제목에서도 알 수 있듯이 Compute-Optimal 하게 LM 을 Training 시키는 것이 목표.
쉽게 말해서, 한정된 자원에서 LM 을 어떻게 Training 시킬 것인가?
여기서 집중해야 할 것은 어떤 자원 ?
또 어떤 수준 까지 Training?
- GPT와 같은 다른 자원을 아끼지 않는 LLM 들에 비하여 Optimal 하게 training 된 모델은 어떤 수준의 task 처리 능력을 가지고 있는가
마지막으로 어떤 방법론을 사용했을까?
정도로 파악된다. 한번 읽어보자.
INTRO & Abstract
읽어보니,
- 자원의 경우에는 Budget 이라고 표현하는 흔히 우리가 예상할 수 있는 Computing Resource 를 얘기하는 것. GPU FLOPS ...
- 우리가 알고 있는 GPT-3 , Gopher , Jurassic 등 보다 downstream task 에서 더 높은 성능을 기록.
- 이건 아직 정확히 모르지만,
Training Token 의 수와 Model parameter size 의 크기는 동일한 비율로 키워야 한다는 것이 저자들의 의견
-> 이를 수많은 실험을 통해서 증명함.
-> 실제로, 같은 예산 안에서 Gopher 에 비해서 더 낮은 수의 paramet 사용 및 training token 의 증가를 통해서 비율을 맞췄더니, 훨씬 높은 성능을 기록했다.
한정된 자원 속에서 최고의 성능을 뽑아내기 위한 Target Function 은 다음과 같다.
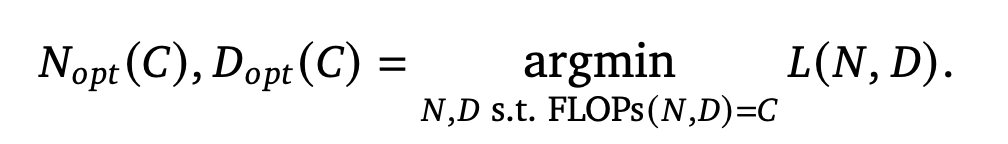
N : Parameter 수
D : Training Token 의 수
FLOPs(N,D) : N,D에 따른 예산 ( == C 로 , 고정된 상수임)
L(N,D) : parameter 수가 N이고, Training Token 의 수가 D일떄의 Loss
- 한마디로, 주어진 예산 C에서 할당할 수 있는 최적의 N과 D를 찾는것이 이들의 목적이라고 할 수 있다.
They estimated these functions based on the losses of over 400 models, ranging from under 70M to over 16B parameters, and trained on 5B to over 400B tokens
Target Function의 N과 D 최적화를 위하여 어떤 방법론들을 사용했는지 살펴보자
Related Works
Power-law Relationship
- 파라미터 수와 성능 사이의 수학적 연관관계, 비례관계
- 해당 논문 이전에는
- 위와 같은 형태로 구성된다고 말함.
- 여기서 N은 파라미터 수, 는 거듭제곱 지수
- 본 논문은 해당 관계에, 주어진 예산 (한정된 예산) C 를 추가하는 것이 목표
- 이 식이 해당 논문에서 어떤 실험 과정을 통해 어떻게 바뀌고 증명되는지 집중해보자.
Estimating the optimal parameter/training tokens allocation
최적의 parameter 와 training token 할당량을 어떻게 정할지를 구상해보는 파트이다.
실험은
- parameter 수 조정
- training token 수 조정
- 그에 따른 성능 곡선 확인 및 분석하여 경험적으로 최적화
의 흐름으로 진행
Approach 1: Fix model sizes and vary number of training tokens
가장 먼저, model size 를 고정 ( 즉, 파라미터 수의 차이 없이 ) 후 training token 의 수를 조정해봄.
- model 들은 70M ~ 10B param 까지 준비.
- 각각의 model 에 대해서 4개의 서로 다른 training sequence 준비.
여기서 training sequence 는
- Learning rate 실험 ( 10배씩 감소 )
- training tokens 실험 ( 16배 범위까지 )
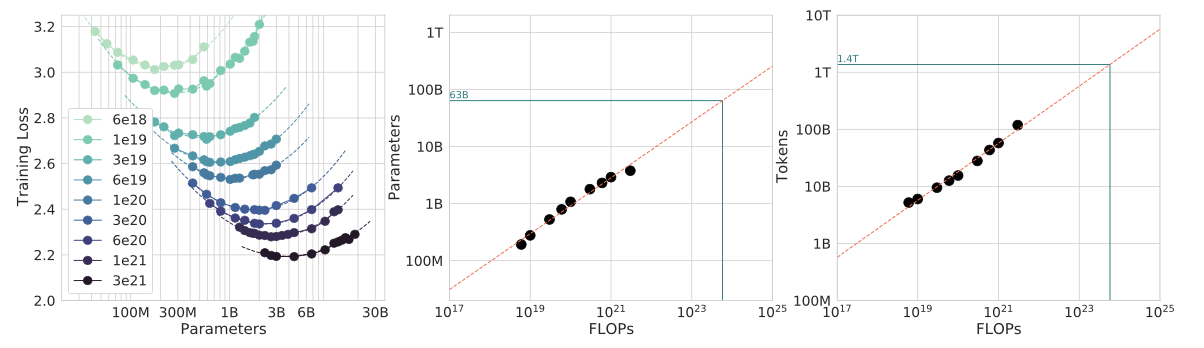
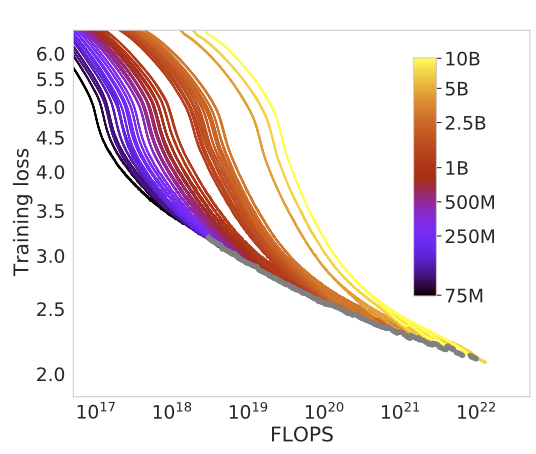 실험 결과, 각기 다른 parameter 수를 가진 model 들!
실험 결과, 각기 다른 parameter 수를 가진 model 들!
해당 모델이 가질 수 있는 최고 성능을 파악하여 curve 를 그릴 수 있었음
(정의역에서 FLOPS 가 비는 부분은 선형 보간법을 활용하여 치역값을 채워넣음)
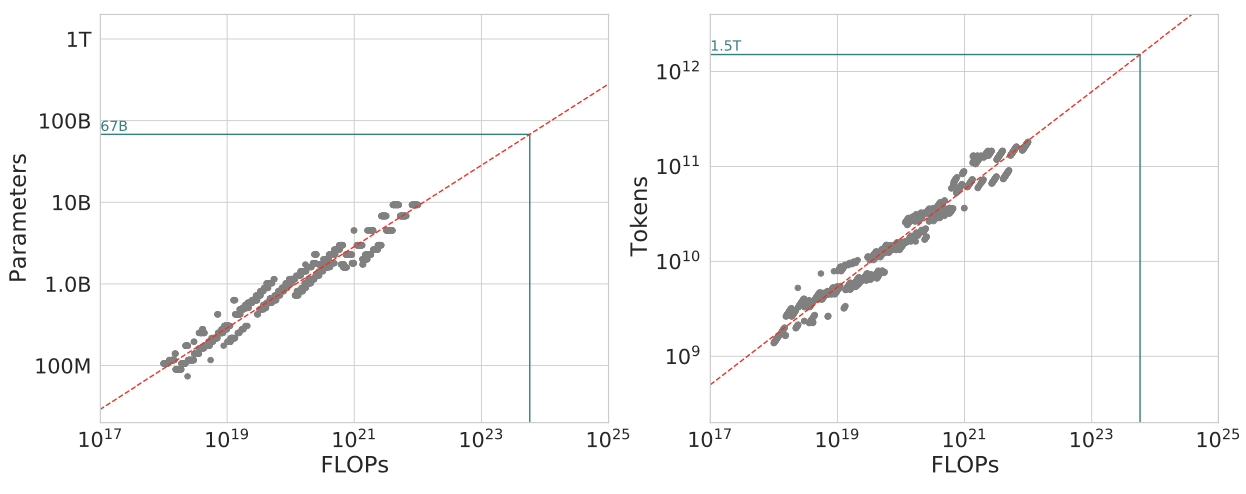 위의 curve 를 형성하여 만든 값들을 활용해서, 위의 두 그래프를 만들 수 있었음!
위의 curve 를 형성하여 만든 값들을 활용해서, 위의 두 그래프를 만들 수 있었음!
어디서 가장 Minimal 한 loss 가 등장했는지를 표현한 회귀식
- 여기서 저 초록색 라인은 Gopher 가 실제로 사용했던 FLOPS에 기반한 최적의 parameter 수와 token 수
- 회색 점이 각 flops 에서 최적의 loss 를 낸 points
결론적으로 아래와 같은 power-law relationship 을 도출함.
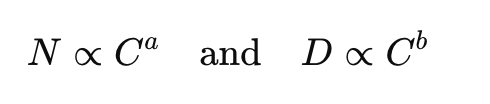
- parameter 수 N과 training token 의 수 D는 모두 계산예산 C (FLOPs) 와 power-law relationship 에서 0.5 정도의 최적값을 냄
- 이 말은 즉슨, parameter 수와 training token 의 수가 같은 비율로 증가해야 한다는 뜻.
Approach 2: IsoFLOP profiles
두번째로, 9개의 서로다른 training tokens 를 두고, model size 를 변경해가며 실험.
주어진 훈련 예산 C에서, 최적의 parameter 수를 직접적으로 찾을 수 있도록 진행하는 실험.
 똑같이 진행했고, 이를 통해서 도출된 값과 값은 각각 0.49, 0.51
똑같이 진행했고, 이를 통해서 도출된 값과 값은 각각 0.49, 0.51
첫번째 접근과 동일한 결론이 도출 가능.
Approach 3: Fitting a parametric loss function
1,2번의 결과를 가지고 활용하여 parametric loss function (우리가 잘 알고있는, 파라미터가 포함된 최종 손실함수)을 정의한다
.
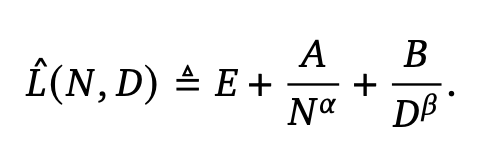 여기서 등호 위에 세모 표시는 '수학적으로 정의된다' 라는 뜻이란다...왜 쓰는지 참
여기서 등호 위에 세모 표시는 '수학적으로 정의된다' 라는 뜻이란다...왜 쓰는지 참
손실함수 설명
- L(N,D) 즉 N개의 학습가능한 파라미터와 D개의 training tokens 으로 학습된 LM의 loss 는 다음의 3개 항으로 나누어 표현할 수 있다.
- : 기본적인 loss . 생성 과정에서 생기는 오차항
- : (위의 실험들을 통해 얻은 최적치가 아닌 경우) 모델 파라미터가 부족해서 생기는 오차항
-α는 모델 크기에 따른 손실 감소 속도 지수
- : (위의 실험들을 통해 얻은 최적치가 아닌 경우) training token 수가 부족해서 생긴는 오차항
-β는 데이터 양에 따른 손실 감소 속도 지수
- 위의 는 모두 학습을 통해서 경험적으로 추정해 나가는 파라미터임.
이후,
모델 피팅을 통해서, 최적의 값을 추정
이후,
추정된 값들을 활용하여 위에서 얻고자 했던 값을 찾아야 함.
여기서는 선행연구에 의해서, 주어진 진행예산 C를 6N*D로 가정하고 들어감.
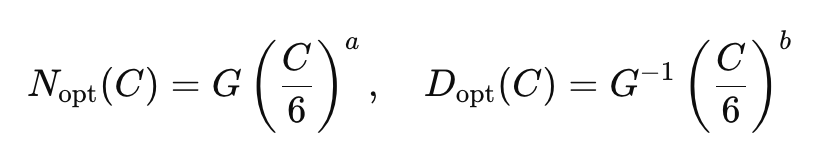 fitting 된 값을 활용하여 G를 구하게 되면, G는
fitting 된 값을 활용하여 G를 구하게 되면, G는 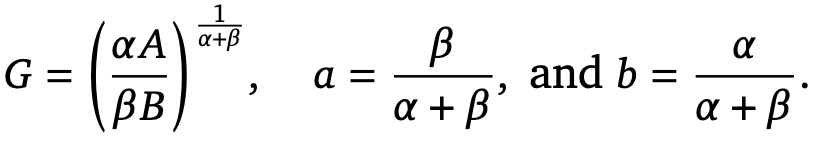 다음과 같게 형성되어, 우리가 실험적으로 구할 수 있는 G를 활용해 a,b 를 정의할 수 있다.
다음과 같게 형성되어, 우리가 실험적으로 구할 수 있는 G를 활용해 a,b 를 정의할 수 있다.
이들의 실험에 따르면 3번째 접근 방식으로 얻게된 a = 0.46, b=0.54 로 위 두가지 접근 방식과 동일한 결론을 도출할 수 있다.
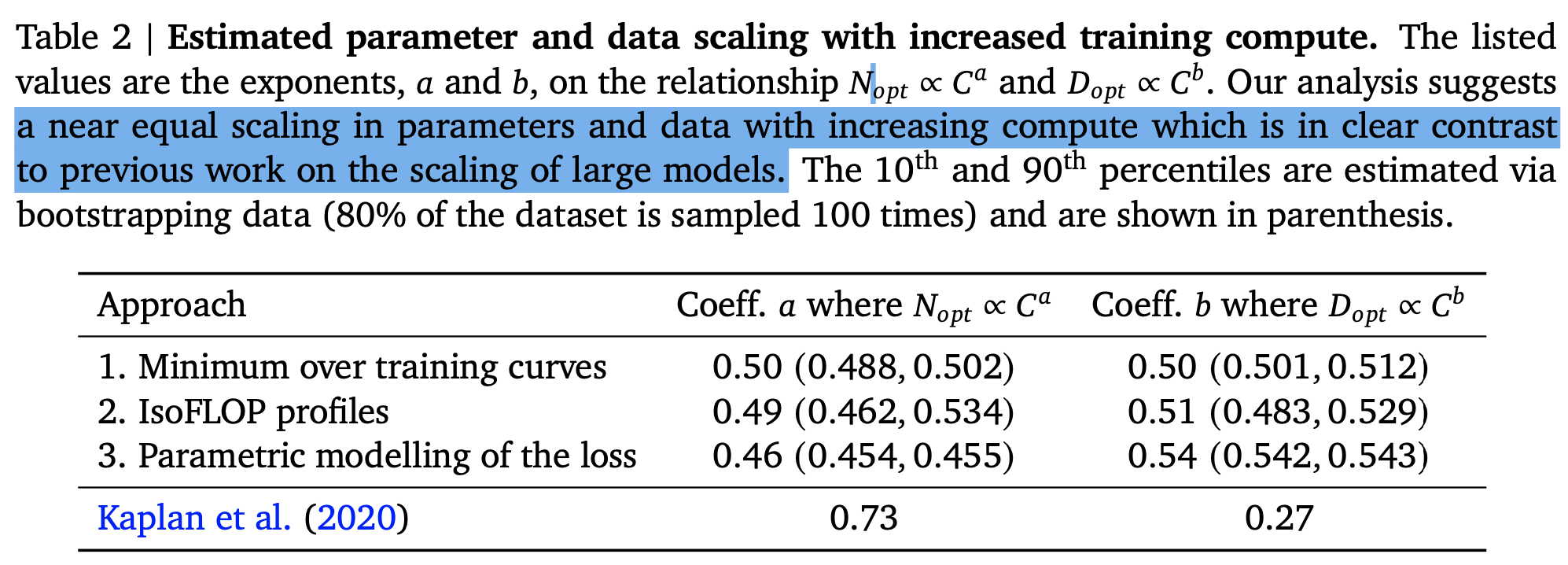 결과적으로, 이 부분에서 논문의 저자들은 기존 연구들이 주장하는 optimize 된 param 수와 training tokens 수의 비율과 달리 3가지 방법을 통하여 해당 두 인수가 비슷한 비율로 증가해야한다는 것을 증명했다.
결과적으로, 이 부분에서 논문의 저자들은 기존 연구들이 주장하는 optimize 된 param 수와 training tokens 수의 비율과 달리 3가지 방법을 통하여 해당 두 인수가 비슷한 비율로 증가해야한다는 것을 증명했다.
Model: Chinchilla
 위의 결과를 활용하여 모델(Chinchilla)을 재구성.
위의 결과를 활용하여 모델(Chinchilla)을 재구성.
특히, Gopher 라는 모델과 FLOPs 즉 가용한 컴퓨팅 자원 크기를 동일하게 설정하여 학습 가능한 파라미터 수와 training token 의 수를 비슷한 비율로 상승시켜 구성함.
다른 LLM 들과의 성능 비교를 실시함.
training details
- 모델 파라미터 수: 70억 (7B)
- 훈련 데이터: 1.4조 토큰
- 학습률을 10배씩 감소시키며, 학습 토큰 수를 16배씩 변화시켜 최적화
architecture details
- transformer based
- 80 layers
- 5120 hidden dims
- 40 attention heads
- 20480 dim of FC
- No dropout
Results on downstream tasks
Language Modeling
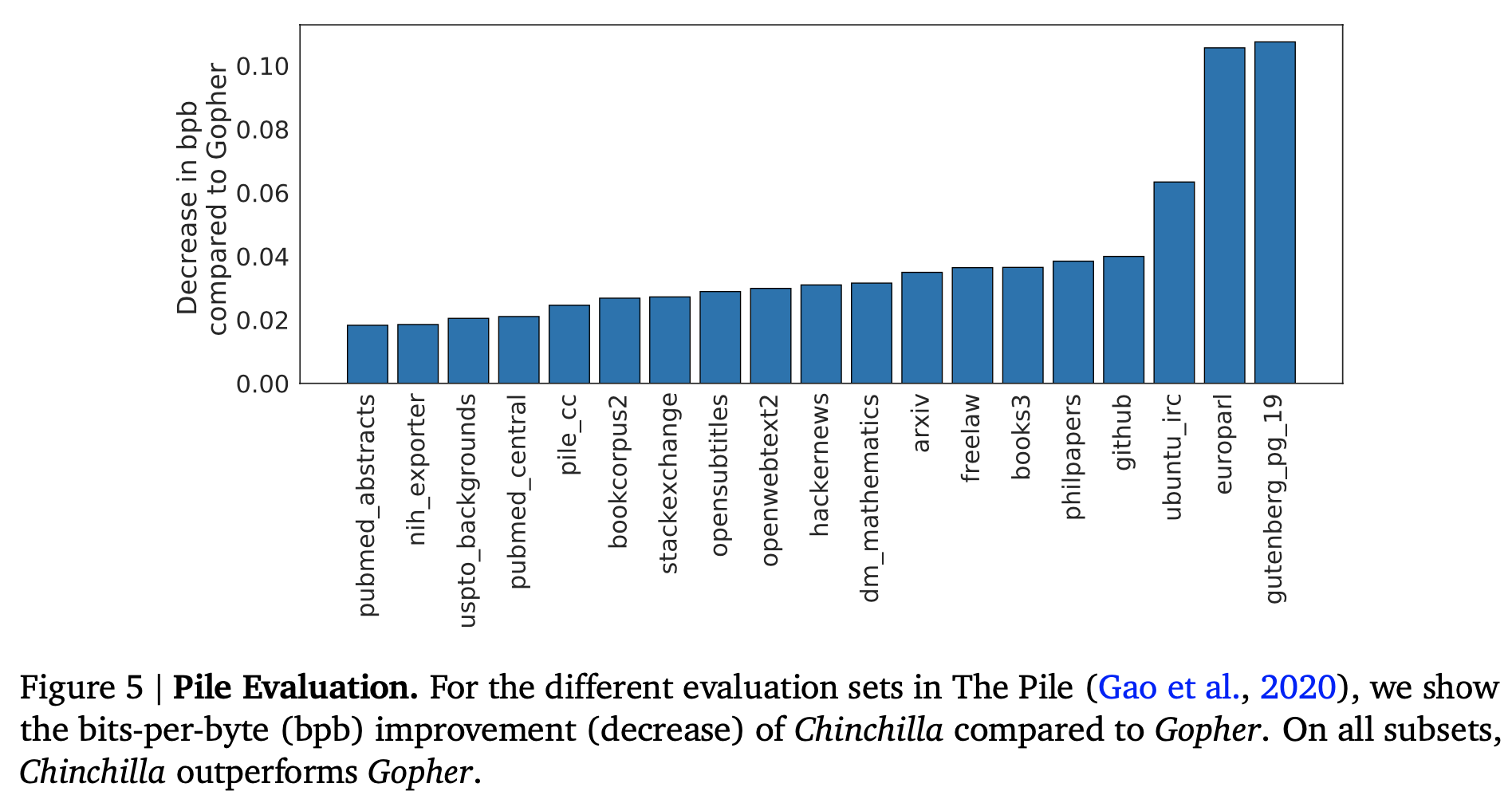
- The Pile subset 전 범위에서 Gopher 를 넘어서는 성능을 보여줌
MMLU(Massive Multitask Language Understanding) benchmark
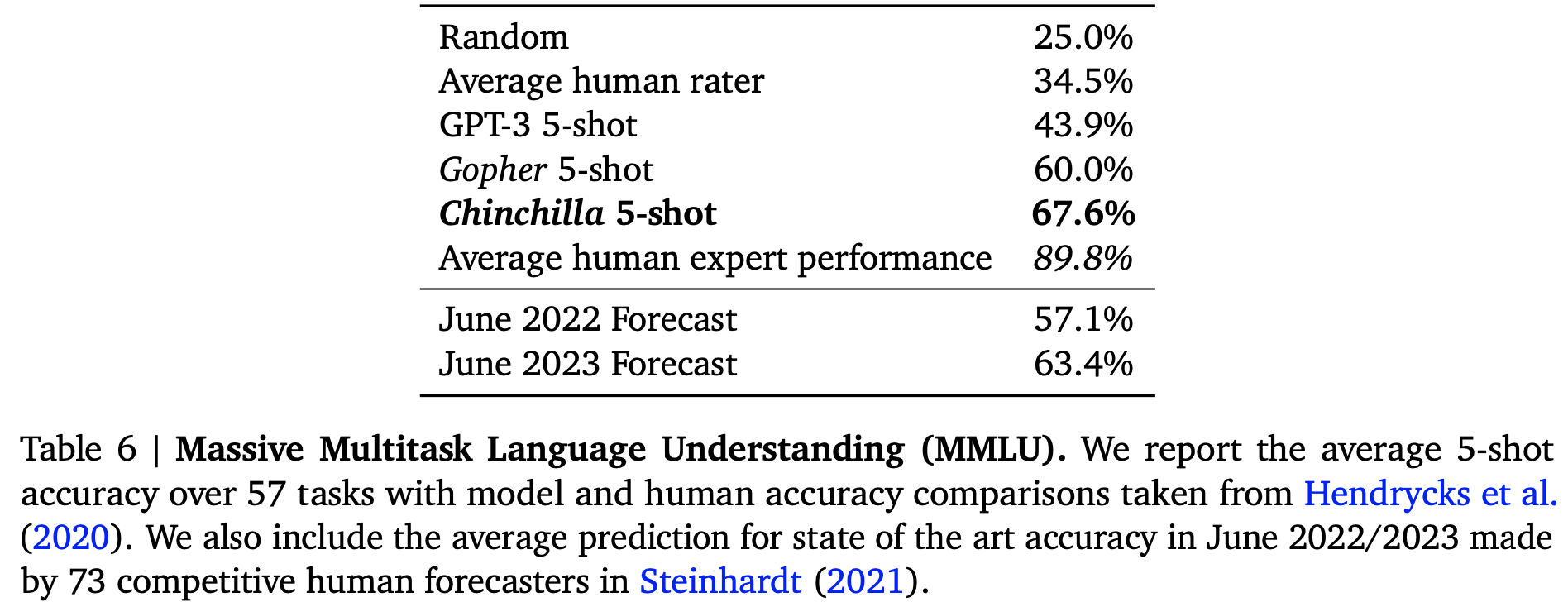
- chinchilla 5-shot 이 가장 뛰어난 성능을 보여줌.
이 밖에도, reading comprehension, Common Sense Reasoning ,Closed-book question answering 등의 LLM benchmark 들에서 타의 추종을 불허하는 성능을 보여줌.
Discussion & Conclusion
Conclusion은 우리가 너무 쉽게 얘기할 수 있는 뭐 ~ 실험을 통해서 효율적인 파라미터 수와 training token 의 수를 발견할 수 있었다는 뻔한 이야기.
주어진 C 에 대하여 비슷한 비율로 구성하여 상승시켜야 한다는 일반화 가능한 Logic 을 학계에 가져옴으로써 전반적인 LLM 발전에 도움이 될 수 있을 것이라는 이야기.
