안녕하세요. 오랜만에 포스팅을 하게 되었습니다. 한달동안 조금 바쁜일이 있어 쓰지 못했네요.
오늘 포스팅할 주제는 Randomised Experiments를 통해 Association로 Causal Effect를 추정하는 방법에 대해 알아보겠습니다.
이 포스팅은 원 저자분의 글의 흐름에 맞게 제가 이해한 바를 정리한 것으로 원글의 Section 구분대로 글을 써내려가겠습니다.
출처: Causal Inference for the Brave and True (https://matheusfacure.github.io/python-causality-handbook/)
The Golden Standard
이전 포스팅에서 Association이 Causation과 어떻게 다른지 알아봤습니다.
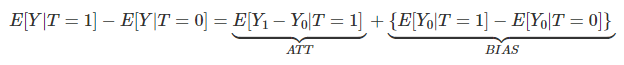
이 식을 통해서 Bias가 0 인경우 Association은 Causation이 되는데요. 이때 이 식에서 간단히 알 수 있듯이 인 경우 입니다.
조금 더 의미상으로 해석해보면, 실험군과 대조군이 동일한 상황에서 Treatment가 적용되는 경우라고 볼 수 있습니다.
이번 포스트에서는 이러한 편향을 없앨 수 있는 Randomised Experiments를 살펴보겠습니다.
- Randomised Experiments란 Treatment를 정말 무작위하게 적용하는 것입니다.
- 여기서 꼭 실험군과 대조군의 비율을 5:5로 맞출 필요는 없습니다. (어느정도 크기의 표본만 확보가 된다면 비율은 중요하지 않을 것 입니다.)
이러한 무작위 배정을 수학기호로 나타낸다면 로 나타낼 수 있습니다. Treament를 하든 안하든 그 잠재적인 결과는 항상 독립적이라는 것이죠!
이 말이 처음엔 다소 애매합니다.. 저자분께서도 처음에 어려웠다고 말씀하시고, 물론 저도 처음엔 이게 와닿지 않았습니다. 그래서 조금 더 자세하게 설명한다면, Treament가 결과에 효과가 없음을 말하는 것이 아닙니다. 결과에는 당연히 효과가 있기를 기대하고 있지만, 중요한 것은 잠재적인 결과에는 영향을 미치지 않는다는 것이죠!
이러한 독립성을 확보해주게 된다면

이 성립하게 됩니다. 이를 통해 Bias값은 0이 되고,
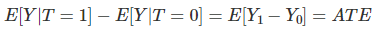
Association을 통해 Causal Effect를 측정할 수 있습니다!
In a School Far, Far Away
이 섹션에서는 비대면 수업을 예시로 비대면수업과 대면수업과의 ATE를 추정하는 과
간단하게 비대면수업을 시행한 경우와 그렇지 않은 경우 학생들의 성적을 비교할때에
- 만약 비대면 수업을 듣는 학생들이 기본적으로 조금 더 공부를 잘하는 학생이라고 해봅시다. 그러한 경우 으로 편향이 발생하게 됩니다.
- 반대로 비대면 수업을 듣는 학생이 공부 이외에 일을 해야하는 환경이라면, 비대면 수업을 수강하는 학생은 대체로 학업성적이 좋지 못할 것입니다. 이러한 경우 으로 편향이 발생합니다.
즉, 간단하게 비교해볼 수 있지만, 편향의 여지가 있기때문에 함부로 Association을 인과관계 효과라고 생각할 수는 없습니다.

이 그림이 아주 잘보여주고 있는데요! 간단한 비교는 편향의 위험이 항상 기다리고있습니다...
인과관계 효과를 정확히 측정하기 위해서는 Treatment가 무작위하게 적용되도록 실험을 통제하는 것입니다.
The Ideal Experiment
무작위 통제 실험은 인과 관계의 효과를 측정하는데에 가장 신뢰할 수 있는 방법입니다. 하지만 임산부의 흡연에 따른 출생 시 아기 체중에 미치는 효과를 추정하는 실험을 할때에, 윤리적인 문제로 이러한 실험은 무작위로 설계할 수 없습니다.
그렇지만, 요즘 온라인상에 많은 테스트가 이루어지고 있으며 이러한 맥락에서, 이상적인 실험임을 고려하거나 설계해 볼만한 가치는 있을 것으로 생각됩니다.
The Assignment Mechanism
Randomised Experiments에서 할당 메커니즘은 무작위이겠지만, 그렇지 않은 경우 알 수 없습니다. 다음에 나올 포스트들에서 다루겠지만, 모든 인과관계 추론은 할당 메커니즘을 식별하고, 조정하고자 할 것입니다. 이러한 메커니즘을 파악한다면 Randomised Experiments가 아니더라도 인과관계를 식별할 수 있다고합니다!!
인과 관계 추론에서 일반적으로 X가 Y의 원인이거나, X와 Y의 공통적인 원인이 되는 변수 Z가 존재해서 X와 Y의 상관 관계가 직접 연결된 상관관계가 아니라는 두 가지 방식으로 해석될 수 있습니다. 이러한 이유 때문에 할당 메커니즘을 정확히 알면 훨씬 더 설득력 있는 인과 관계에 대한 답을 얻을 수 있다고 합니다. 인과 추론을 하기 위해서는 일반적으로 ML알고리즘을 적용하는 것과 달리 해당 데이터를 생성하는 메커니즘에 대해 더욱 고민해봐야 합니다.
