안녕하세요. AICE 시험을 준비하며 꼭 알아야 할 머신러닝 핵심 개념들을 정리해 보았습니다.
1. 데이터 스케일링 (Scaling) 3대장
데이터를 모델에 학습시키기 전, 피처들의 단위를 맞춰주는 전처리 과정입니다. 왜 할까요? 만약 '키(cm)'와 '나이(세)'를 함께 사용한다면, '키'의 숫자 범위가 훨씬 커서 모델이 '키' 피처를 더 중요하다고 잘못 판단할 수 있기 때문입니다.
1) StandardScaler (표준화)
- 개념: 가장 널리 쓰이는 스케일러입니다. 각 피처의 평균(Mean)을 0, 표준편차(Standard Deviation)를 1로 변환합니다. (이를 Z-점수 정규화라고도 합니다.)
- 특징:
- 데이터가 정규분포(가우시안 분포)를 따른다고 가정할 때 효과가 좋습니다.
- 아웃라이어(이상치)에 민감하게 반응할 수 있습니다.
- 언제 쓸까?
- 대부분의 머신러닝 모델(특히 선형 회귀, 로지스틱 회귀, SVM 등)의 기본 스케일러로 사용하기 좋습니다.
- 데이터가 정규분포에 가까울 때.
from sklearn.preprocessing import StandardScaler
# 1. 스케일러 객체 생성
scaler_std = StandardScaler()
# 2. 데이터에 맞게 '학습(fit)'하고 '변환(transform)'
X_scaled_std = scaler_std.fit_transform(X)
print("StandardScaler 변환 결과:\n", X_scaled_std)2) MinMaxScaler (정규화)
- 개념: 모든 피처 값을 0과 1 사이의 값으로 압축시킵니다. (최솟값은 0, 최댓값은 1이 됩니다.)
- 특징:
StandardScaler와 달리 아웃라이어(이상치)에 매우 민감합니다. 예를 들어 [1, 2, 3, 100]이 있다면, 1, 2, 3은 0에 가깝게, 100은 1에 가깝게 매핑되어 버립니다.
- 언제 쓸까?
- 이미지 데이터(픽셀 값이 0~255 범위일 때)를 0~1 사이로 변환할 때.
- 데이터의 범위가 명확하게 정해져 있을 때.
- 주의: 아웃라이어가 있다면 사용에 유의해야 합니다.
from sklearn.preprocessing import MinMaxScaler
# 1. 스케일러 객체 생성
scaler_mms = MinMaxScaler()
# 2. 데이터에 맞게 '학습(fit)'하고 '변환(transform)'
X_scaled_mms = scaler_mms.fit_transform(X)
print("MinMaxScaler 변환 결과:\n", X_scaled_mms)3) RobustScaler (로버스트 스케일링)
- 개념: 이름(Robust)처럼 아웃라이어에 강건한 스케일러입니다. 평균/표준편차 대신 중앙값(Median)과 사분위 범위(IQR)를 사용합니다.
- 특징:
- 아웃라이어의 영향을 거의 받지 않고 데이터의 분포를 스케일링합니다.
- 언제 쓸까?
- 데이터에 아웃라이어(이상치)가 많다고 판단될 때 가장 우선적으로 고려합니다.
from sklearn.preprocessing import RobustScaler
# 1. 스케일러 객체 생성
scaler_rs = RobustScaler()
# 2. 데이터에 맞게 '학습(fit)'하고 '변환(transform)'
X_scaled_rs = scaler_rs.fit_transform(X)
print("RobustScaler 변환 결과:\n", X_scaled_rs)정리
| 스케일러 | 기준 통계량 | 이상치(Outlier) 영향 | 주요 사용처 |
|---|---|---|---|
| StandardScaler | 평균(0), 표준편차(1) | 민감함 | 일반적인 모델, 정규분포형 데이터 |
| MinMaxScaler | 최소~최대 → [0,1] | 매우 민감 | 이미지, 명확한 범위 |
| RobustScaler | 중앙값, IQR | 강건함 | 이상치 많은 데이터 |
2. 예측의 두 갈래: 회귀 vs. 분류
머신러닝(지도학습)은 크게 '회귀'와 '분류'로 나뉩니다.
- 회귀 (Regression): 연속적인 값(숫자)을 예측하는 문제입니다.
◦ 예: 내일의 기온(25.5℃), 3년 뒤 집값(5억 3천만 원), 주가 예측 - 분류 (Classification / 식별): 정해진 카테고리(범주) 중 하나로 예측하는 문제입니다.
- 예: 이 메일은 스팸인가/아닌가? (이진 분류), 이 사진은 개인가/고양이인가/기타인가? (다중 분류)
3. 주요 회귀(Regression) 모델
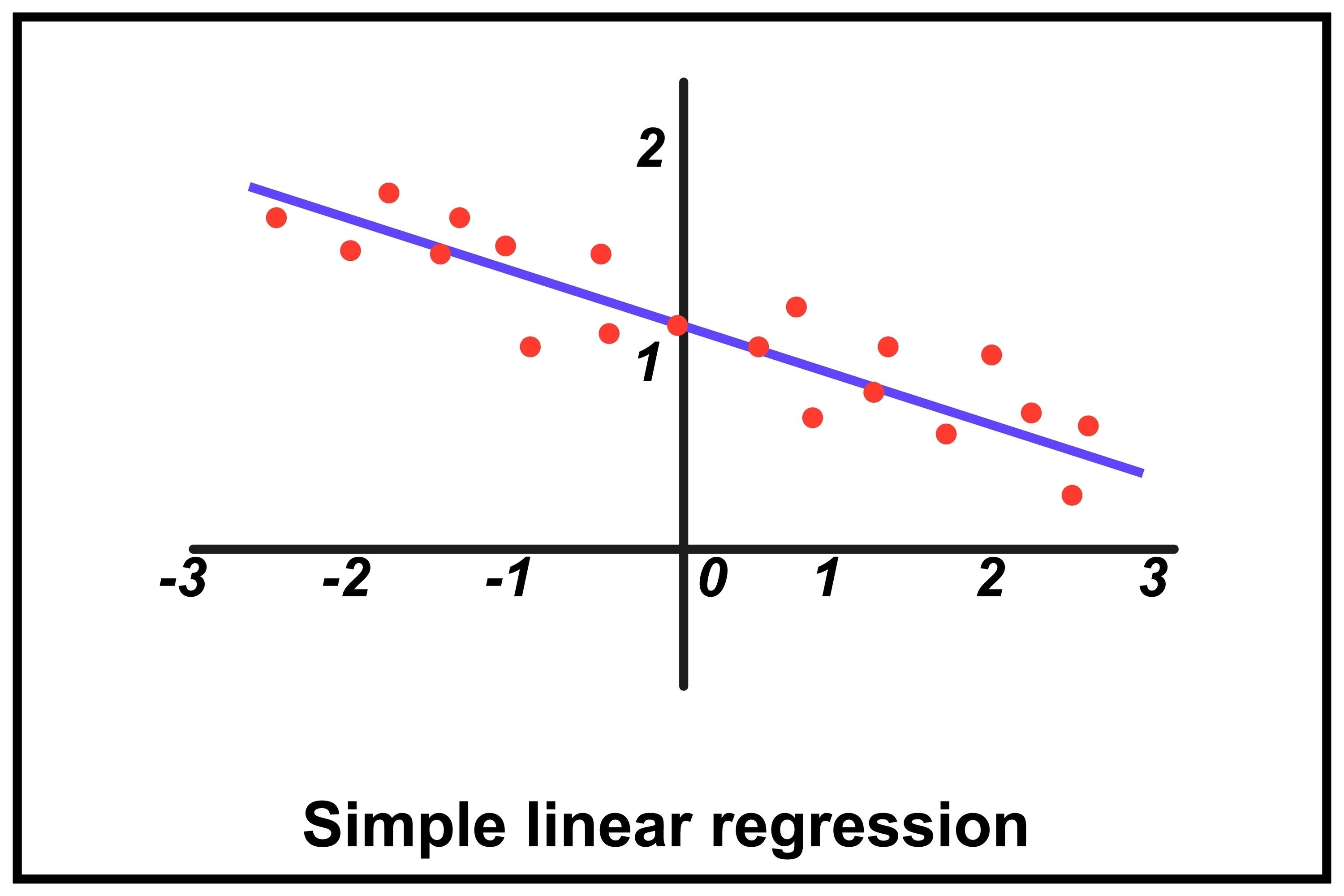
1) 선형 회귀 (Linear Regression)
- 개념: 가장 기본적이고 단순한 회귀 모델입니다. 데이터 간의 직선 관계()를 찾아내어 값을 예측합니다.
- 언제 쓸까?
- 데이터가 선형적인 관계(x가 증가할 때 y도 증가/감소)를 보일 때.
- 모델의 해석이 매우 중요할 때 (어떤 피처가 결과에 얼마나 영향을 주는지 명확히 보임).
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression()
model_lr.fit(X_train, y_train)2) 로지스틱 회귀 (Logistic Regression)
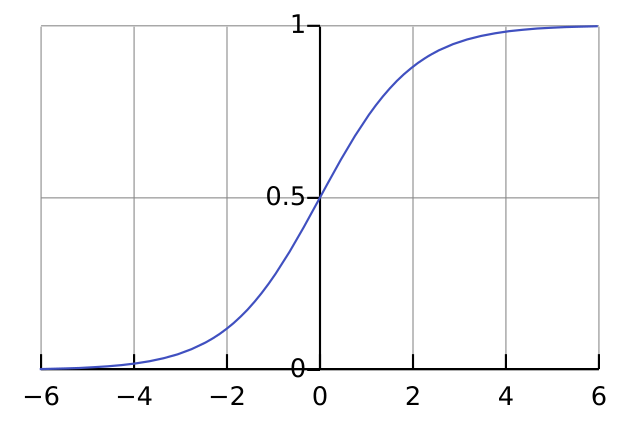
- 개념: 이름은 '회귀'지만, 실제로는 '분류' 모델입니다.
- 선형 회귀처럼 직선을 찾지만, 그 결과를 시그모이드(Sigmoid) 함수에 통과시켜 0과 1 사이의 '확률' 값으로 변환합니다.
💡 보통 0.5를 기준으로 0.5보다 크면 1 (True), 작으면 0 (False)으로 분류합니다.
- 언제 쓸까?
- 이진 분류(Binary Classification) 문제(예: 합격/불합격, 생존/사망)의 기본 모델로 널리 쓰입니다.
- 성능도 준수하고, 선형 회귀처럼 해석력이 좋습니다.
from sklearn.linear_model import LogisticRegression
model_lr = LogisticRegression()
model_lr.fit(X_train, y_train)1) DecisionTree (결정 트리)
-
개념: 데이터를 '스무고개' 하듯이 'If-Then' 규칙으로 쪼개나가며 예측하는 모델입니다.
-
특징:
- 장점: 모델의 예측 과정을 눈으로 쉽게 확인할 수 있어 해석력(Explainability)이 매우 높습니다.
- 단점: 트리를 너무 깊게 만들면 과적합(Overfitting)되기 매우 쉽습니다. (데이터의 사소한 노이즈까지 다 학습해버림)
from sklearn.tree import DecisionTreeClassifier
model_dt = DecisionTreeClassifier(max_depth=10, random_state=42)
model_dt.fit(X_train_scaled, y_train)2) RandomForest (랜덤 포레스트)
- 개념: '과적합되기 쉽다'는 결정 트리의 단점을 보완한 모델입니다. 앙상블(Ensemble) 기법 중 배깅(Bagging)을 사용합니다.
- 작동 방식:
- 데이터를 무작위로 샘플링하여(중복 허용) 여러 개의 작은 데이터셋을 만듭니다.
- 각 데이터셋으로 여러 개의 결정 트리를 만듭니다. (이때 피처도 무작위로 선택)
- 최종 예측 시, 이 모든 트리의 결과를 '다수결 투표'(Voting)하여 결정합니다. (회귀는 '평균')
- 작동 방식:
- 언제 쓸까?
- 결정 트리보다 훨씬 성능이 좋고 과적합에도 강합니다.
- 특별한 튜닝 없이도 준수한 성능을 내는 범용적인 모델로 쓰기 좋습니다.
from sklearn.ensemble import RandomForestClassifier
model_rf = RandomForestClassifier(n_estimators=100, random_state=42)
model_rf.fit(X_train_scaled, y_train)3) XGBoost (eXtreme Gradient Boosting)
- 개념: 캐글(Kaggle) 같은 데이터 경진대회를 휩쓸었던 고성능 모델입니다. 앙상블 기법 중 부스팅(Boosting)을 사용합니다.
- 작동 방식 (vs. 랜덤 포레스트):
- 랜덤 포레스트는 여러 트리를 '동시에' 만들고 투표합니다. (병렬적)
- 부스팅은 트리를 '순차적으로' 만듭니다.
- 첫 번째 트리를 만듭니다.
- 첫 번째 트리가 틀린 문제(오차)에 대해 가중치를 줍니다.
- 두 번째 트리는 이 틀린 문제를 더 잘 맞히는 방향으로 학습합니다.
- 이 과정을 반복하며 점점 모델을 강력하게 '부스팅'합니다.
- 언제 쓸까?
- 높은 예측 정확도가 필요할 때. (특히 정형 데이터에서 최고 수준의 성능을 보임)
- 병렬 처리를 지원하여 학습 속도가 빠릅니다.
from xgboost import XGBClassifier
model_xgb = XGBClassifier(n_estimators=5, random_state=42)
model_xgb.fit(X_train_scaled, y_train)4) LightGBM (Light Gradient Boosting Machine)
- 개념: XGBoost와 마찬가지로 부스팅(Boosting) 계열의 모델입니다. (MS에서 개발)
- 특징 (vs. XGBoost):
- XGBoost보다 학습 속도가 더 빠르고 메모리 사용량이 적습니다.
- 트리를 성장시키는 방식(Leaf-wise)이 달라서 속도 이점을 가집니다.
- 언제 쓸까?
- 대용량 데이터를 다룰 때 XGBoost보다 유리합니다.
- 빠른 학습 속도와 높은 정확도를 동시에 잡고 싶을 때.
from lightgbm import LGBMClassifier
model_lgbm = LGBMClassifier(n_estimators=3, random_state=42)
model_lgbm.fit(X_train_scaled, y_train)이 패턴은 제가 아까 설명드린 모든 트리 기반 모델에 동일하게 적용됩니다:
| 분류 (Classification) | 회귀 (Regression) |
|---|---|
DecisionTreeClassifier | DecisionTreeRegressor |
RandomForestClassifier | RandomForestRegressor |
XGBClassifier | XGBRegressor |
LGBMClassifier | LGBMRegressor |
트리 기반 모델 계보
트리 모델 구조 요약
DecisionTree → RandomForest → XGBoost → LightGBM
(단일 트리) (다수 트리 병렬) (부스팅, 순차적 개선) (부스팅 + 속도최적화)마치며
AICE 시험 준비에 이 정리 내용이 도움이 되길 바랍니다!
- 스케일러: 아웃라이어 유무(Robust)와 데이터 범위(MinMax)를 기준으로 선택! (기본은 Standard)
- 회귀/분류: 연속된 값이면 '회귀', 카테고리면 '분류'! (단, 로지스틱 회귀는 분류 모델!)
- 트리 모델:
- 해석이 필요하면
DecisionTree. - 범용적으로 쓰기 좋으면
RandomForest. - 최고 성능과 속도가 필요하면
XGBoost또는LightGBM.
- 해석이 필요하면
