학과 수업 '빅데이터최신기술' 에서 진행하는 프로젝트에 대한 정리이다.
발표 영상 : https://youtu.be/dvEL1lQ61sA
사용 데이터
사용 예정 데이터는 , AIHUB의 텍스트 데이터인 '인공지능기반 학생 진로탐색을 위한 상담 데이터 구축' 를 사용하고자 한다.
사용 데이터 링크 : https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=71618
사용 데이터 소개
이 데이터는, 전국 약 6500명의 초,중,고등학생을 대상으로 실시한 온라인 상담 텍스트 데이터이다. 상담 전문가에 의해 실시되었으며, 상담 전문이 기록되어 있고 발화기준으로 약 826,160건의 데이터가 존재한다.
상담내용의 어절 수 분포는 다음과 같다
: AI Hub 제공
데이터는 크게 3가지 이다.
상담 내용 기록 , 학생 정보 데이터, 전문가 상담 리뷰 데이터이다.
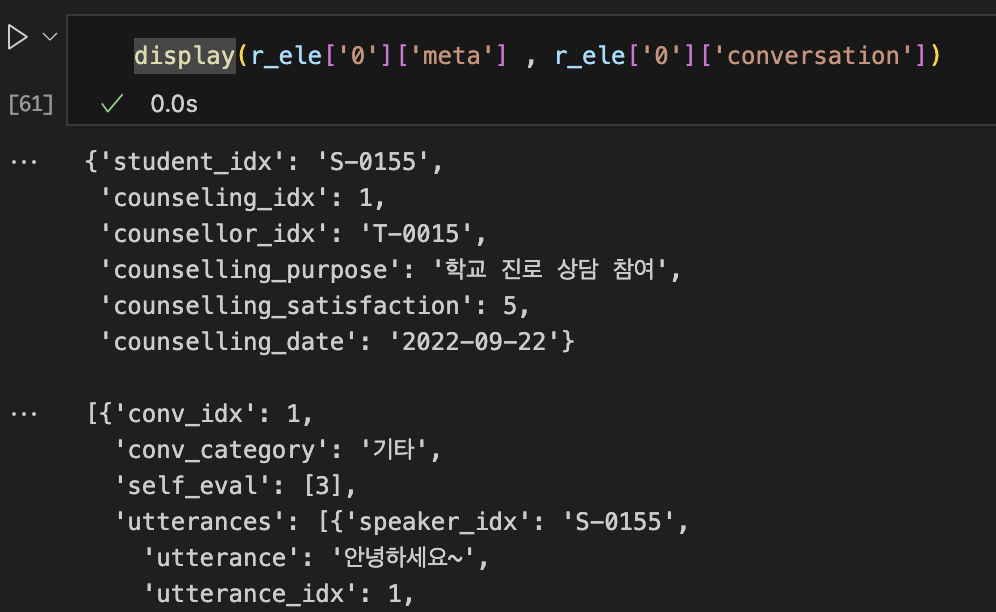
상담 내용 기록
- 학생별로
상담 일시 , 상담 만족도 , 발화 내용 , 발화대기시간 등이 작성된 데이터
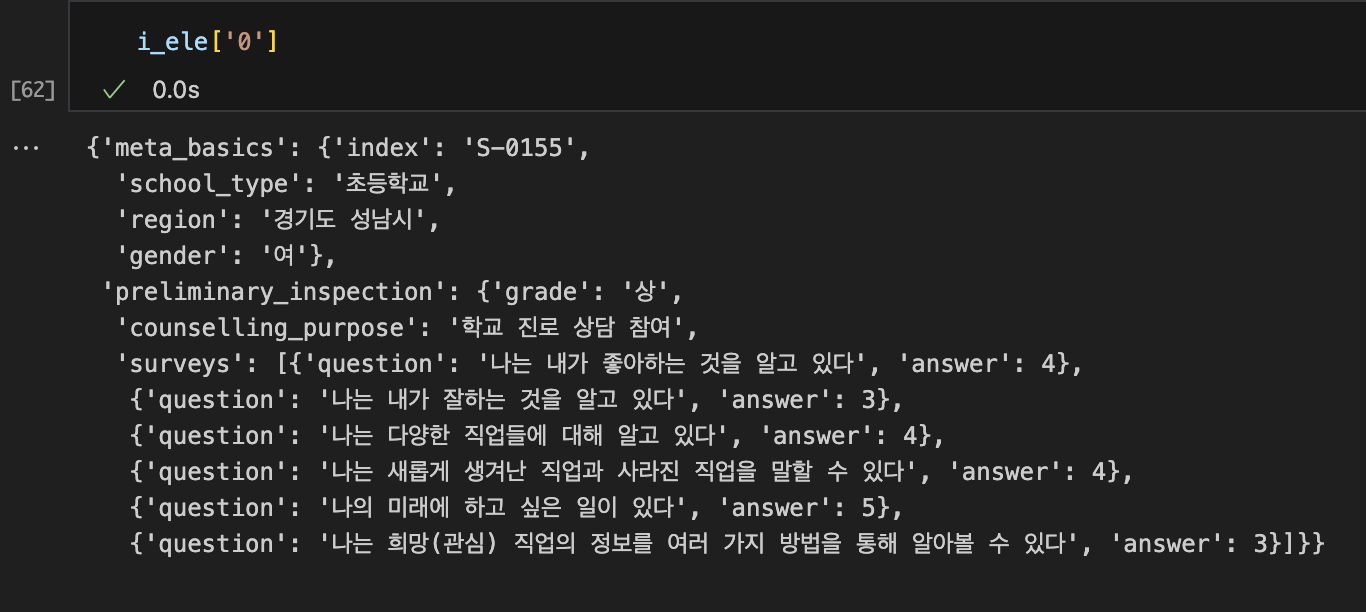
학생 정보 데이터
- 학생별로 학생 개인 정보가 담긴 데이터
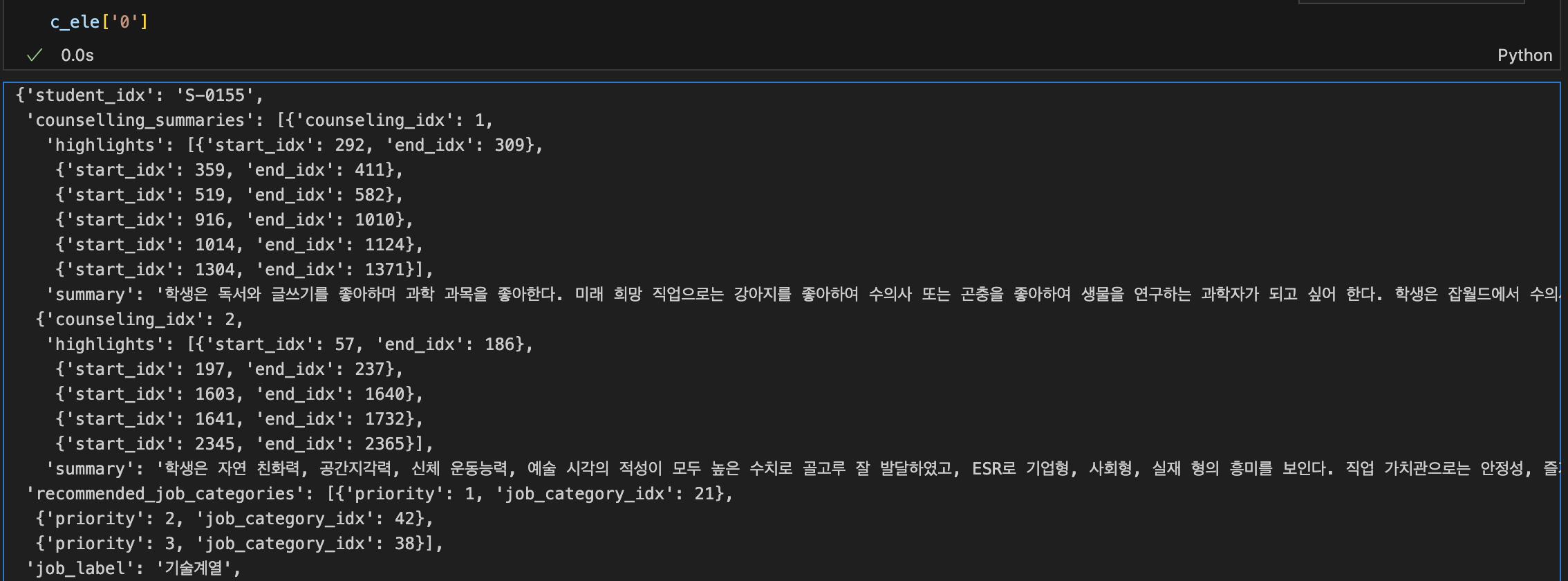
전문가 상담 리뷰 데이터
- 상담별로 상담 결과가 정리된 데이터이다.
- 상담에 대한 전문가의 요약 및 서술과 추천 직업 계열이 담겨있다.
진행해보는 첫번째 개인 NLP 프로젝트이기 때문에, 여러가지 정보를 다양하게 활용해보고 싶지만 기술적으로 구현을 하는데에 약간의 무리가 존재할 것 같아 상담내용과 전문가의 추천 직업 계열을 사용하고자 한다.
데이터 추가 소개
상담 내용 텍스트만을 뽑아, 데이터 양을 측정해보았다.
텍스트를 뽑는 과정은 다음의 과정을 따랐다.
- 초,중,고가 분리되어 있는 상담내용 데이터셋의 '상담내용' 만을 뽑아온다.
- 해당 내용들을 모두 합쳐 '엔터' 로 구분되어 있는 텍스트파일로 저장
- 해당 텍스트 파일을 대상으로 측정

이 결과 학습 데이터로 사용할 데이터는 총 38,442,890바이트 (38.4MB) 로 측정되었다.
Project Flow
NLP task 를 진행해보지 않아, 전반적인 프로세스는 GPT를 빌려 세워보았다.

데이터 전처리
데이터를 조금 살펴본 결과, 온라인 채팅이다 보니 오탈자도 존재하고, 서로 나눈 대화 중에 웹페이지 링크를 전송하는 경우도 존재했다.
100% 한국 학생들을 대상으로 진행했던 상담이기 때문에 전체 데이터에서 영어를 제외해도 괜찮겠다고 판단하였다.
전처리는 다음의 과정을 거칠 것으로 계획한다.
- 특수 문자 제거
- 영어 제거
형태소 분석 / 토큰화 + 단어 임베딩
한국어 문장을 토큰화 할 수 있는 모듈인 KoNLPy를 사용하고자 한다.
현재 VsCODE 에서 python 을 사용하여 프로그래밍 하고 있기 떄문에, 한국어 자연어 처리가 가능한 파이썬 라이브러리 중 가장 널리 사용되는 KoNLP의 MeCab 을 사용하고자 한다.
문장을 형태소 단위로 분리하여 토큰화 하고자 한다.
( kkma는 돌려보았을 때 시간이 너무 오래걸려서 pass...)
그 이후 토큰화된 문장을 word2vec 을 사용하여 임베딩할 예정이다.
모델 구축
일단 현재 가장 NLP task 에서 효과적으로 알려져있는 Transformer 기반의 모델을 구축하고자 한다.
상담 내용의 문맥을 잘 해석해서, 해당 학생이 어떤 직무가 어울리는지를 잘 분류해야 하기 때문에, pre-train 된 LLM 기반의 BERT 나 RoBERTa 를 사용한 딥러닝 기반 분류모델을 구축하고자 한다.
