페이징은 방법에서는
데이터로의 접근이 페이지 테이블에 한 번, 물리 메모리 내의 데이터에 한 번씩 항상 두 번의 메모리 접근을 거쳐야 한다.이는 메모리 접근 속도를 크게 떨어뜨리는 문제점이 있다. 가상 주소에서 물리 주소로의 주소 변환을 위해 메모리에 존재하는 매핑 정보를 읽어 오는, 즉 페이지 테이블 접근을 위한 메모리 읽기 작업은 엄청난 성능 저하를 유발한다.
🔥 TLB (Translation-Lookaside Buffers)
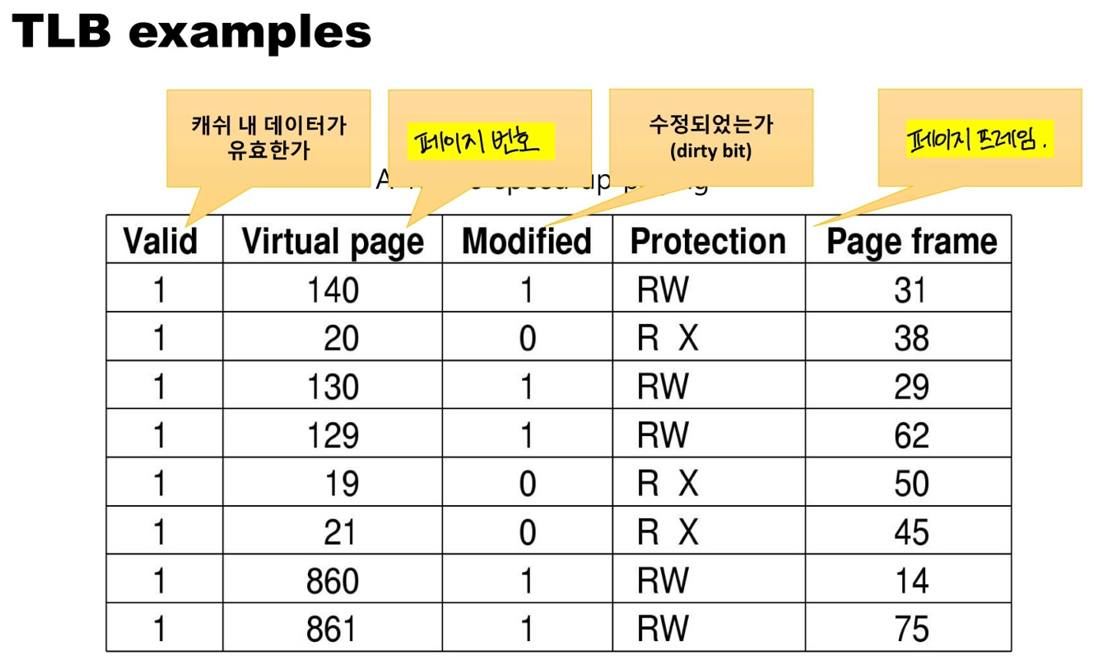
이를 해결하기 위해 "Translation-Lookaside Buffers(TLB)" 가 도입되었다. TLB는 MMU의 일부로 주소 변환 결과를 캐시 메모리(메인 메모리보다 고성능)에 저장한다. 페이지 테이블을 이용해 변환된 주소를 TLB에 저장해 두면, 다음 접근 시에는 TLB에 저장된 값을 이용해 빠르게 변환된 주소를 얻을 수 있다.
정리하자면, TLB의 결과는 가상 주소의 물리 주소 변환 결과이다. MMU와는 다르게 주소 변환을 위해 추가적인 메인 메모리의 페이지 테이블 접근을 하지 않는다.
👉 TLB의 제어 흐름
1 VPN = (Virtual & VPN_MASK) >> SHIFT
2 (Success, TlbEntry) = TLB_Lookup(VPN)
3 if (Success == True) // TLB 히트
4 if (CanAccess(TlbEntry.ProtectBits) == True)
5 Offset = VirtualAddress & OFFSET_MASK
6 PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
7 Register = AccessMemory(PhysAddr)
8 else
9 RaiseException(PROTECTION_FAULT)
10 else // TLB 미스
11 PTEAddr = PTBR + (VPN * sizeof(PTE))
12 PTE = AccessMemory(PTEAddr)
13 if (PTE.Valid == False)
14 RaiseException(SEGMENTATION_FAULT)
15 else if (CanAccess(PTE.ProtectBits) == False)
16 RaiseException(PROTECTION_FAULT)
17 else
18 TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
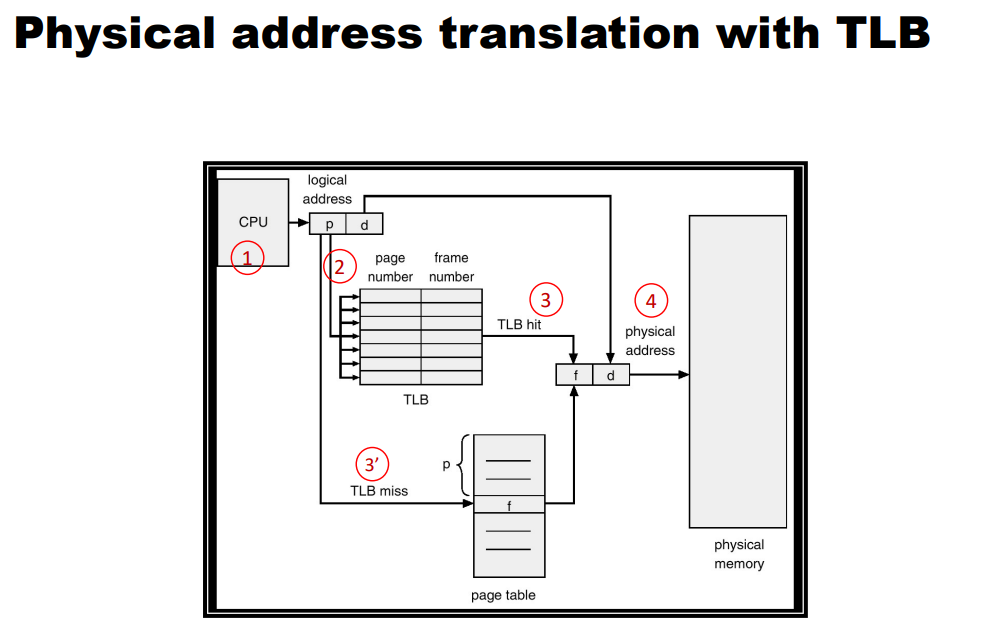
19 RetryInstruction()위 코드는 가상 주소 변환이 이루어지는 과정을 대략적으로 나타내고 있다. 주소 변환부가 단순한 선형 페이지 테이블과 하드웨어로 관리되는 TLB로 구성되어 있다. 하드웨어 부분의 알고리즘은 아래와 같이 동작한다.
먼저, 가상 주소에서 가상 페이지 번호(VPN)을 추출한 후(= 1번 라인), 해당 VPN의 TLB 존재 여부를 검사한다(= 2번 라인). 만약 존재하면 TLB 히트 이고 TLB가 변환 값을 갖고 있다는 것을 뜻한다. 이제 해당 TLB 항목에서 페이지 프레임 번호(PFN)을 추출할 수 있다. 해당 페이지에 대한 접근 권한 검사가 성공하면(= 4번 라인), 그 정보를 원래 가상 주소의 Offset과 합쳐서 원하는 물리 주소(PA)를 구성하고, 메모리에 접근할 수 있다(= 5~7번 라인).
반면, TLB에 변환 정보가 존재하지 않는다면(TLB 미스) 할 일이 많다. 하드웨어가 변환 정보를 찾기 위해서 페이지 테이블에 접근하며(= 11~12번 라인), 프로세스가 생성한 가상 메모리 참조가 유효하고 접근 가능하다면(= 13, 15번 라인), 해당 변환 정보를 TLB로 읽어들인다(= 18번 라인). 매우 시간이 많이 소요되는 작업이다. 왜냐면 페이지 테이블 접근을 위한 메모리 참조가 있기 때문이다(= 12번 라인). TLB가 갱신되면 하드웨어는 명령어를 재실행한다. 이번에는 TLB에 변환 정보가 존재함으로, 메모리 참조가 빠르게 처리된다.
🔥 Multi-level Page Table
시스템의 발전에 따라 가상 주소 공간도 매우 큰 용량을 요구하게 되었다. 그로 인해 페이지 테이블의 크기가 커지고 그 차지하는 공간에 의해 페이징이 잘 이루어질 수 없었다. 페이지 테이블 또한 메모리 내 존재하므로, 일정 크기를 점유했고 이에 대한 해결책이 바로
"Multi-level Page Table"이다. 직접 페이지 테이블을 참조하는 대신 중간 매핑 테이블을 둬서 간접 참조를 수행하는 것이다.
일단 페이지 테이블을 페이지 크기의 단위로 나눈 후, 페이지 테이블의 페이지가 유효하지 않은 항목만 있으면, 해당 페이지를 할당하지 않는다. 예를 들어, 32비트의 가상 주소 공간과 페이지 크기가 4KB(=2의 12제곱), PTE의 크기가 4바이트일 경우, 페이지의 개수(= PTE 개수)를 나타내는데 필요한 비트는 20비트(32-12 = 20)이므로 페이지의 개수는 2의 20제곱개가 있다. 따라서 페이지 테이블의 크기는 PTE 개수 X PTE 크기 = 1M X 4bytes = 4MB 임을 계산할 수 있고, 이는 프로세스마다 늘 메모리에 4MB씩 필요하다는 소리다.
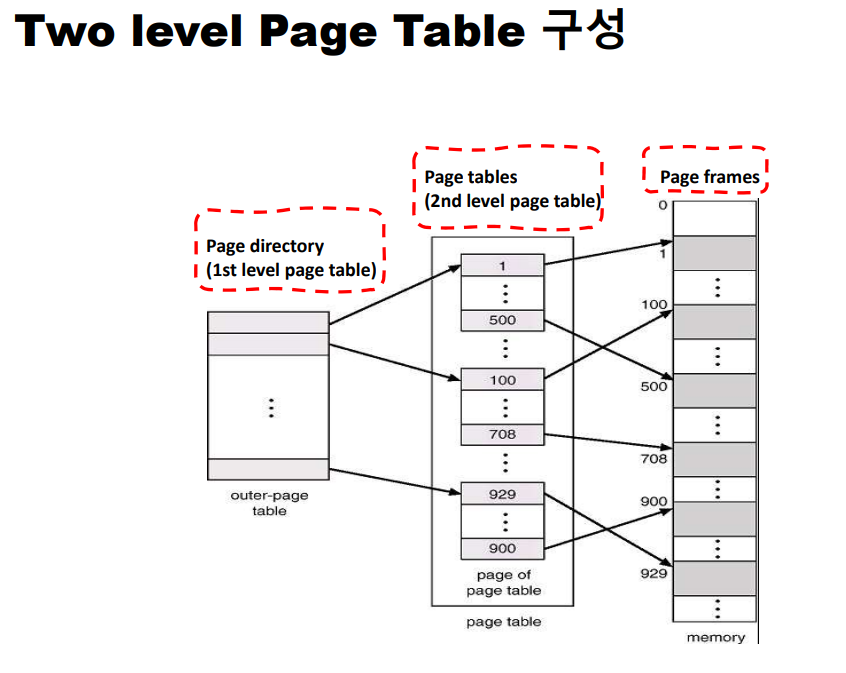
반면, 최대 2레벨로 구성된 Multi-level page table인 Two level page table 을 생각해보자. First level page table(= page directory)을 하나 더 둬서 페이지 테이블을 가리키도록 하는 것이다. 20비트를 차지하는 페이지 번호를 다시 10비트의 페이지 테이블 번호와 10비트 페이지 번호로 나누는 것이다. 이렇게 나눔으로써 얻는 이점이 사용하지 않는 메모리 공간을 위해 페이지 테이블의 일부를 할당하지 않을 수 있다는 것이다.
아래 그림들을 참고하자.

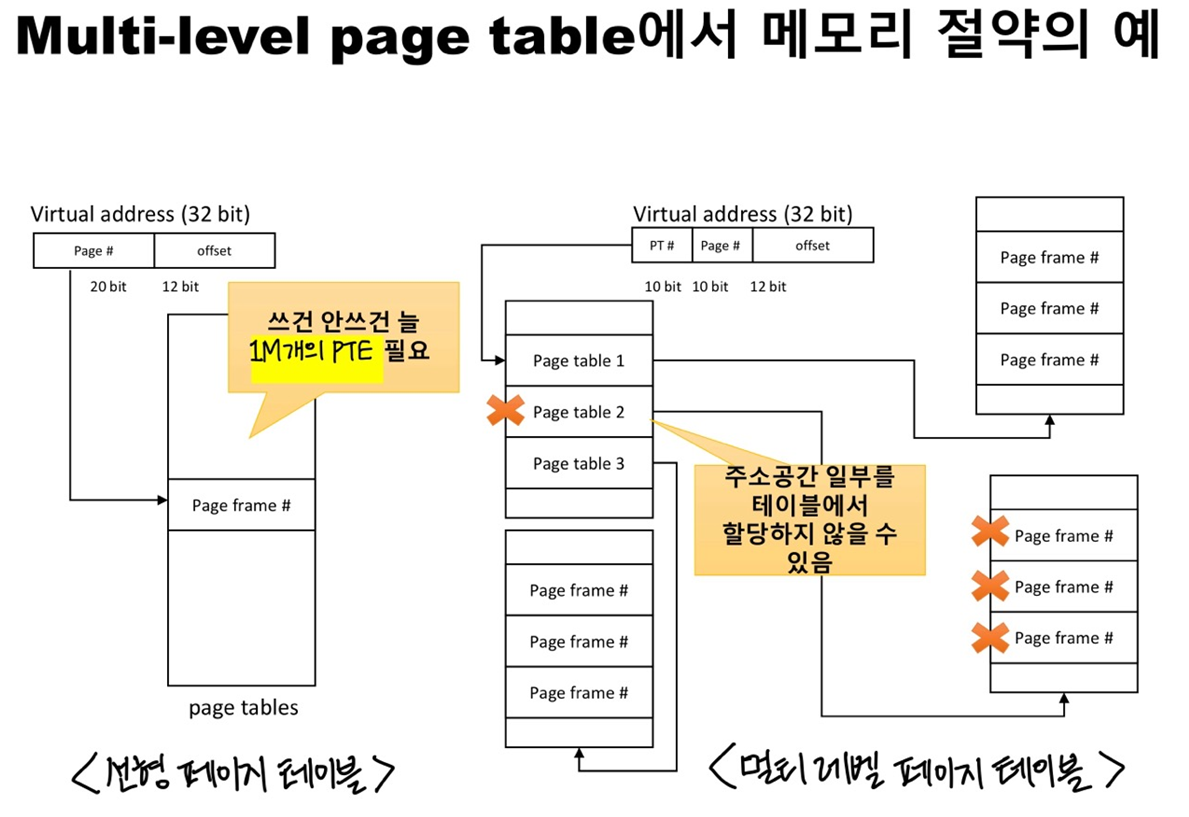
👉 Memory size for Page Tables
단일 페이지 테이블 의 크기는 PTE의 개수 X PTE의 크기 로 계산할 수 있다. 2레벨 페이지 테이블 에서의 페이지 디렉터리의 크기는 PDE의 개수 X PDE의 크기 이고, 페이지 테이블의 크기는 PTE의 개수 X PTE의 크기 이며, 전체 메모리의 크기는 페이지 디렉터리의 크기와 할당된 페이지 테이블의 크기를 합한 값이다. 다중 레벨 페이지 테이블 에서는 각각의 레벨에서의 PTE의 개수 X PTE의 크기 를 계산하고 모든 레벨의 페이지 테이블의 크기를 더하면 최종 메모리 크기를 알 수 있다.
🔥 역 페이지 테이블 (Inverted Page Table)
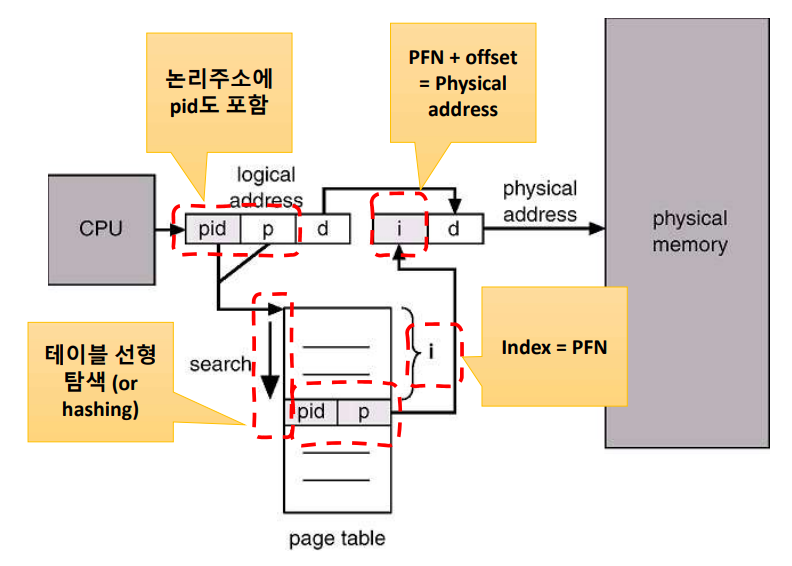
기존에는 페이지 번호(PN)을 이용해서 페이지 프레임 번호(PFN)를 검색했었다. 반면, 이 방법은 PFN와 Page ID를 이용하여 PN을 검색하는 방법 이다. 여기서 Page ID는 프로세스 식별자(PID)와 페이지 번호의 조합이고, 테이블에서 Page ID를 발견하면, 해당 페이지 프레임을 logical address 공간으로 매핑한다.

역 페이지 테이블은 시스템 전체에 하나의 페이지 테이블을 둔다. 보다시피 페이지 테이블 인덱스는 페이지 프레임 번호(PFN)이고 페이지 테이블의 내용은 프로세스 식별자(PID)와 페이지 번호(PN)이다. 메모리 주소 참조시, 프로세스 번호, 페이지 번호, Offset을 모두 참조한다. 역 페이지 테이블의 장점은 보다 적은 용량을 차지한다는 점이고, 단점은 페이지 테이블의 검색 시간이 증가한다는 것이다. 하지만 해시 테이블을 사용해서 단축이 가능하다.