RCNN 은 Regional Proposal + CNN 으로 Rich feature hierarchies for accurate object detection and semantic segmentation라는 논문에서 제안한 객체 검출(Object Detection) 알고리즘입니다.
이 방법은 이전의 Pascal VOC에서 우수한 성능을 보인 다른 알고리즘 보다 더 좋은 성능을 보였다고 합니다. 또한 CNN을 이용한 초기의 객체 검출 알고리즘이기도 하죠.
저는 컴퓨터 비전을 공부해본 적 없지만, 이 논문을 읽으며 굉장히 흥미로워서 구현까지 해보게 되었습니다.
초보자의 관점에서 애매했던 부분과 구현에 있어 이해가 어려웠던 부분들을 정리해 보았고, RCNN에 대한 코드자료가 많이 없어서 직접 구현해보았습니다.
혹시 궁금하신 부분이나 틀린 부분이 있다면 댓글 달아주세요!
Object Detection
Object Detection 이란 단순히 이미지를 분류하는 것뿐만 아니라 객체의 위치를 찾아내는 것을 말합니다!

위 그림처럼 각각의 객체가 존재하는 위치와 분류까지 해내는 것이죠!
Problems
저자는 아래와 같은 두 가지 문제를 고민한 것으로 보였습니다.
-
Localizing objects with a deep network
-
Training a high-capacity model with only a small quantity of annotated detection data.
첫 번째는 "recognition using regions" paragidigm을 이용했다고 합니다. 이것이 어떤것을 말하는지 조금 모호한데 아마 regional proposal algorithm을 통해 region을 제안받고, 그 region에서 이미지를 분류한다라는 뉘앙스인 것으로 보입니다.
두 번째는 supervised pre-training 을 이용해서 극복하였습니다. 이 부분에 논문의 큰 기여가 있다고 생각되는데요. ILSVRC2012의 데이터를 통해 학습된 이미지 분류 CNN의 weight를 가져와 객체 검출에 이용한 것이죠. 뒤에서 상세히 알아보겠습니다.
Module Design

위 사진은 RCNN으로 제안된 모듈의 디자인입니다.
모듈의 시작 지점인 가장 바닥지점부터 설명해보면,
-
물체가 위치한 region을 찾습니다. (이 단계에서는 물체가 무엇인지 분류하지 않습니다.)
-
위에서 얻어진 region을 warp하여 같은 크기의 이미지로 만들어 냅니다.
-
같은 크기의 이미지를 CNN에 통과시켜 feature들을 얻습니다.
-
SVM들에 feature를 어떤 물체인지 분류하고 Bounding Box regression을 이용해 위치를 재조정해주는 과정을 통해 최종적으로 객체를 검출합니다.
Regional Proposal - Selective Search
논문에서 여러 최신 Regional Proposal 방법들을 소개하고 있습니다. ( objectness, selective search, category-independent object proposals 등)

RCNN은 이 중 selective search 알고리즘을 이용해 regional proposal 을 하고 있습니다.
Selective search 방법을 간단하게 설명하면,
-
색깔이나 질감, 사이즈 등을 통해 이미지를 나누고 유사성이 높은 region들을 합쳐 나갑니다.
-
이 과정에서 작은 크기부터 큰 크기까지의 regional proposal을 얻게 됩니다.
위 사진은 selective search의 과정을 보여주고 있는데요. 초록색 부분은 거의 참에 가까운 regional proposal 을 해주고 있습니다. 저 부분만을 이용하면 참 좋을 것 같은데요!
하지만 실제 아웃풋은 파란색 박스와 초록색 박스 모두 주어지게 됩니다.
아무튼 우리는 이 알고리즘을 통해서 많은 regional proposal 을 얻을 수 있습니다. 이 중 상당수는 background로 분류되어 버려질 것이고, 비슷한 객체를 보여주고 있다면 합쳐질 것이니까 regional proposal이 너무 많다고 걱정할 필요가 없습니다.
Image Warping

Regional proposal 이후에는 image warping을 진행합니다. image warping 이란 각기 다른 regional proposal을 일괄적인 크기로 바꾸어주는 것입니다. (RCNN에서는 224x224) 이렇게 바꾸어주어야 같은 CNN을 통과할 수 있으므로 image warping을 하는 것으로 보입니다.
하지만 저자는 여기서 단순히 regional proposal을 쓰는 것보다 주변 맥락(around context)을 어느 정도 고려해주는 것이 성능향상에 도움이 된다고 합니다. 논문의 저자는 regional proposal에 상하좌우로 16픽셀 정도를 더 고려해주었다고 합니다. (이미지의 바운더리를 넘어가는 경우에 평균값으로 대체해주었다고 합니다.)
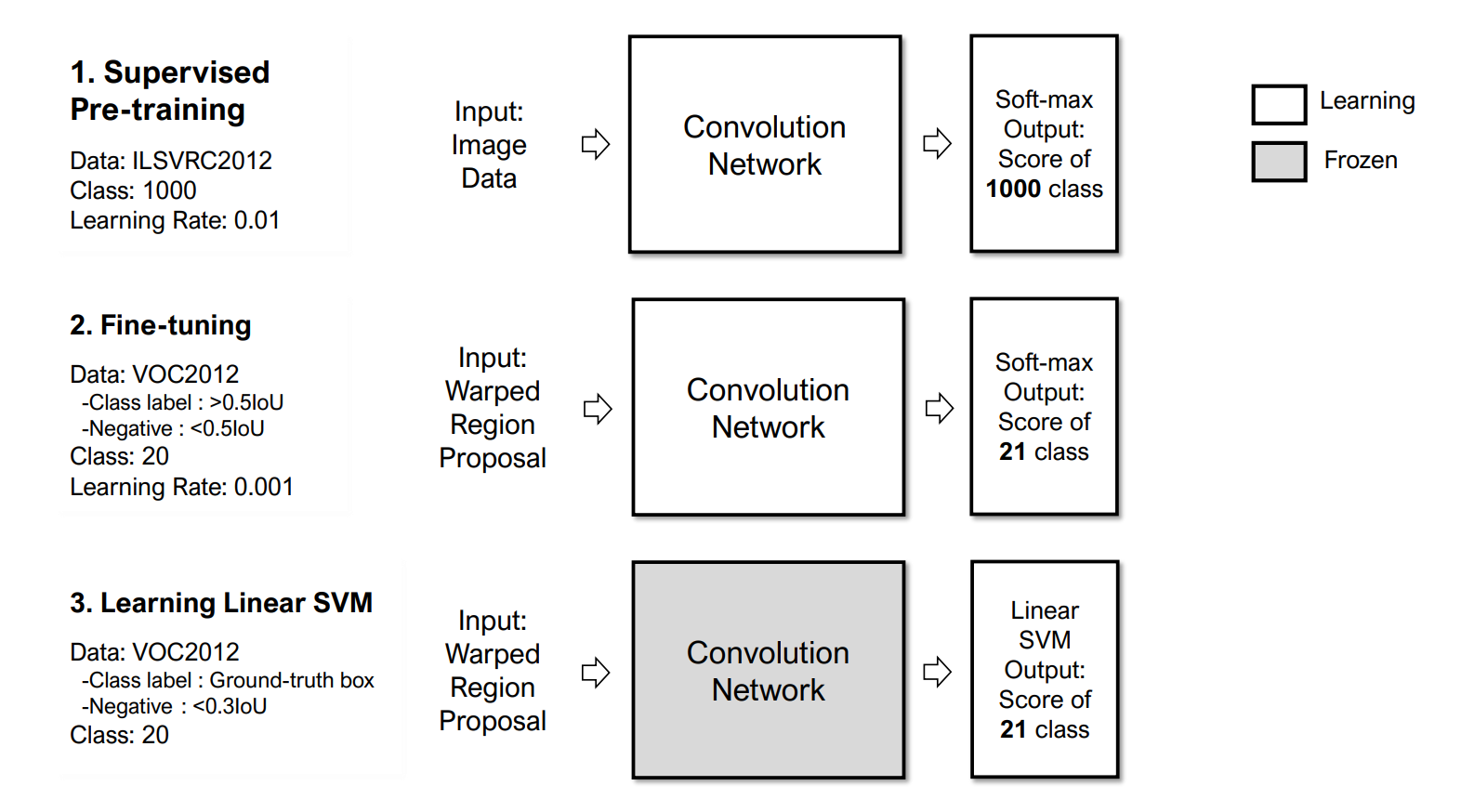
Supervised Pre-training & Domain-specific Fine-tuning
이제 warped image를 통해 CNN에 통과시켜 이미지를 분류할 차례입니다!
이 논문은 Pascal VOC 데이터를 이용하였는데 아무래도 Annotation이 되어있는 데이터의 수가 작다 보니 이를 극복하고자 하였는데요. ILSVRC2012로 학습된 CNN을 가져옴으로써 어느 정도 학습된 Network를 쓰게됩니다. (논문에서는 VGG-16을 사용하였고 비록 전체적으로는 다른 목적을 가졌지만, 이 부분에서는 이미지를 분류만을 목적으로 하기 때문에 이를 사용한 것으로 보입니다. )
하지만 이 CNN을 바로 사용하는 것은 조금 무리가 있겠죠. 그래서 우리가 원하는 domain에 맞추기 위해 다음과 같은 과정을 거쳐 domain-specific fine-tuning을 하여줍니다.
-
ILSVRC2012는 1000개의 클래스를 가졌기 때문에 1000개의 output 레이어가 존재하는데 이를 제거하고 우리가 원하는 21개의 분류 (20개의 클래스 + background) 레이어를 결합해 줍니다.
-
regional proposal 과 ground truth box와의 IoU (Intersection over Union) 값이 0.5 이상이면 ground truth box의 클래스로 라벨링하고 그 이하인 경우 background로 라벨링합니다.
-
negative 한 샘플이 압도적으로 많기 때문에 32개의 positive(모든 클래스에 대해)와 96개의 background의 regional proposal을 통해 최적화합니다. 여기서 SGD 를 learning rate 0.001로 적용합니다. (이는 pre-trained network가 0.01로 학습되었기 때문인데, 흔히 pre-trained network의 learning rate의 1/10으로 적용한다고 합니다.)
Training Linear SVMs
Domain-specific fine-tuning 이후에는 SVM들을 학습시켜줍니다.
갑자기 여기서 무슨 SVM이지..? 라는 생각을 많이 했습니다.
위에서 학습한 CNN의 결과로 regional proposal의 이미지를 분류할 수 있지만, labelling에서 IoU 0.5를 기준으로 두었습니다. 이것은 많은 positive proposal을 통해 오버피팅을 피하고자 사용되었으나, 모호한 표본에 대해 학습하게 된다는 단점이 있습니다.
이를 극복하기 위해 hard negative mining을 통해 softmax layer 직전의 layer의 특성들과 재정의된 라벨들을 학습하여 SVM들을 학습시켜줍니다.
- positive: Ground truth box
- negative: < 0.3IoU
모호한 부분(grey zone)을 제외하여 확실하게 학습해 버립니다! 또한 여기서 놓치지 말아야 할 것은, 제가 SVM's', SVM'들' 이라고 표현한 것은 각 클래스에 대해 OvR(One versus Rest)로 총 21개의 SVM을 학습시키기 때문입니다.
위 과정들을 쉽게 그림으로 나타내보았습니다.
Test-time Detection
위 과정들을 통해 학습을 하였으면, 이제 적용해봐야죠!
Test-time detection이란 실제 적용을 말하는 것으로 이전의 학습된 모델들을 가지고 적용을 해보아야 할 텐데요 다음과 같은 4개의 단계로 구성되어있습니다.
-
Selective search를 통해 2000개의 category-independent region proposal을 생성합니다.
-
학습된 CNN을 통해 고정된 길이의 특성벡터를 추출합니다.
-
linear SVM들을 통해 각 클래스의 점수를 매깁니다.
-
Non-maximum suppression을 적용합니다.
1번부터 3번까지는 저희가 학습한 모델을 사용하는 것이고 4번은 Non-maximum suppression ? 이라는 것을 사용합니다. 이것은 한 물체가 여러 박스로 검출되었을 때 하나로 합쳐주는 것으로 아주 간단합니다.
Non-maximum Suppression

좌측이 NMS를 적용하기 전, 우측이 적용 후입니다.
일정 기준이상의 score를 가진 bounding box들 중에서 클래스별로 분류된 바운딩 박스 중 가장 높은 바운딩박스와 IoU값이 일정 기준을 넘는 바운딩 박스를 제거해주면 됩니다.
Bounding-box Regression
마지막으로 Bounding-box regression으로 박스의 위치를 재조정시켜 주는 방법입니다. 이 방법을 통해 mAP기준에서 정확도를 유의미하게 향상시킬 수 있다고 합니다.
: regional proposal를 통한 bounding box / x,y : 중심, w,h: 너비와 높이
: ground-truth bounding box
라고 할때 다음과 같은 를 찾습니다.
여기서 는 중 하나이고 의 pool features 입니다. 또한 여기서 는 각각
으로 Ground truth 박스와의 위치, 크기 차이를 나타냅니다.
위의 학습된 를 이용해 를 계산하고 다음과 같은 계산으로 regional proposal의 위치와 크기를 재조정해줍니다.
Python code
위 글자로 들어가면 제 Github으로 연결됩니다. 열심히 튜토리얼 찾아가면서 작성해보았습니다. CNN구조를 짜는 것은 VGG16을 가져와서 이렇게 저렇게 손보면되지만 CNN 전후로 처리해야할 작업들이 많이 있었네요.
제 포스트를 봐주셔서 감사합니다!
