앞서 살펴봤던 페이징 기법에서 고민해봐야 할 문제가 남아있다. 페이지 수와 페이지 프레임 수의 불일치하다면 어떻게 해야 할까? 페이지의 수가 더 많다면 일부 페이지들은 물리 메모리에 적재할 수 없을 것이고, 페이지 프레임의 수가 더 많다면 남아도는 페이지 프레임들을 활용할 방법을 찾아야 한다는 것이다.
페이지의 수가 더 많다면, 한 프로세스의 모든 주소 공간을 물리 메모리에 전부 다 담을 수 없다. 여러 프로세스가 물리 메모리를 공유한다면, 문제는 더 심화될 것이다. 이를 방지하고 공간 활용을 하기 위해 HDD나 SSD와 같은 메모리 계층 구조 상에서 하위 장치 들을 이용하면 방법이 있다.
🔥 Swap Space (스왑 공간)
가장 먼저할 일은 디스크에 페이지의 내용이 저장될 하위 메모리 계층의 저장 공간을 확보하는 것이다. 이를 "Swap Space(스왑 공간)" 이라고 부른다. 스왑 공간이라고 불리는 이유는 페이지 내용을 메모리에서 밖으로 내보내고(swap-out), 페이지 내용을 스왑 공간에서 메모리 안으로 가져오는 연산(swap-in)을 수행하기 때문이다. 스왑 공간을 사용하면 경제적으로 넓은 가상 메모리 공간을 사용하는 것이 가능해진다. 아래 예시를 보자.
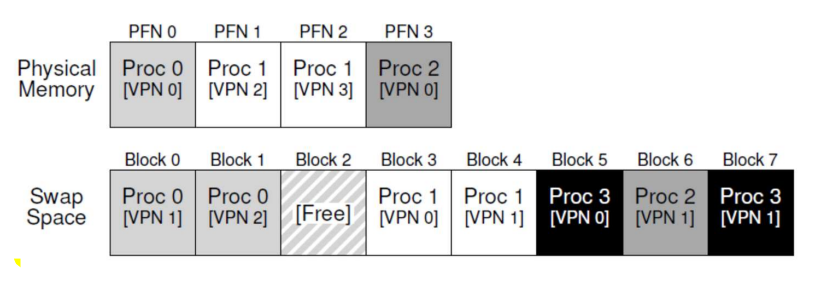
보다시피, 물리 메모리와 스왑 공간에는 각각 4개의 페이지와 8개의 페이지를 위한 공간이 존재한다. 위 그림에서는 3개의 프로세스(Proc 0, Proc 1, Proc 2)가 물리 메모리를 공유하고 있다. 이들 중 몇 개의 유효한 페이지들만 메모리에 올려 놓았으며 나머지 페이지들은 디스크에 swap-out 되어 있다. 네 번째 프로세스(Proc 3)의 모든 페이지들은 디스크로 스왑 아웃되어 있기 때문에 현재 실행 중이 아닌 것을 확인할 수 있다. 이처럼, "스왑 공간을 이용하면 시스템에 실제 물리적으로 존재하는 메모리 공간보다 더 많은 공간이 존재하는 것처럼 가장할 수 있다."
추가적으로, HDD와 SSD와 같은 Backing Store의 활용 방식에는 "정적 스왑"과 "동적 스왑"이 있다. 페이지가 저장된 위치를 참조하기 위해 주소가 필요한데, 전자의 방식으로는 고정 위치로 관리가 간단하지만, 여유 공간 활용이 어렵다는 단점이 있다. 후자의 경우에는 매핑을 통해 여유 공간의 유동적인 공간 관리가 가능하지만, 별도의 관리 자료구조(Mapping Table)가 필요하다.
👉 Present Bit의 활용
Swap 연산으로 인해, Present bit의 활용이 가능하다. 먼저 메모리가 참조되는 과정을 가볍게 떠올려보면, 프로세스가 가상 메모리 참조를 생성하고, 하드웨어는 메모리에서 원하는 데이터를 가져오기 전에, 가상 주소를 물리 주소로 변환시킨다. 하드웨어는 먼저 가상 주소에서 VPN을 추출한 후에 TLB에 해당 정보가 있는지 검사한다. 만약 hit가 되면 물리 주소를 얻은 후에 메모리로 가져온다.
만약 VPN을 TLB에서 찾을 수 없다면 하드웨는 페이지 테이블의 메모리 주소를 파악하고, VPN을 인덱스로 하여 원하는 페이지 테이블 항목(PTE)을 추출한다. 해당 PTE가 유효하고, 관련 페이지가 물리 메모리에 존재하면 하드웨는 PTE에서 PFN 정보를 추출하고, 그 정보를 TLB에 탑재한다. 이후 명령어를 재실행하면 TLB에서 hit됨을 확인할 수 있다.
하지만, 하드웨어가 PTE에서 해당 페이지가 물리 메모리에 존재하지 않는다는 것을 표현해야 하는데, 여기서 하드웨어는 Present Bit를 활용해서 각 PTE에 어떤 페이지가 존재하는지를 표현할 수 있다. Present bit가 1이라면, 물리 메모리에 해당 페이지가 존재한다는 것이고 위에 설명한 대로 동작한다. 비트가 만약 0이라면, 메모리에 해당 페이지가 존재하지 않고 디스크 어딘가에 존재한다는 것을 말하고 이를 확인하는 작업이 필요하다. 만약 이런 상황, 즉 물리 메모리에 존재하지 않는 페이지에 접근하면, "Page fault" 가 발생한다.
❓ OS가 페이징에 관여하는 4가지 경우 (참고)
프로세스가 생성되었을 때
프로세스가 실행 중일 때
Page fault가 발생했을 때
프로세스가 종료되었을 때
👉 Page fault의 처리 (하드웨어 vs 소프트웨어)
하드웨어 관점 : VA에서 VPN을 계산한 후, TLB를 체크한다. 만약 TLB hit면 offset을 반영해서 PA를 확보하고, TLB miss면 페이지 테이블을 참조해서 PTE를 확보하고 각종 flag를 검사하여 관련 예외가 발생한다. 이 예외 중 Present bit가 0이면 페이지 폴트가 발생한다는 것이다.
소프트웨어 관점 : OS는 페이지 폴트 처리를 위해 "Page fault handler"를 정의한다. 그리고 물리 메모리 중 비어 있는 페이지 프레임을 찾는다. 만약 있다면, 찾아낸 페이지 프레임을 fault가 발생한 페이지로 할당하고 디스크에서 페이지 내용을 복사한 후, 명령어를 재실행한다. 없다면, 다시 말해 메모리가 꽉 찬 상태면, 페이지 교체 혹은 방출 후 명령어를 재실행한다.
❓메모리가 다 찬 상태
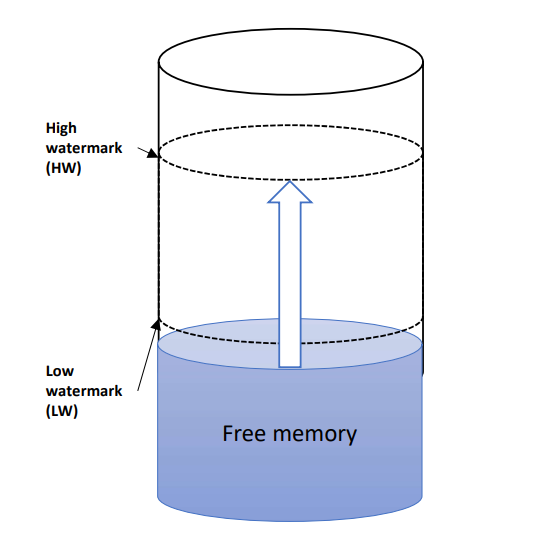
OS는 정말 여유 메모리가 완전히 없을 때 페이지 교체를 수행할까? 실제로는, "여유 메모리의 Watermark" 를 활용한다. 이는 여유 메모리를 High watermark(여유 공간의 최댓값), Low watermark(여유 공간의 최솟값)로 표현하고, 가용 page의 수로 측정하는 방식 이다. 예를 들어, 가용 페이지의 수가 여유 공간의 최솟값(LW)보다 작다면, 여유 공간의 크기가 최댓값에 이를 때까지 페이지를 "Swap daemon" 혹은 "Page daemon" 이라고 불리는 쓰레드가 제거한다.
그렇다면, 이제 교체/방출할 페이지를 어떻게 선정하느냐에 대한 문제가 남아 있다. 페이지 폴트에 의한 Swap 처리는 느린 장치 접근으로 인한 성능 부담이 크다. 따라서 교체/방출할 페이지는 신중히 선택되어야 한다. 아래 정책들을 살펴보자.
1. Optimal replacement policy
이 정책의 핵심은 가장 나중에 접근될 페이지를 교체하는 것 이다.
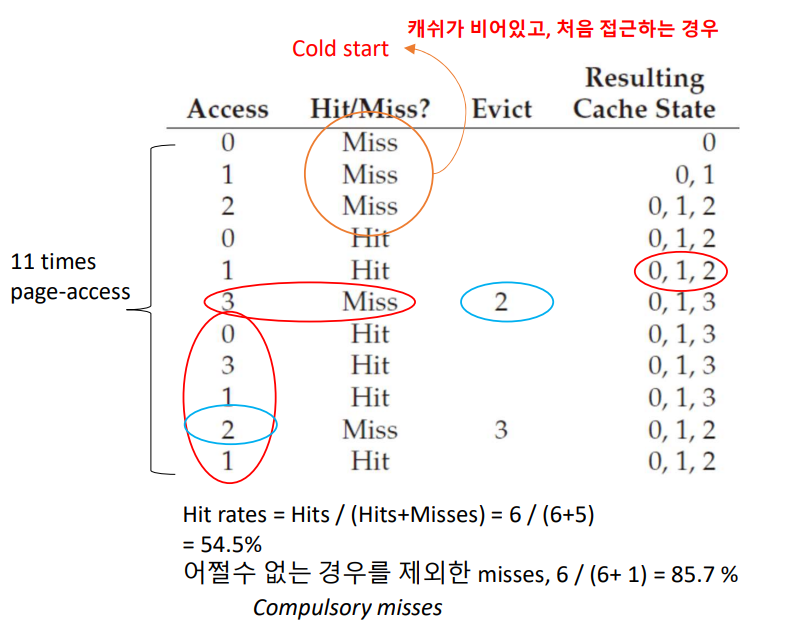
간단하지만, 가장 나중에 접근하게 될 것이라는 사실을 미리 알기는 어렵기 때문에 실제 구현은 어려운 이론적인 정책이다. 현실적인 방안들이 최적에 얼마나 가까운지 비교를 위해 주로 사용된다.
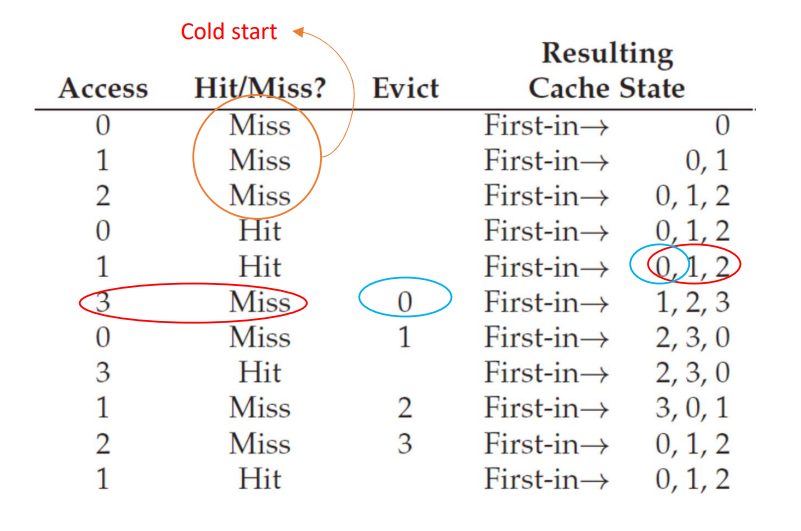
2. FIFO policy
말 그대로 먼저 들어온 것이 먼저 나가는 선입선출 방식 으로 페이지를 교체하는 방법이다. 구현이 간단한 것이 큰 장점이다.
3. Random policy
이 방식은 Memory pressure가 있을 때, 페이지를 무작위로 선택 해서 교체하는 방법이다. 이 방법도 구현이 간단하다. 시도 수를 충분히 늘리면, 경우에 따라 Optimal에 근접한다.

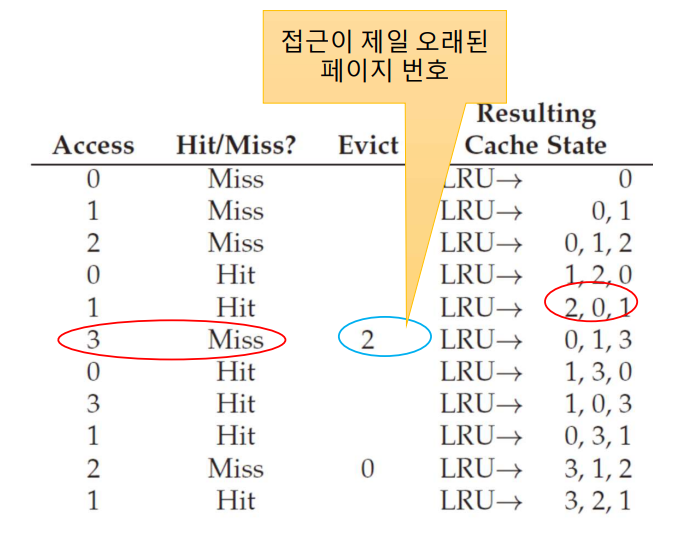
4. LRU policy
앞서 살펴봤던 FIFO 방식과 Random 방식에는 문제점이 있는데, 중요하거나 자주 참조되는 페이지임에도 방출될 수도 있다는 것이다. 이에 따라 페이지의 사용성을 고려한 교체 전략이 필요하다. 그 대안으로 LRU 방식이 있는데 페이지의 사용 빈도(Frequency) 를 활용해서 지역성 원칙(Locality) 에 따라 자주 사용된 페이지의 재활용 가능성이 높다는 것을 이용하는 것이다. 다시 말해, 과거의 페이지 사용 이력을 활용하여 가까운 미래의 사용성을 유추한다는 것이다.
👉 Workload에 따른 성능 비교
Locality가 없는 Workload : 모든 메모리 참조에서 랜덤한 페이지를 접근한다. 적재시킬 용량을 늘려도 Hit rate의 증가가 크게 좋아지지 않고, 모든 정책이 Optimal에 근접하지 않는다.
80-20 Locality of Workload : 페이지 참조의 80%는 20%의 hot page를 생성한다. 그 20%는 나머지 80%를 참조만 한다. Locality에 따라 적재 공간의 효율성이 증대하고, 이 경우에는 LRU 방식이 Optimal에 근접한다.
Looping-sequential Workload : 이 Workload는 50개의 페이지들을 순차적으로 참조하는 방법으로 캐시 크기가 50 이하로 충분치 않을 때는 모두 miss이고, 이후에는 모두 hit이다. 루프가 존재하나, 메모리 참조의 양상에 따라서, LRU이 효과가 없는 경우도 존재한다. 오히려 Random 방식이 Optimal에 근접한다.
❓ Approximating LRU
LRU는 실제 구현이 어렵다. 왜나하면, 최근성(Recency)을 평가하려면 각각의 페이지 참조마다 타이머를 두어야 하기 때문이다. 그리고 참조가 되었는지 혹은 사용이 되었는지를 나타낼 bit(Reference Bit or Used Bit)가 필요하다. 따라서 LRU를 구현하기 위해서는 LRU를 추정하는 기법이 필요하다. 대표적인 기법으로는 Clock Algorithm이 있다.
