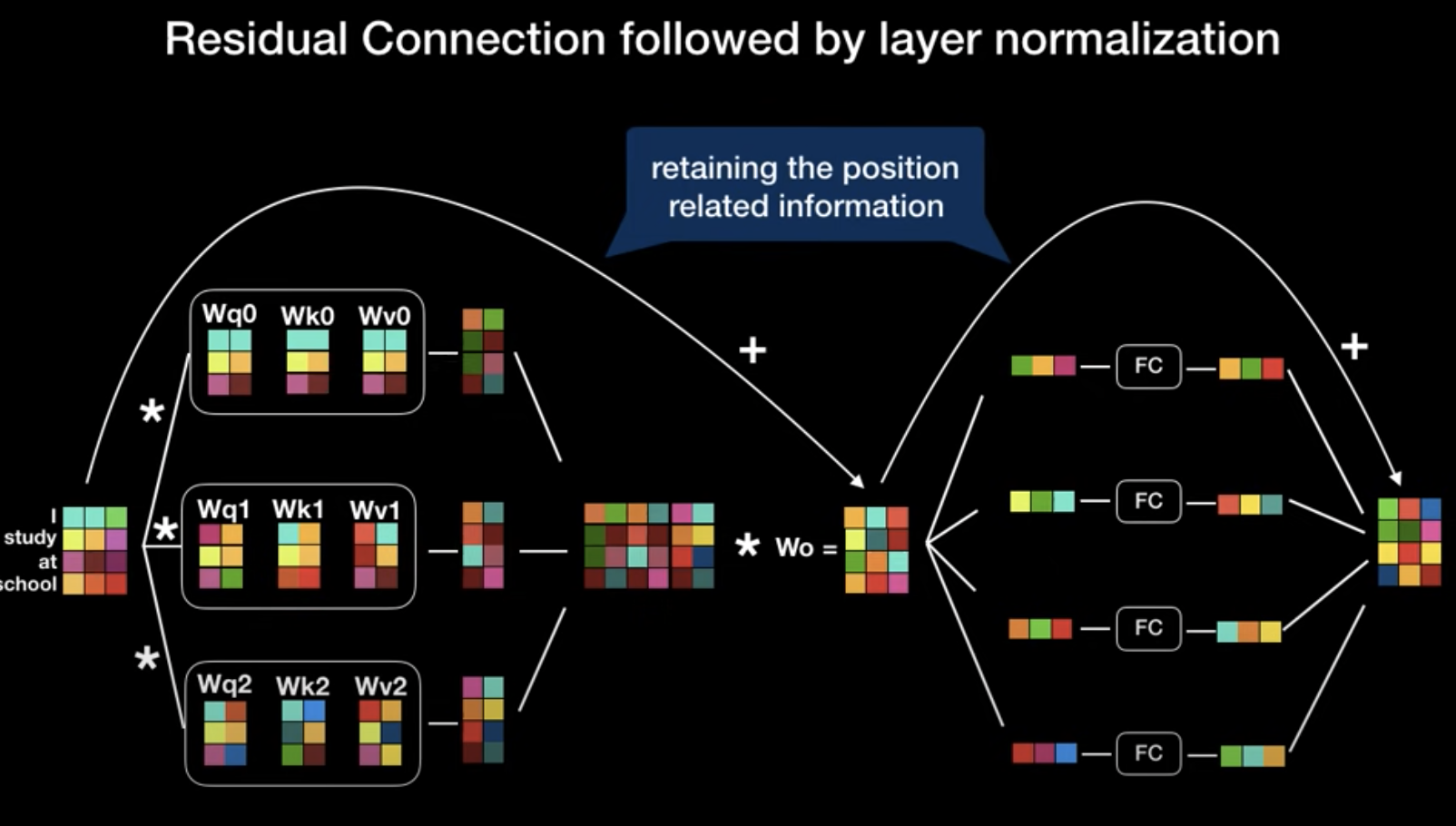
Transformer 의 Encoder 는 생각해보면 입출력 차원이 똑같다!
이 말은 무슨 말이냐하면,
Encoder 뒤에 바로 Encoder 를 붙여서 더 깊은 layer 를 쌓을수도 있다는 의미이다!
- 실제로 논문의 저자들은 Encoder Layer를 여섯층 쌓아서 나온 출력값을 Decoder 부분으로 넘겼다.
- 이때의 layer 들은 가중치를 공유하지 않고 따로 학습한다 (당연히!)
Architecture - Decoder
기본적인 Encoder Decoder 구조를 알고, self - Attn 메카니즘을 정확히 이해했다면 , Transformer 의 Decoder구조는 어렵지 않다.
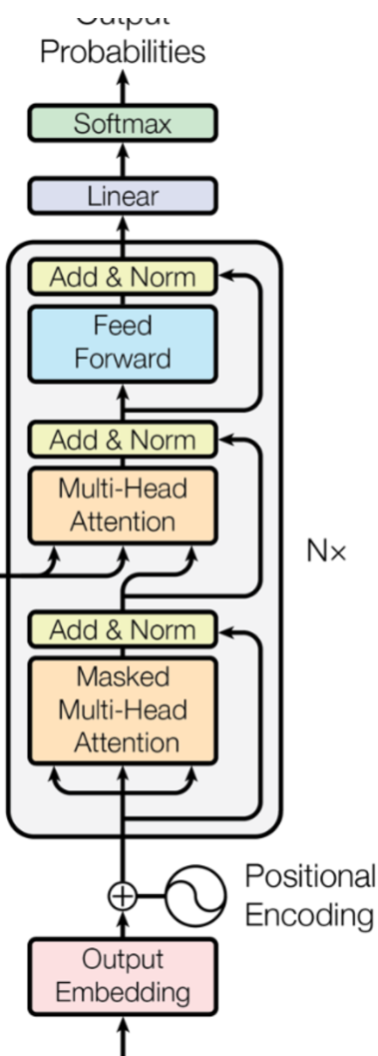
위 구조에서 보아야 할 것은 두개!
1. Masked Multi-Head Attention 이 무엇인가?
2. Decoder 부분의 Multi-head Attention 의 Q,k,v는 어디서 흘러들어오는가?
Masked Multi-Head Attention
- 디코더 부분에서 지금까지 출력된 값들에 대해서만 Attention 을 적용하기 위해 단어를 가려주는 Attention 방식
- 아직 출력되지 않은 미래의 값에 적용하지 않도록 함
2. Decoder 부분의 Multi-head Attention 의 Q,k,v는 어디서 흘러들어오는가?
- Query 로는 Decoder 의 입력값을 사용하나, Encoder의 최종 출력값을 Key 와 Value 로 받는다!
- 이 부분이 Seq2Seq의 Context Vector 의 역할을 톡톡히 해준다!
- Input 문장의 중요한 정보를 6 layered Attention Encoder 를 통해 key 와 value 의 형태로 넘어오게 된다.
- Sequence 전체의 흐름뿐만 아니라 부분마다 smoothing 되어 나타나는 해석 중요도 의미값들을 사용할 수 있다는 것 (덧셈으로 최종 결과값들이 추출되기 때문!)
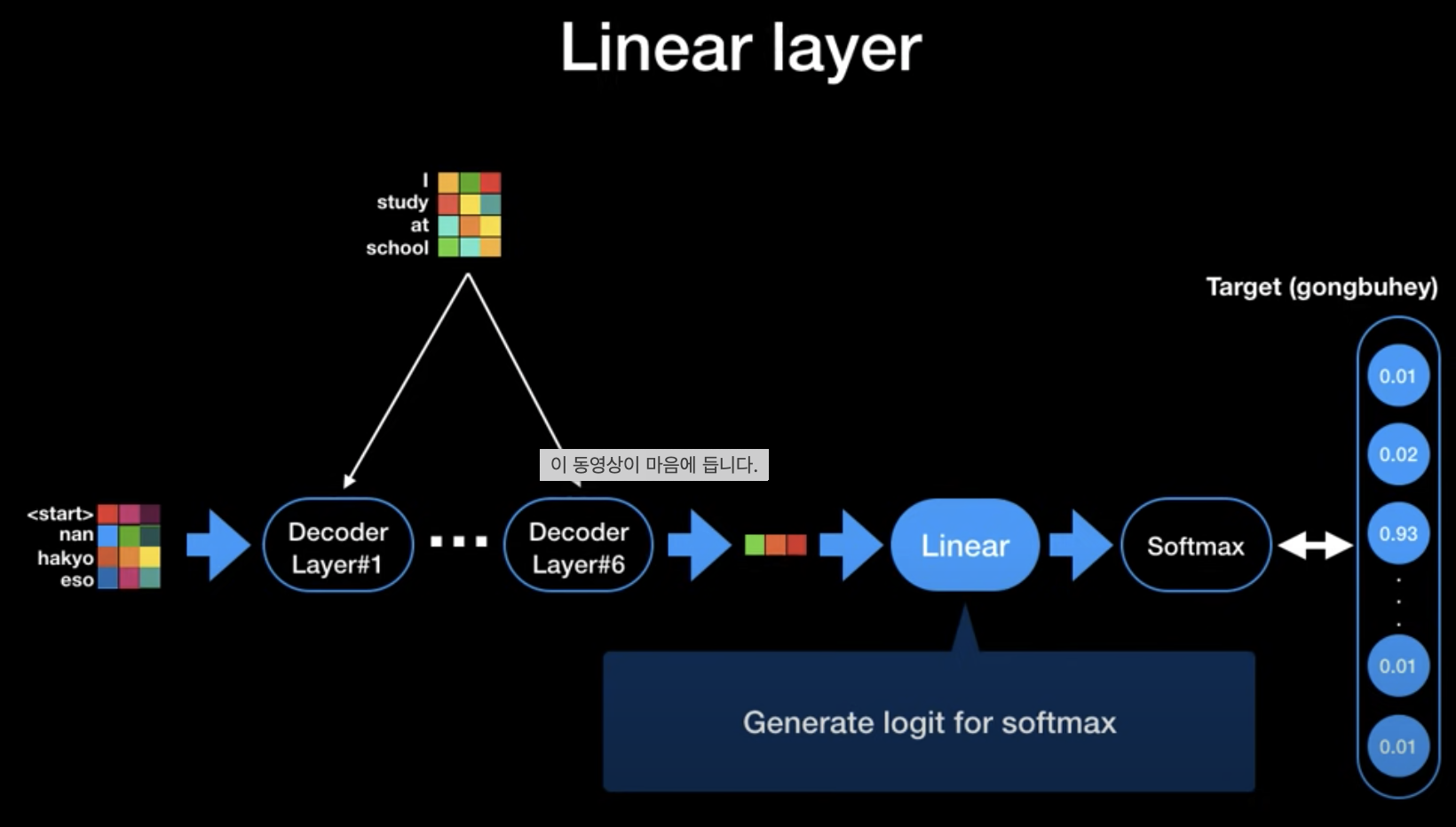
-> 디코더의 경우에도 입출력 차원이 같아 논문의 저자들은 6개를 쌓았다.
추가적으로 저자들은 Label Smoothing 이라는 기법을 활용하는데, 그것은 바로 Target 값이 Softmax 이후에 0,1 의 one-hot 이 아니라 0.1 , 0.8 , ... 등의 0과 1에 가까운 값으로 표현되게 하는 것이다.
이건 답이 명확한 데이터일때는 오히려 성능 감소를 불러올 수 있지만, 더럽고 불명확한 데이터 일 때에는 outlier 나 어려운 문제에 대응할 때 애매한 대답을 내놓음으로써 성능 향상을 크게 일으킨다고 한다.
outro
개어려웠다.
References
https://blog.floydhub.com/attention-mechanism/
https://ratsgo.github.io/nlpbook/docs/language_model/tr_self_attention/
