🤖 AI 챗봇의 '기억' 작동 방식
LLM(거대 언어 모델) 자체는 '기억'이 없습니다(Stateless). 매번의 API 호출은 완전히 독립적입니다. "안녕"이라고 말한 뒤 "내 이름이 뭐야?"라고 물으면, LLM은 "안녕"이라는 이전 대화를 모르기 때문에 대답할 수 없습니다.
'기억'을 구현한다는 것은 "이전 대화 내용을 현재 프롬프트에 포함시켜서" LLM에게 '문맥(Context)'을 함께 전달하는 것을 의미합니다.
핵심 질문은 "이전 대화 중 어떤 것을 어떻게 프롬프트에 넣을 것인가?"입니다.
1. 기본 기억 방법: 프롬프트에 '연결'하기
가장 고전적이고 기본적인 방법입니다.
A. 전체 대화 내역 전달 (ConversationBufferMemory)
- 작동 방식: 사용자와 AI가 나눈 모든 대화 기록을 순서대로 프롬프트에 전부 집어넣습니다.
- 예시 프롬프트:
Human: 안녕? AI: 안녕하세요! Human: 오늘 날씨 어때? AI: 서울은 맑습니다. Human: 어제 내가 뭐 물어봤는지 기억해? AI: ... (이제 LLM이 '오늘 날씨'를 물어본 것을 보고 대답함)
- 장점: 완벽한 기억력.
- 단점: 대화가 길어지면 프롬프트가 컨텍스트 창(Context Window) 한계 (예: 4K, 32K 토큰)를 초과하고, API 비용이 폭발적으로 증가합니다.
예시 코드
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# 메모리 포함 체인 생성
memory = ConversationBufferMemory()
chain = ConversationChain(llm = llm, memory=memory)
# 대화 시작
print(chain.run("안녕? 나는 기영이야.")) # 기영아 안녕
print(chain.run("내 이름이 뭐라고?")) # 너의 이름은 기영이야.B. 최근 대화만 전달 (ConversationBufferWindowMemory)
- 작동 방식:
A의 단점을 보완. 전체 대화가 아닌, 최근k개의 대화만 잘라서 프롬프트에 넣습니다. (예: 최근 5번의 턴) - 장점: 토큰 한계와 비용 문제를 조절할 수 있습니다.
- 단점:
k개 이전의 중요한 정보(예: "내 이름은 OOO이야")를 잊어버립니다.
예시 코드
from langchain.memory import ConversationBufferWindowMemory
# 최근 2턴만 기억하는 메모리
memory = ConversationBufferWindowMemory(k=2)
chain = ConversationChain(llm=llm, memory=memory)
# 대화
print(chain.run("나는 기영이야."))
memory.load_memory_variables({})
print(chain.run("내가 좋아하는 색은 파란색이야."))
memory.load_memory_variables({})
print(chain.run("나는 영화보는 것을 좋아해"))
memory.load_memory_variables({})
print(chain.run("지금 배고픈데 뭘 먹을까?"))
memory.load_memory_variables({})
print(chain.run("내가 누구라고?")) # 누군지 기억못함.
memory.load_memory_variables({})C. 대화 요약본 전달 (ConversationSummaryMemory)
- 작동 방식: 대화가 진행될 때마다, LLM을 이용해 이전 대화 내용을 요약합니다. 그리고 새 질문과 함께 '요약본'을 프롬프트에 넣습니다.
- 장점: 긴 대화도 압축해서 기억할 수 있습니다.
- 단점: 요약 과정에서 세부 정보가 손실될 수 있고, 요약을 위한 추가 LLM 호출 비용이 듭니다.
예시 코드
from langchain.memory import ConversationSummaryMemory
# 요약 메모리 생성 (요약용 LLM 필요)
memory = ConversationSummaryMemory(llm = llm)
# 체인 구성
chain = ConversationChain(llm = llm, memory = memory)
# 대화
print(chain.run("오늘은 운동하고, 친구랑 밥도 먹고, 강의도 들었어."))
print(chain.run("내가 오늘 뭐했는지 기억나?"))
print(chain.run("너는 어떻게 지냈어?"))
# 담긴 메모리 확인하기
memory.chat_memory.messages
# 내용 요약
print(memory.buffer)요약

2. 고급 기억 방법: RAG (검색) 기반 기억
최근 가장 많이 사용되는 방식이며, RAG(검색 증강 생성)의 원리를 대화 기억에 적용한 것입니다.
RAG 기반 기억 (VectorStore-backed Memory)
- 작동 방식:
- 모든 대화(Human/AI)를 Vector DB (예: Chroma)에 실시간으로 저장(임베딩)합니다.
- 사용자가 새 질문을 하면, 그 질문과 '가장 관련성 높은' 과거 대화 조각들을 DB에서 검색(Search)합니다.
- 프롬프트에 [최근
k개 대화] + [검색된 관련 과거 대화] + [새 질문]을 넣어 LLM에 전달합니다.
- 장점:
- 장기 기억: 대화가 아무리 길어져도 상관없습니다.
- 관련성: "3주 전에 말했던 내 프로젝트 이름 뭐야?" 같은 질문에도 3주 전의 관련 기록을 찾아와 대답할 수 있습니다.
- 효율성: 토큰 한계를 걱정할 필요가 없습니다.
- 단점: 구현이 다소 복잡하고, Vector DB가 필요합니다.
예시 코드
from langchain.vectorstores import Chroma
# split_texts, embedding_model 정의
...
# ChromaDB를 만들면서 저장
vectorstore = Chroma.from_texts(split_texts, embedding_model, persist_directory="./chroma_db")
query = "농촌 계몽운동에 대한 내용"
retrieved_docs = vectorstore.similarity_search(query, k=3)
# 결과 출력
print("검색 결과:")
for doc in retrieved_docs:
print(doc.page_content)
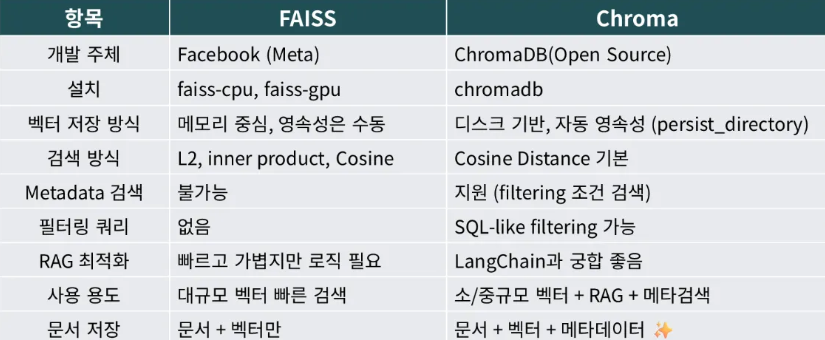
print('-'*200)💡 Chroma vs. FAISS: 간단 비교
둘 다 벡터를 저장하고 검색하는 핵심 역할을 하지만, 지향점이 약간 다릅니다.
- Chroma (ChromaDB):
- *"데이터베이스 (Database)"**에 가깝습니다.
- 벡터뿐만 아니라 메타데이터(문서 출처, 시간 등) 저장 및 필터링 기능을 기본으로 제공합니다.
- 데이터 저장, 관리, API 제공 등 RAG에 필요한 기능이 잘 갖춰져 있어 개발 및 프로토타이핑이 매우 편리합니다.
- LangChain, LlamaIndex 등과 통합이 쉽습니다.
- FAISS (Facebook AI Similarity Search):
- *"검색 라이브러리 (Library)"**에 가깝습니다.
- Meta(페이스북)에서 개발했으며, 오직 매우 빠르고 효율적인 벡터 검색(유사도 검색) 자체에만 초점을 맞춥니다.
- 수십억 개 단위의 초대규모 벡터를 처리할 때 최고의 성능을 보입니다.
- 하지만 FAISS 자체는 데이터를 영구 저장(persistence)하거나 메타데이터를 관리하는 기능을 직접 제공하지 않습니다. (사용자가 직접 파일로 저장/로드하거나, 다른 DB와 조합해서 써야 함)
예시 코드
from langchain.vectorstores import FAISS
# split_docs, embedding_model 정의
...
vectorstore = FAISS.from_documents(split_docs, embedding_model)
vectorstore.save_local("faiss_index") # 'faiss_index' 폴더에 저장됨
# 저장된 벡터DB를 로딩하기
new_vectorstore = FAISS.load_local(
"faiss_index",
embedding_model,
allow_dangerous_deserialization=True
)
new_docs = [
Document(page_content="조선시대의 교육 제도는 성균관 중심이었다.", metadata={"source": "추가"}),
Document(page_content="한국 전통 사회에서 글을 읽는 능력은 권력의 상징이었다.", metadata={"source": "추가"})
]
# 문서 추가
vectorstore.add_documents(new_docs)요약

3. 상태 저장소: MemorySaver의 역할
사용자님이 언급하신 from langgraph.checkpoint.memory import MemorySaver는 위 1, 2번과는 약간 다른 차원의 이야기입니다.
MemorySaver는 "기억을 프롬프트로 만드는 방법"이 아니라, "대화의 상태(State)를 어디에 저장(Persistence)할 것인가"에 대한 도구입니다.
MemorySaver(인메모리): 가장 기본. 대화 기록을 그냥 RAM(메모리)에 저장합니다. 챗봇 서버가 재시작되면 모든 대화 기록이 사라집니다. (테스트용)RedisSaver/PostgresSaver등: 대화 기록을 외부 DB(Redis, Postgres 등)에 저장합니다.
LangGraph 같은 에이전트 프레임워크에서 MemorySaver는 단순히 채팅 기록뿐만 아니라, 에이전트의 현재 작업 상태(State) 전체(예: 'A' 작업 완료, 'B' 작업 대기 중)를 저장하는 '체크포인터(Checkpointer)' 역할을 합니다.
📈 요즘 대세는?
- "RAG 기반 기억 (VectorStore) + 상태 저장소 (DB Checkpointer)"의 조합입니다.
- 단기 기억 (Window): 최근 3~5개의 대화는 프롬프트에 항상 포함시킵니다. (가장 즉각적인 문맥)
- 장기 기억 (RAG): 사용자의 질문과 관련성 높은 과거 대화 기록을 Vector DB에서 검색하여 프롬프트에 추가합니다.
- 대화 저장 (Persistence): 이 모든 대화 기록과 에이전트의 상태는
MemorySaver(혹은 LangChain의ChatMessageHistory인터페이스)를 통해 Redis나 Postgres 같은 외부 DB에 영구 저장합니다.
결론
단순한 챗봇은 '최근 대화만 기억(Window)'하는 방식을,
고급 챗봇이나 에이전트는 'RAG(검색)로 장기 기억'을 구현하고,
LangGraph를 쓴다면 MemorySaver를 이용해 이 모든 상태를 'DB에 저장'하는 것이 현재의 표준 방식입니다.
