최근 세간을 뜨겁게 달군 chat-GPT
그것의 전신이라고 볼 수 있는 GPT 1을 함께 공부해봅시다!
main idea라고 생각되는 semi-supervised Learning 을 예시를 통해서 설명하자면 다음과 같은 느낌입니다.
내가 아들을 하나 낳아서 그 아들을 성직자로 키우고 싶다.
인륜적인 생각을 벗어나서, 거의 100프로의 확률로 아들을 성직자로 키우는 방법은 무엇일까?
바로 교회에서 가둬 키우는 것이다.
그러나 교회에 가두면, 좋은 성직자가 될 수 없다. 세상을 모르기 때문이다.
그렇기 때문에 성직자뿐만 아니라 많은 사람들이 있는 세상에서 아이를 어느정도 키우고, 그 다음 쥐도새도 모르게 납치를 해서 교회에서 감금을 시켜 아이를 키우면, 그 아이는 성직자가 될 확률이 높다.
좀 무섭고 섬뜩한 예시이지만 GPT를 이해하는데에 도움이 될 것 같은 예시입니다.
Abstract
NLP 는 다양한 Task 존재, 그에 반해 Labeled data 는 별로 없음.
Unlabeled data 는 진짜 엄청나게 많고 지금도 생성되고 있음.
Simple Examples of Labeled VS. Unlabeled in NLP
Labeled Data 예시:*
->각 이메일이 "스팸" 또는 "비스팸"으로 레이블링된 데이터Unlabeled Data 예시:
->대량의 웹 기사 텍스트 데이터, 그러나 어떤 기사가 어떤 주제에 속하는지에 대한 레이블이 없는 데이터
=> 다양한 Task 에 공통적으로 필요한 "understanding" 은 해결가능
=> 특정 task 에 대한 것은..?
- Unlabeled data Corpus들을 활용한 Generative Pre-Training
- discriminative Fine-Tuning 을 통해 다양한 task를 대할 때 큰 구조의 변화가 없도록 함
Introduction
일단, NLP task 에서는 전반적으로, 수많은 labeled data 들이 필요함.
unlabeled data 에서 언어적인 정보들을 활용해서 학습하는 모델이 있다면 참 좋을텐데.. (굳이 data 를 라벨링 해주지 않아도 되니까)
예를 들어, Pre-trained 된 word - embedding 값을 가지고 NLP task 에 적용시켜 성능향상을 이끌어 낸 연구가 존재.
-> 근데 지금의 걸로는 문제가 있음
1.
it is unclear what type of optimization objectives are most effective at learning text representations that are useful for transfer
단순히 unlabeled data 만을 사용하면 어떠한 목적함수가 transfer task에 효과적인지 잘 모른다
2.
there is no consensus on the most effective way to transfer these learned representations to the target task
target task 가 주어졌을 때, 각각의 task 에 대해서 어떻게 transfer 해야 효과적일지도 잘 모른다.
(여기서 transfer 는 전이학습을 의미)
다시 말해, 어떤 목표를 향해 모델을 학습시켜야 텍스트 표현이 특정 작업에서 효과적으로 전이될 수 있는지에 대한 이해가 부족하다는 것
이러한 모호함이 현 연구의 문제점
그래서 본 저자는 Semi-supervised Learning 을 제안함.
Semi-Supervised Learning
=> Unsupervised Pre-training + Supervised Fine-Tuning
=> 그래서, 막대한 양의 Unlabeled data 를 활용해서 pre-trained model을 만들고,
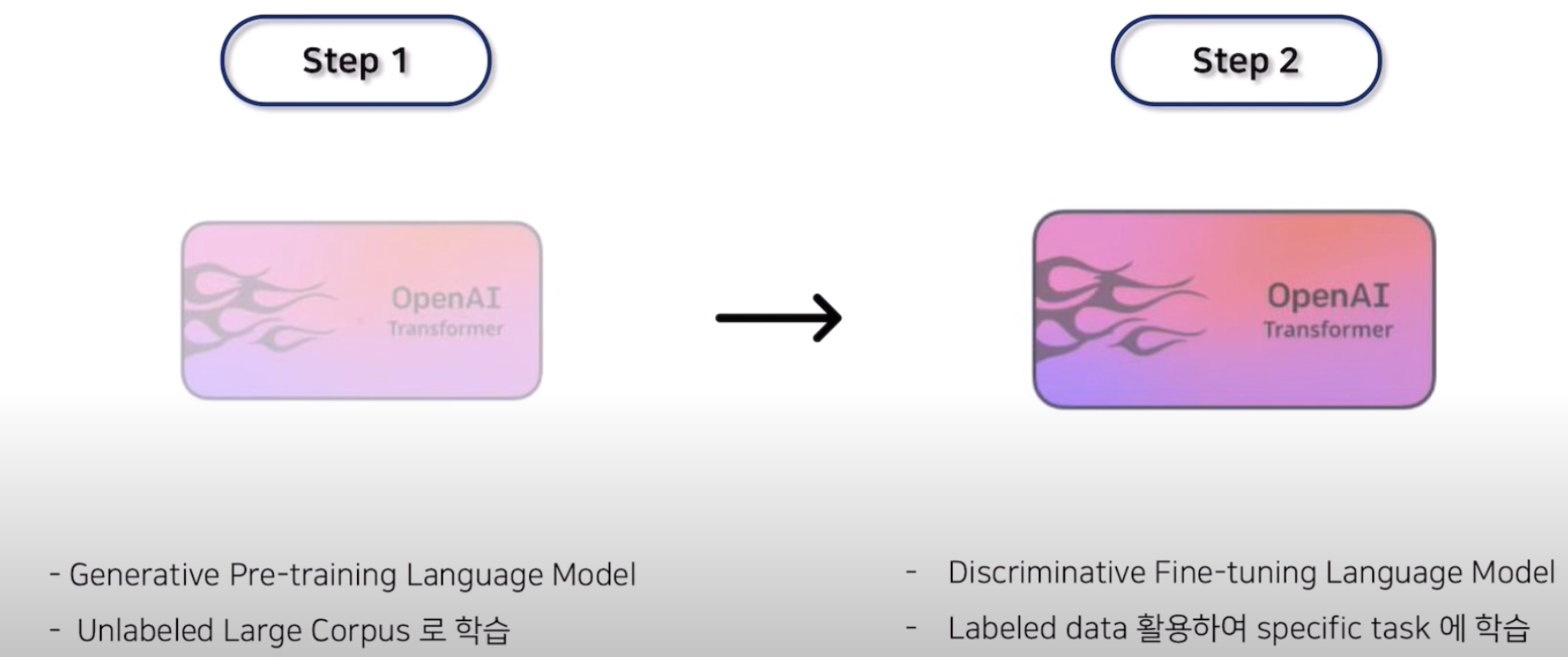
비지도 학습을 통해 PT 하고, 지도 학습으로 Fine Tuning을 하는 방법론
-> DownStream Task
Framework
Unsupervised Pre-Training
일단은 전이학습을 위해 Pre-training 을 하는 부분을 알아보자.
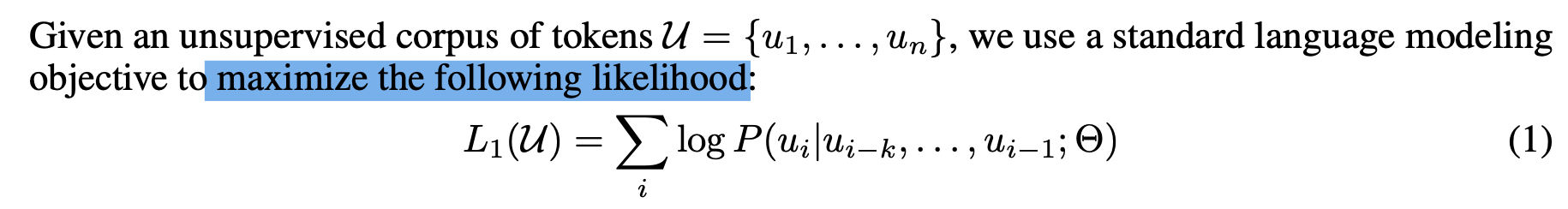
학습은 여타 Language Model 들 처럼 위 Likelihood function 의 값을 최대화 하는 방향으로 진행.
-> 현재 i 번째 sequence 전의 값들이 모두 주어졌을 때, 현재 i 번째 값이 나올 값의 확률 최대화
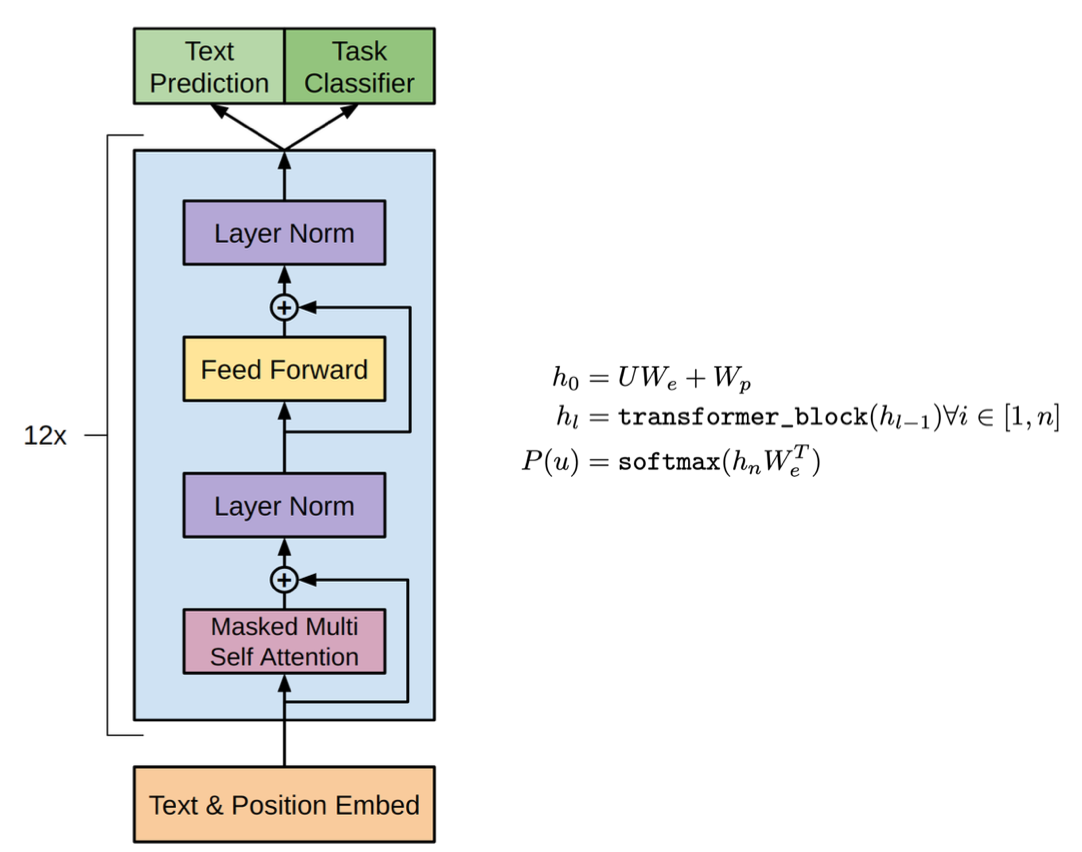
-구조는 간단하다!
- input sequence 를 받아 word embedding , Positional embedding 수행
- 이때 h_0 가 위와 같이 표현됨
- 그 다음부터 hidden state 를 decoder 블락에 계속 넣어 학습시킴
- 논문에서는 decoder block 이 12개
- 마지막에 최종 hidden state 값을 활용하여 확률값 출력
여기서 transformer 구조의 decoder 를 사용한 이유는 무엇일까?
현 논문의 저자들은 위에서 언급했듯, Pre-training 을 통해 'understanding'의 개념을 달성하고자 했다.
GPT 의 model 이 NLG(자연어 생성) 이나 NLM(자연어 모델링) 에 초점 맞춰져 있기 때문에 seq2seq 의 encoder-decoder 구조에서, 문맥벡터를 활용해 다른 시퀀스를 생성하는 decoder 구조만을 사용한 것이다.
(사실상 문맥벡터를 활용하는 encoder 값을 활용한 multi-head attention 부분도 없다.)
Supervised Fine-tuning
이 부분은 이제 labeled data 를 사용하여 target task 에 맞게 model 을 fine tuning 시키는 과정이다.
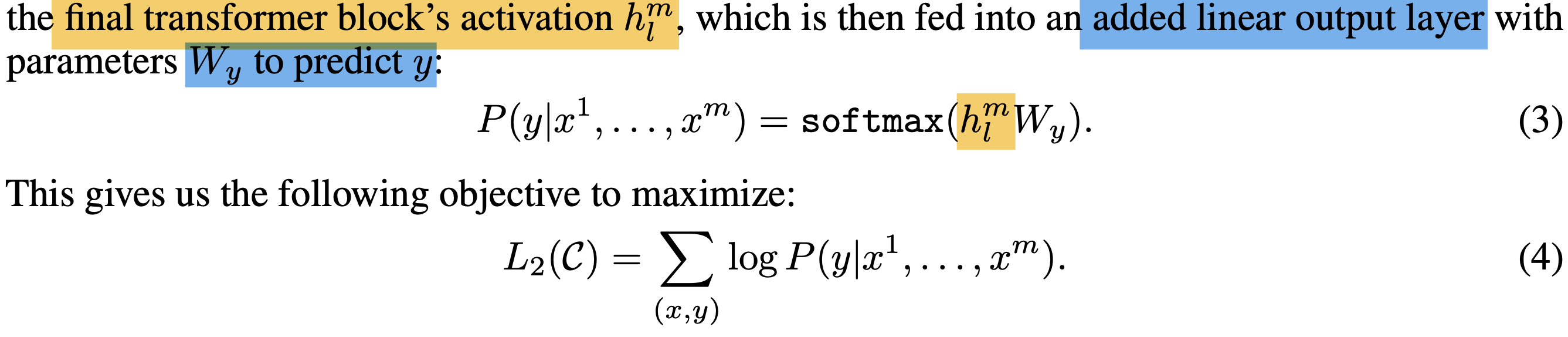
기본적으로, pretrain된 hidden state 값에 y를 예측하기 위한 가중치 W_y 가 곱해져 Linear layer로 들어가게 된다.
이제 데이터 셋에 label 값 y 가 존재하기 때문에, Likelihood function 은 y 값에 대한 확률을 사용한다.

추가적으로 논문의 저자들은, L2 function 에 L1 function을 더하여 보조적인 역할로 사용했을 때, 모델의 일반화와 학습 속도 향상에 도움이 되었다고 한다.
여기서 L1은 Unsupervised pre-training 부분에서 사용한 function으로, 위에서는 input 으로 U (즉, unlabeled dataset) 이 들어가있지만, 이 새로운 L3를 정의할 때는 fine-tuning 에 쓰이는 C (즉, labeled dataset) 이 들어가 있는 것을 확인할 수 있다.
( 아마도 기존의 pretrained weight 들을 고정하지 않고 갱신시키면서 더 빠르고 정확한 최적화를 이룰 수 있지 않았을까.. 싶습니다. ELMO의 경우엔 기존 weight를 고정한다고 하네요.. )
이제 구조를 살펴보자.
이 부분의 가장 중요한 부분은, 교회에 가두는 것. 즉, Task Specific 하게 Fine-tuning 시키는 것임! 그렇기에 TASK별로 input 구조를 다르게 하여 학습을 진행
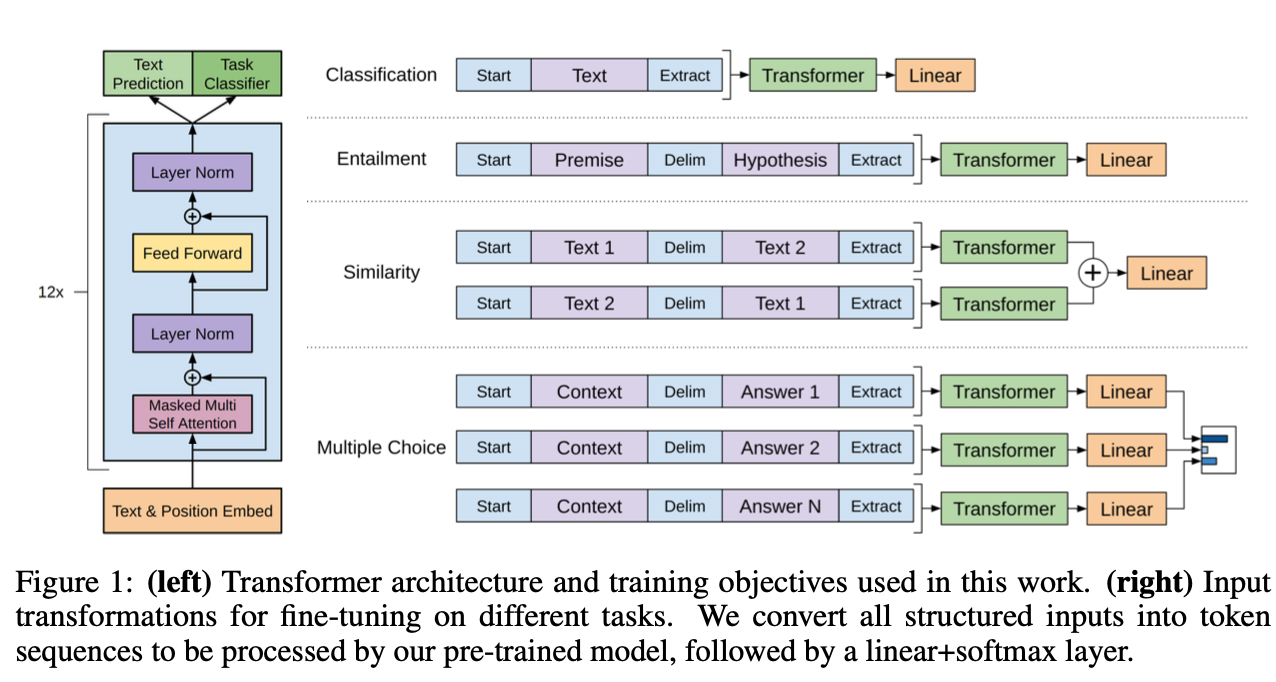
Input transformations for fine-tuning on different tasks
Classification
- Text 만을 집어넣고, transformer hidden state 업데이트, 그 후 선형결합
Entailment
- 한 문장이 한 문장을 의미적으로 '함의' 하는가의 task
-> 전제(premise)와 가설(hypothesis)
-> 두 문장 중 하나를 p, 하나를 h , p가 h를 함의하고 있는가를 검증 (Y or N)- input data는 다음의 형태
[premise] - <'delim'> - [hypothesis]
ex) 동물이 밖에서 에너지를 소모한다 <'delim'> 개가 밖에서 산책한다 -> 1 (0 or 1)
- Precise 와 Hypothesis 문장 (데이터에서 라벨링 되어 있음)
- 이를 deliminator 를 이용해 구분하고 처리
Similarity
한 문장이 한 문장과 의미적으로 비슷한가의 task
input data는 다음의 형태
[sen1] - <'delim'> - [sen2]
ex) 나는 사과를 먹는다 <'delim'> 나는 참외를 먹는다 -> 0.7 (0~1사이 실수값 , 유사도)
- 이를 deliminator 를 이용해 구분하고 처리
- sen1 과 sen2 를 순서를 바꾸어 처리하고 concat 하여 최종 결과값 냄
Multiple Choice
어떤 문맥에서 어떤 답변이 좋은가를 구분하는 task
동일한 context 에 대해 여러 답변들이 준비된 데이터
input data는 다음의 형태
[문맥][선택지 1] [선택지 2] ... [선택지 N]
- 이를 구분하고, transformer 에 각각 넣어 처리한 뒤 각 선택지에 대한 linear - softmax 값으로, 확률이 출력된다.
Conclusion
- 결국 GPT 는 semi-supervised learning 을 사용하여 task specific 한 LM을 구축한 것.
- 언어모델을 구성할 때 unlabeled data 를 활용하여 unsupervised pre-training
- 그 다음 특정 task 에 맞게 labeled data 의 input 을 transform 해서,task 별 label값 y를 맞추기 위한 supervised fine-tuning 을 실시해 기존의 weight 들을 조정해 나감
화제가 되는 GPT가 어떤 식으로 구성되어 있는지 파헤쳐볼 수 있어서 즐거운 시간이었음!
--딱히 즐겁지는 않았다--
References
https://ffighting.net/deep-learning-paper-review/language-model/gpt-1/
https://lcyking.tistory.com/127
