본문에서는 SPPnet 논문과 관련 지식들을 다룹니다.
오류가 있다면 언제든 지적해주세요!
Introduction & Abstract
- 현존 CNN모델들은 input size가 고정 되어야 하는 문제를 가지고 있음
왜 고정되어야 하는가?
CNN 모델은 크게 convolution layer 와 fully-connected layer 로 구성되어있는데, Conv layer 는 어떤 이미지를 넣어도 sliding window 를 통해 해당 input 의 feature map 을 만들어주지만, Fully-connected layer 가 고정된 인풋을 받아야 하기 때문이다. (고정된 사이즈의 아웃풋 벡터와 연결을 해주는 놈이기 때문에)
: 왜 문제인가?
1. 인풋 데이터의 scale 과 aspect ratio 를 제한함
2. cropping 된 데이터에 object 의 전체 모습이 들어가지 않게 될 수 있음
3. scale 을 맞추기 위해 warp 되면 뜻하지 않은 왜곡이 생길 수 있음
-> 학습 정확도가 낮아질 충분한 위험!

-
SPP net 은 인풋 사이즈가 고정되지 않아도 됨
-
image 를 crop,warp 시키고 conv 통하면 문제가 발생.
-
SPPnet 은 그런 단점을 최소화 하고자, 원본 이미지를 먼저 conv 통하게 하고 , SPP layer (Spatial Pyramid Pooling layer) 를 통해 fc 들어가기 앞서 인풋 벡터 사이즈를 조정해줌

이를 통해,
1. 원본 이미지의 특징을 그대로 가져온 피쳐맵을 추출가능!
2. 목표 사물의 다양한 scale 에도 대응가능!
3. Image classification , Object detection 등에도 활용가능!
R-CNN에 비해서는 어떨까?
정확도는 비슷하나, 속도가 엄청 빠르다!
HOW?
- R-CNN과 정확도는 비슷한 반면 속도가 약 20~100배 빠름
- 그 이유는 업무의 효율성에 있음
CNN은 아래와 같이, Selective Search를 통해, 수 많은 ROI(Region of Interest)들을 뽑아내고, 각각을 convolution layer 에 통과시키는 계산을 함
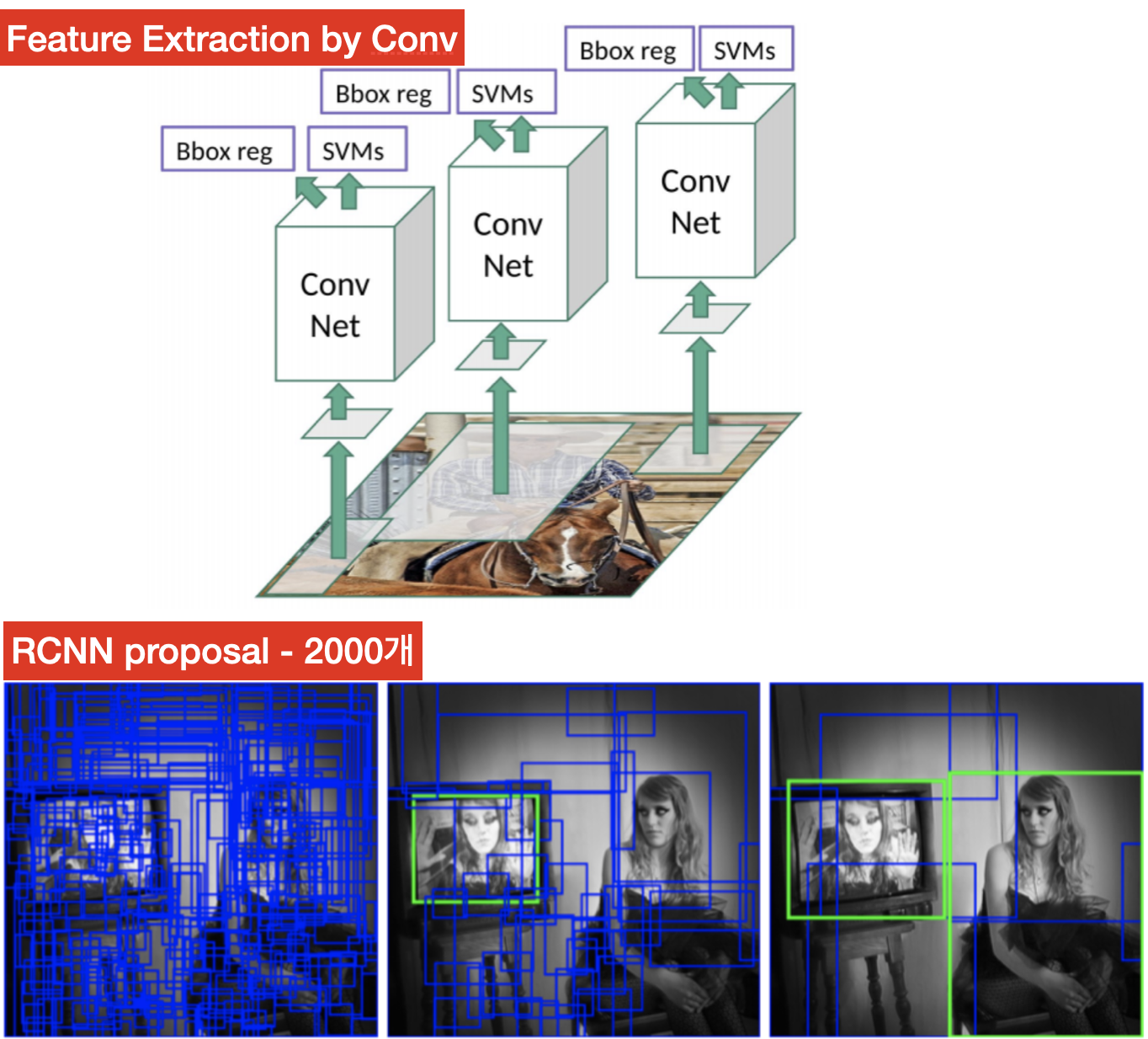
SPPnet은 원본 이미지를 먼저 Convolution layer에 넣고 ROI 대상에 한정된 feature map을 SPP layer 를 통해서 고정된 크기의 벡터를 출력한 다음, FC layer 에 보내준다는 차이가 있다 !
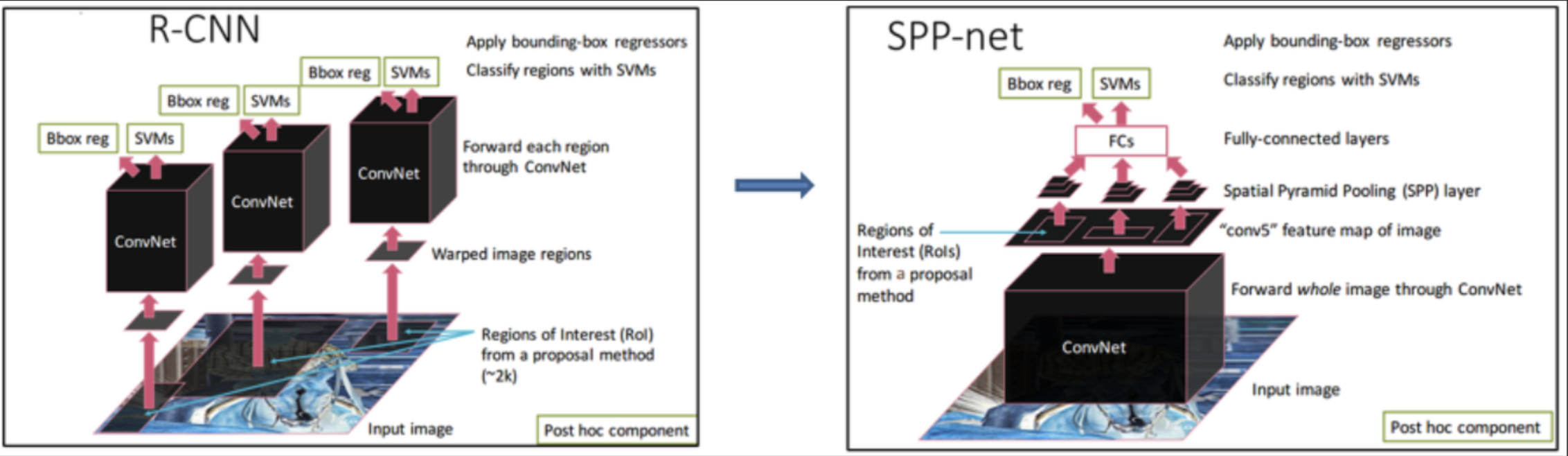
- 위의 RCNN은 2000개의 인풋 이미지 내의 ROI들에 대해서 모두 conv 연산 을 수행
- 그에 반해 SPP net 은 인풋 이미지 전체에 대해서 1회 conv 연산 을 수행
-> convolution 연산량이 엄청나게 줄어들게 됨!(2k -> 1)
DEEP NETWORKS WITH SPATIAL PYRAMID POOLING :
about Spatial Pyramid Pooling layer
위에서 설명한 것과 같이, SPPnet 은 다음의 구조로 이루어져 있음
INPUT ➡️ CONV ➡️ SPP ➡️ FC ➡️ Classify or Regress
그래서 SPP layer 가 무엇인가?
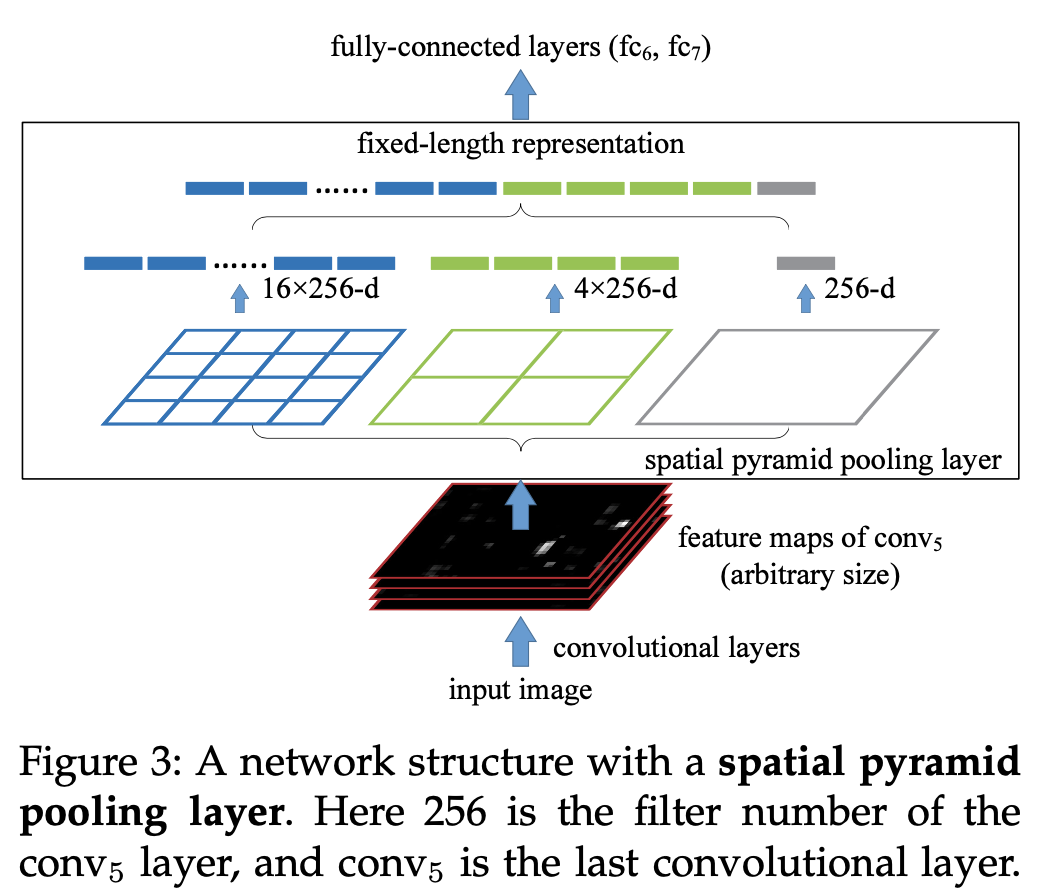
논문에 들어있는 SPP layer 에 대한 자료이다.
SPP는 spatial pyramid pooling 으로 직역하자면 공간 피라미드 풀링 !
이름과 연관지어 SPP layer를 보자면 다음과 같다.
Spatial : feature map의 공간적 정보 유지
Pyramid : n x n 부터 1 x 1 까지 다양한 scale 의 bin 들을 활용
Pooling : layer의 역할
인풋 바로 뒷단에 붙는 convolution layer는 sliding window를 통해 어떤 input size 이건 간에 feature map을 만들어줄 수 있지만,
input size 가 다양한만큼, feature map 의 size 도 다양할 것..
what to do ?
❗️ 다양한 feature map size 를 일괄적으로 만들어 줘야함
❗️ 이 과정에서 다양한 scale 의 spatial bins 를 활용
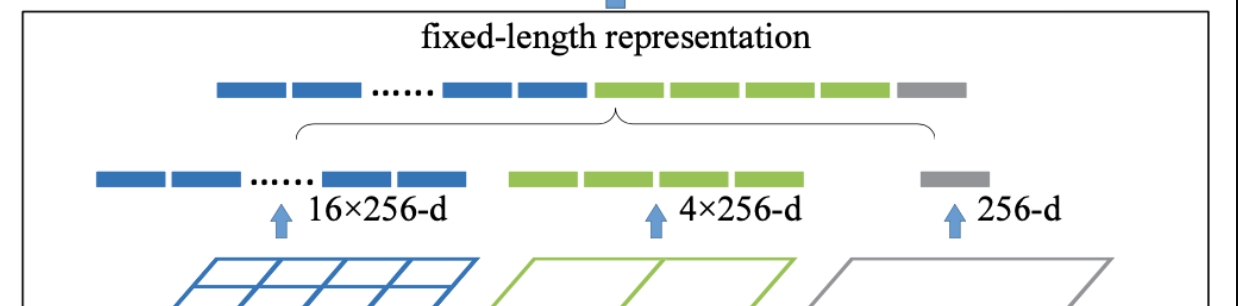
Feature map 을 미리 정해져 있는 영역들로 나누어 준다!
위의 경우, 미리 4x4, 2x2, 1x1 세 가지 영역
- 각각을 하나의 피라미드라고 부름.
- 3개의 피라미드를 설정, 피라미드의 한 칸을 bin 이라고 함
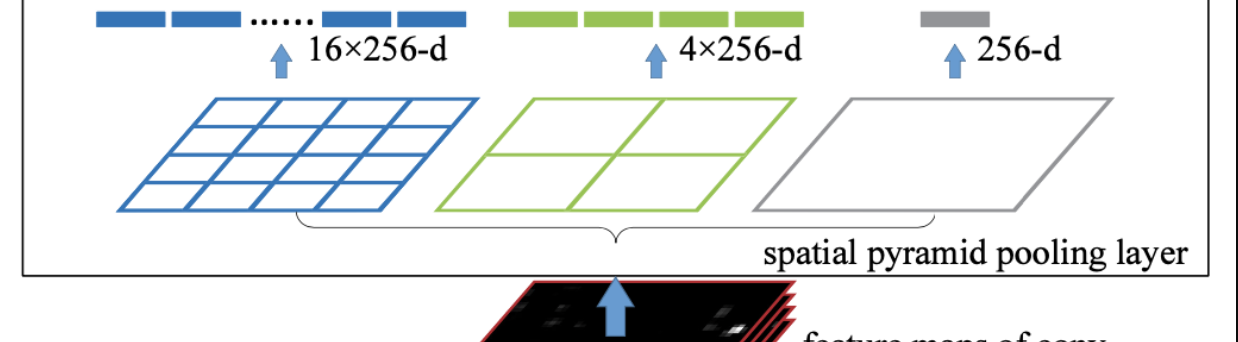
And then
❗️ 그 다음 bin 별로 Max Pooling 을 수행 후 값들을 이어붙여 나열
❗️ 그 값들을 붙여 벡터화 하고, FC layer에 전달!
-
다양한 피쳐 (bin) 가 즉 해당 이미지의 공간
-
그 때 그 공간은 여러 scale 로 잘림 (개인이 설정가능), 다양한 특징들을 만들어내지만, 고정된 크기의 representation 을 만들 수 있다. (multi view test)
-
다양한 scale의 특징을 추출할 수 있는 장점이 존재.
-
특정 scale 에 대해서 오버피팅 되는 문제 또한 완화.
+ Spatial Pyramid Pooling layer 추가
-
어떤 이미지의 특정적인 window 가 정해졌으면, 해당 window 가 여러 scale 의 bin 을 지나게 됨
-
Bin 수는 일정한 수로 고정 : multi view 이므로, 뭐 nxn, mxm, pxp 뭐 이렇게 있다고 하면, bin수는 총 n^2 + m^2 + p^2 이렇게 될 것
-
필터는 conv layer 에서 사용되는 필터 개수
-
고정된 길이의 벡터가 만들어짐. bin수 * filter수
-
bin 수를 늘리면 늘릴수록, 강건하고 다양한 특징이 나올 수 있겠지만, 복잡도가 올라갈 것.
-
여기서, 같은 윈도우 대상에 대해서, 어떻게 서로 다른 scale의 bin들이 나올 수 있느냐? : stride와 filter size 를 조정해서 끼워맞춤.
How to train the Network
입력 이미지 크기에 관계없이 역전파 방법을 사용해 model train
그러나 GPU 구현시에는 (논문상에서는 cuda-convnet, Caffe를 언급) 고정 이미지 크기를 선호함
❗️ SPP 를 유지하면서 이러한 GPU 구현의 이점을 살리기 위한 Train 방식!
❗️ 오로지 모델 훈련만을 위한 방법!
1. single size training
고정된 input size 의 데이터만을 활용!
cropping,warping 은 data augmentation 으로 인식.
고정된 input에 대하여, 여러개의 filter,stride 사용 -> multi scale pooling 구현
ex)
224 x 224
-> (after conv5) 13 x 13
-> pooling with Various Stride and Window sizes
-> multi - Leveled Vectors
2. multi size training
다양한 input size 의 데이터들을 활용!
서로 다른 input size 를 가진 데이터들을 crop 하고 조정하여 size를 맞춤
여러 scale 의 데이터 별로 모델을 학습시키고, 해당 과정을 반복함.
References
https://herbwood.tistory.com/5
https://www.youtube.com/watch?v=i0lkmULXwe0&t=460s
https://festive-impatiens-b9a.notion.site/SPPNET-1717396cd0564e24b4824f24e2c2baba
