이전에 GAN 을 살펴보았다.
오늘은 그 구조를 기반으로 발전시킨 StarGAN 을 살펴보겠다.
Intro & Abstract
StarGAN 은 제목에서 알 수 있듯, img to img translation 을 수행하는 모델이다.
What is IMG to IMG translation?
GPT의 답변을 참고하자
- 이전의 모델들은 two domain 에 대해서 밖에 다루지 못하는 단점 존재
- multi domain 을 대할 때 잘 대하지 못함
왜 ?
: 어떤 하나의 도메인을 대하기 위해서 하나의 새로운 모델이 있어야 하기 때문
StarGAN 은 그런 단점에 대응하여, multiple 한 도메인에 대처할 수 있는 새로운 모델 이다.
- multiple domain 의 face expression dataset 이 있음에도 불구하고, 기존의 모델들은 mutiple domain task 를 수행하는게 쉽지 않았음
- K 개의 domain 에 대응하기 위해서는 K(K-1)개의 generator 가 필요했기 때문
- StarGAN은 하나의 genenrator 로 k개의 domain 에 모두 대응
Domain이 5개일때 아주 아름다운 Star shape 이다!
Related Works
GAN
- 저번에 했으니 넘어가자
Conditional GANs
- 말 그대로, 어떤 특정 condition 에 해당하는 img 를 생성해내는 GAN 들을 일컫는다.
- given text 로 부터 condition 을 파악해 GAN 의 Generator 와 Discriminator 가 모두 각자의 과정에서 condition 을 더해 일을 수행한다.
Img to Img translation
- 위에서 언급했으니 넘어가자
Star Generative Adversarial Networks
어떻게 본 논문의 제자들이 single dataset에 대한 single network 로 multiple domain 을 대응했는지 살펴보자.
Multi-Domain Image-to-Image Translation
single generator G 가 multiple Domain 을 학습하는 것이 목적.
G : generator
x : input IMG
c : target Domain labelG(x,c) -> y 에서 C는 랜덤하게 생성되고, 그를 통해 Generator G 는 input img 의 random translation 을 학습할 수 있게 됨
D : Discriminator
Generator 가 저렇게 생겼으니, Discriminator 는 두개를 판별해야함
1. 이놈의 'C' , 즉 domain label 이 무엇인지
2. 이놈이 진짜인지 가짜인지 , 즉 GAN Discriminator 의 원래 목적
그래서 , 결국 Discriminator Term 은 다음과 같음

그렇다면 Loss Function 은 어떻게 될까? 가 다음 질문이다.
Loss 는 총 3개가 있다 .
Adversarial Loss
- Adv Loss 는 Generator 의 생성을 Discriminator 가 판별하지 못하도록 하는게 목적이 되는 Loss 이다.
자세히 보면, GAN 에서의 Loss Fucntion 과 똑같다!
위에서 설명했듯이, D_src 는 원래 GAN 의 목적과 같은 Discriminator Term 이기 때문에 뭐 GAN 의 Loss 를 이해했다면 이쯤은 그냥 넘어가도 될 것 같다.
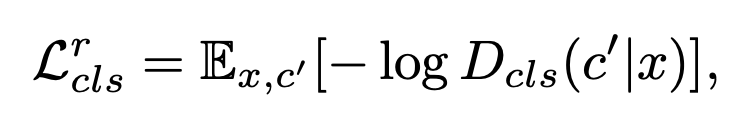
Domain Classification Loss
- 매우 중요!!
- input img x 와 target Domain Label C 를 받았을 때, input img x 를 추후, 'c' 로 분류될 만한 y 로 "translate" 하는게 목적이 되는 Loss
- 여기서는 두개의 Loss Function 이 존재한다.
먼저, Discriminator
1) Discriminator
Discriminator 는 어떻게 학습해야할까?
- Discriminator 는 Generator 를 죽이는 녀석
- 이 Loss 에서 Generator 는 target Domain Label C 에 맞춰 input img 를 변형하여 생성한다.
- 그렇다면 Discriminator 는 Generator 와 반대로, input img 를 target Domain label C 가 아니라, 원래 label 인 C_prime 으로 분류하도록 train 되어야 한다.
다음은 Generator 다
2) Generator
Generator 는 방금 설명했듯, 부여받은 target Domain C 로 input x 를 변형시켜 생성하고 그걸 Discriminator 가 잘 구분하지 못하게 해야한다.
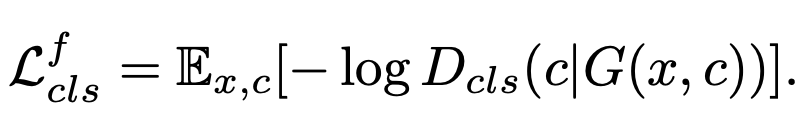
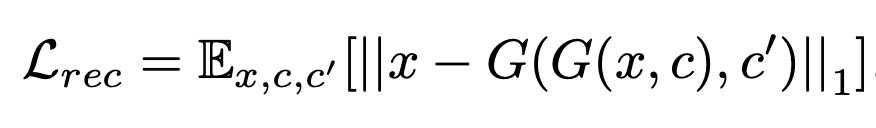
이때, 의문점이 생기는데!
그럼 얘네는 동시에 이 Loss 두개를 어떻게 학습할까?
Discriminator 가 Train 되려면 Real img 가 필요하고, Generator 가 train 되려면 Faek img 가 필요한데, 같은 단계에서 진행할 수 있나?
그래서 논문의 저자들은 다른 곳에서도 많이 본 Auxiliary Classifier 를 사용해 Discriminator 의 앞단에 넣어준다.
Reconstruction Loss
- cycle consistency Loss
- 위의 generator 오차만으로는 부족
- 입력의 도메인 관련 부분만(C or C_prime) 변경하면서 입력 imgs의 콘텐츠를 유지한다고 보장할 수 없음
- 생성 자체에 집중하는 Loss 가 필요하다.
- Using L1 norm
- input img 와 given domain C 를 기반으로 생성한 G(x,c) 를 real domain c_prime 을 주어 reconstruct 했을 때의 차이
- 즉 generator 만의 성능으로 input img x 와의 비교를 수행
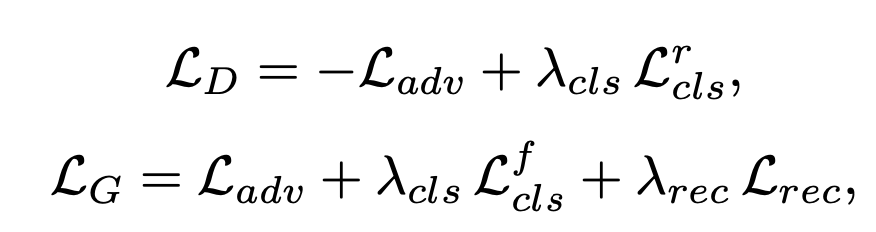
그래서, 최종 Loss function 은 다음과 같다.

Training with Multiple Datasets
StarGAN 의 training 은 그냥 multiple 한 dataset으로 진행할 수 있어야 하는데, 문제가 존재함.
- Domain label 'C' 는 랜덤으로 정해지는데, dataset 별로 label 값, 즉 c_prime 값이 다르다.
- 예를 들어 첫번째 데이터셋은 머리색, 눈 색 같은 multiple domain 이 있는 반면, 두번째 데이터셋은 표정에 따른 기분에 대한 label 이 있을수도 있다.
이걸 해결하기 위해서, StarGAN 은 두가지를 사용한다.
Mask Vector
모델이, 어떤 데이터셋을 받았을 때, 다른 데이터셋의 label 을 c 로 선택하지 않게 하는 방법
데이터셋이 n 개 있는 상황 (그에 따른 라벨 벡터 c_n )
- 여기서 masking 된 label 들은 0 이 됨
Mask vector 에서 언급한 label vector 를 제외하면 training process 는 single domain 과 정확히 똑같다.
( 위에서 말헀던 Auxiliary classifier 를 넣어주는 부분도 추가..ㅎㅎ)
- 그 과정에서, Known label (Unknown label 은 masking!) 에 대해서만 loss function 을 통한 D&G optimizing 을 수행
