1. 개요
확장 칼만 필터(Extended Kalman Filter, EKF)는 센서 측정 데이터로부터 시스템 상태를 추정하는데 널리 사용되는 알고리즘이다.
이 알고리즘은 칼만 필터(Kalman Filter)의 확장된 형태로, 비선형 시스템 및 측정 방정식에 대한 선형화 과정을 포함한다. 이번 글 에서는 EKF의 필요성, 기본 이론, 그리고 JavaScript환경에서의 예제를 살펴보고자 한다.
2. EKF가 필요한 이유
일반적인 칼만 필터는 선형 시스템 및 선형 측정 방정식에만 적용될 수 있다.
그러나 많은 시스템은 비선형이거나, 선형성이 근사적일 수 있기 때문에 따라서, 비선형 시스템 및 측정 방정식을 모델링하는데 필요한 확장된 필터링 기법이 필요하다.
EKF는 시스템 및 측정 방정식의 선형화를 통해 이러한 문제를 해결하는 알고리즘이다.
3. EKF 알고리즘의 기본 연립 미분 방정식 해석
EKF는 시스템 상태를 추정하기 위해 다음의 두 단계를 반복적으로 수행한다.
예측 단계 (Prediction Step):
상태 예측 (State Prediction):
현재 상태 및 제어 입력에 기반하여 다음 상태를 예측한다.
이는 시스템 모델(주로 동역학 방정식)을 사용하여 수행한다.
공분산 예측 (Covariance Prediction):
상태 예측의 불확실성을 나타내는 공분산 행렬을 예측한다.
이는 선형화된 시스템 모델의 자코비안 행렬을 이용하여 수행된다.
업데이트 단계 (Update Step):
칼만 이득 계산 (Kalman Gain Computation):
예측된 상태 및 측정 데이터 간의 불일치를 고려하여 칼만 이득을 계산한다.
상태 업데이트 (State Update):
측정 데이터를 사용하여 상태를 수정하고, 예측된 상태와 측정 데이터 사이의 차이를 최소화합니다.
공분산 업데이트 (Covariance Update):
상태 업데이트 후, 공분산 행렬을 업데이트하여 업데이트된 상태의 불확실성을 반영한다.
자율주행에서의 수식정의 및 해석
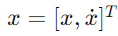
여기서, x는 자율주행 차량의 위치이고, x˙는 그 속도를 나타낸다고 가정하자.
이 예시에서, 시스템은 다음과 같이 정의할 수 있다.
-
자율주행 차량은 등속 운동하며, 위치 및 속도는 다음과 같이 변화한다.
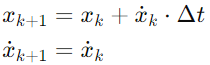
여기서 Δt는 측정 사이의 시간 간격이다. -
측정 모델: GPS 센서를 통해 얻은 위치 측정은 다음과 같이 계산할 수 있다.
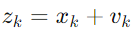
여기서 vk는 GPS 측정 오차를 나타내는 노이즈이다.
이때 시스템 모델 및 측정 모델의 미분 방정식을 정의하면 다음과 같다.
위의 시스템 및 측정 모델은 비선형이므로, EKF를 적용하기 위해선 이를 선형화해야 한다. 이를 위해, 시스템 및 측정 모델을 다음과 같이 미분하여야 한다.
시스템 모델 미분:
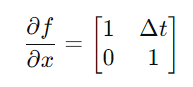
시스템 모델의 미분은 위치와 속도에 대한 상태 변화률을 나타낸다.
측정 모델 미분:
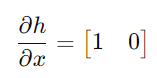
측정 모델의 미분은 위치에 대한 측정값과 상태의 관계를 나타낸다.
EKF의 예측 및 업데이트 단계 수식
예측 단계 (Prediction Step):
상태 예측:
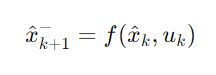
공분산 예측:
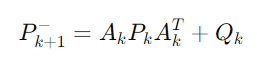
여기서 Xk+1 은 예측된 상태, Pk+1은 예측된 공분산, Ak는 상태 전이 행렬의 미분, Qk는 프로세스 노이즈의 공분산 행렬이다.
업데이트 단계 (Update Step):
칼만 이득 계산:
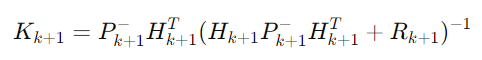
상태 업데이트:
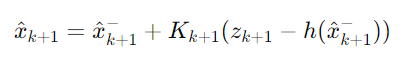
공분산 업데이트:
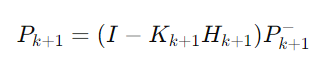
여기서 Kk+1은 칼만 이득, Hk+1은 측정 행렬의 미분, Rk+1은 측정 노이즈의 공분산 행렬이다.
이것이 EKF 알고리즘의 기본적인 수식이다.
이를 사용하여 시스템 상태를 추정하고, 예측과 측정을 통해 상태를 업데이트할 수 있으며, EKF는 이러한 예측과 업데이트 과정을 반복하여 시스템의 상태를 효과적으로 추정한다.
다음은 Python 환경에서의 EKF사용예제이다.
4. Python 환경에서의 EKF, Plot 분석
Code
import numpy as np
import matplotlib.pyplot as plt
# 초기 상태와 공분산 설정
x_hat = np.array([0, 0]) # 초기 예측 상태 [x, x_dot]
P = np.eye(2) # 초기 예측 공분산
Q = np.eye(2) * 0.01 # 프로세스 노이즈 공분산
R = np.array([[0.1]]) # 측정 노이즈 공분산
# 상태 및 측정 행렬 정의
A = np.array([[1, 1], [0, 1]]) # 상태 전이 행렬
H = np.array([[1, 0]]) # 측정 행렬
# 측정값 및 시간 설정
measurements = np.random.normal(loc=0, scale=0.1, size=100) # 가상의 측정값
dt = 1 # 시간 간격
# 결과 저장을 위한 리스트 생성
x_hat_list = []
x_list = []
# 예측 및 업데이트 단계 반복
for z in measurements:
# 예측 단계
x_hat_minus = np.dot(A, x_hat)
P_minus = np.dot(A, np.dot(P, A.T)) + Q
# 칼만 이득 계산
K = np.dot(P_minus, H.T) / (np.dot(H, np.dot(P_minus, H.T)) + R)
# 업데이트 단계
x_hat = x_hat_minus + np.dot(K, (z - np.dot(H, x_hat_minus)))
P = np.dot((np.eye(2) - np.dot(K, H)), P_minus)
# 결과 저장
x_hat_list.append(x_hat[0])
x_list.append(x_hat_minus[0])
# 차트 그리기
plt.figure(figsize=(10, 5))
plt.plot(measurements, label='Measurements', color='blue', marker='o')
plt.plot(x_hat_list, label='Estimated State', color='red')
plt.plot(x_list, label='Predicted State', color='green', linestyle='--')
plt.xlabel('Time')
plt.ylabel('Position')
plt.title('Extended Kalman Filter: Position Estimation')
plt.legend()
plt.grid(True)
plt.show()Result
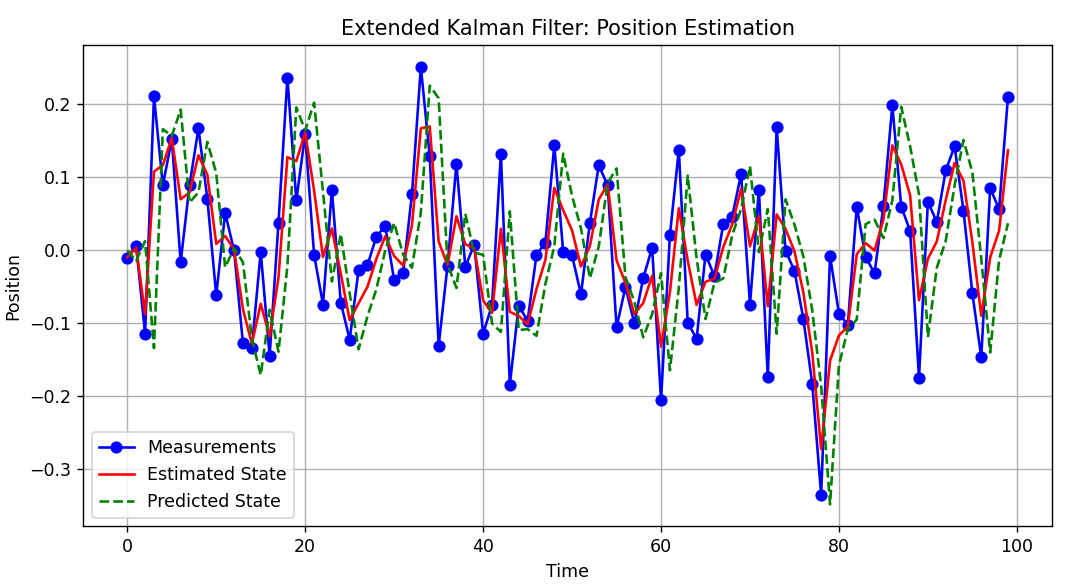
결과 차트와 같이 예측-업데이트를 반복함에 따라 상태를 지속적으로 추정이 가능하다.
자율주행 분야에서 많이 사용하는 기본적인 알고리즘인 만큼 이해를 확실히 하고 가자.
