공분산(Covariance)
-
확률 변수가 하나일 때에 대해서 분산을 계산할 수 있었다.
-
변수가 여러 개일 때(다변수 확률 분포)의 분산은?
-
공식은 다음과 같다.
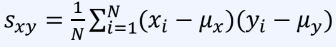
-
평균으로부터 얼마나 떨어져 있는지를 나타냄
-
평균값의 위치와 표본 위치 사이의 사각형 면적을 사용
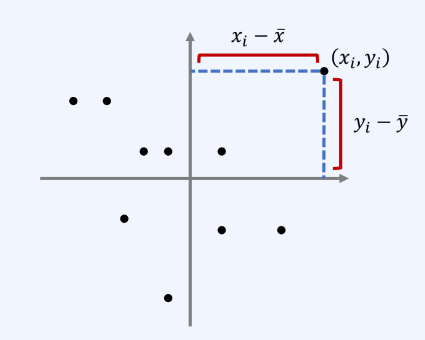
-
데이터 위치에 따라 부호가 다르게 반영된다.
-
양수 부호 : 1,3사분면
-
음수 부호 : 2,4사분면
-
데이터의 분포에 대한 크기와 방향성을 같이 보여준다.
-
크기 : 원점에서 얼마나 떨어져 있는지
-
방향성 : 양/음수에 따라 어느 뱡향을 가지는지
-
양의 상관 관계 : 공분산이 양수값을 가진다.
-
음의 상관 관계 : 공분산이 음수값을 가진다.
상관계수(correlation coefficient)
-
공분산은 크기와 방향성 정보를 같이 가지고 있다.
-
일반적으로 상관성만을 보자고 한다.
-
따라서 다음과정을 통한 정규화 진행

-
이를 피어슨 상관계수라고 한다.
-
피어슨 상관계수를 그림으로 이해하면
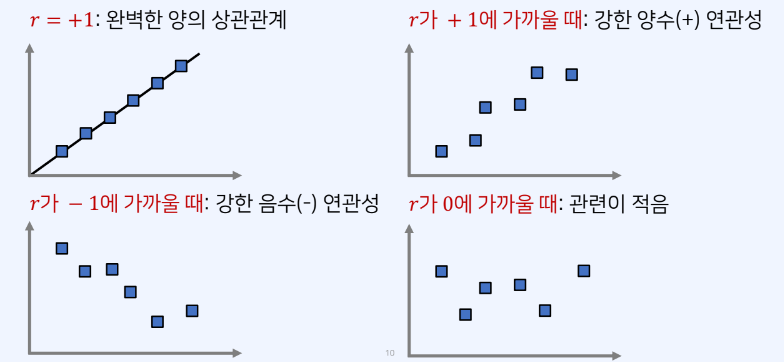
확률 변수의 공분산과 상관 계수
- 두 확률 변수 X와 Y의 공분산은
- Cov[X,Y] = E[(X - E[X])(Y - E[Y])]
- 두 확률 변수 X, Y의 상관 계수는
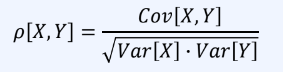
- 상관 계수(ρ)는 항상 -1이상 1이하의 값을 가진다.
- ρ = 1 : 완전 선형 양수(+) 상관관계
- ρ = -1 : 완전 선형 음수(-) 상관관계
공분산 행렬(covariance matrix)
-
기계학습 분야에서 다변수 확률변수(벡터 형태의 표본값) 가정하는 경우가 많다.
ex) 얼굴의 특징 3가지(얼굴길이, 코 길이, 입술 두께)
-> 하나의 데이터는 3개의 원소를 가지는 벡터
-> 얼굴 데이터 x = [얼굴길이, 코 길이, 입술 두께] -
이러한 데이터 N개 있다고 가정
-
N개의 얼굴 데이터를 하나의 행렬로 표현 NX3 행렬이다.
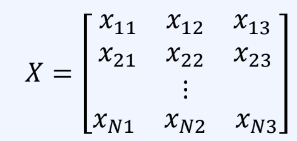
-
얼굴 길이, 코 길이는 양의 상관 관계 예상가능
-
공분산 행렬을 통해 상관정도가 얼마나 큰지 표현 가능
-
3개의 서로 다른 확률 변수의 모든 조합에 대해 공분산을 한꺼번에 표기할 수 있다.
-
이를 공분산 행렬이라 한다.
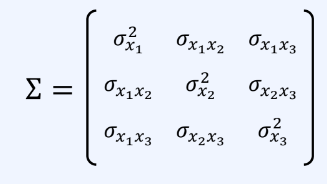
-
공분산 행렬은 다음과 같이 정의된다. (데이터 개수 :N개, 특징의 개수: d개)
-
대각 성분(diagonal)은 각 확률 변수의 분산
-
비대각 성분(off- diagonal)은 두 확률변수의 공분산이다.
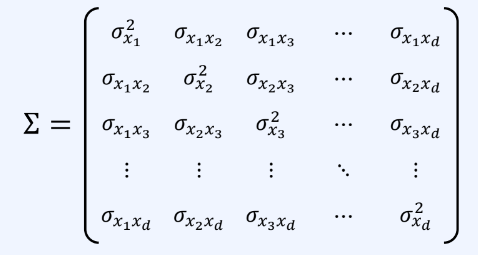
공분산과 독립
- 독립에 대해 다시 생각해 보자
- PXY(x,y) = PX(x)PY(y)일 때 독립이라고 했다.
- 결과적으로 X와 Y가 독립이라면 다음 공식이 성립한다.
-> E(XY) = E(X)E(Y) - 이때 공분산 Cov(X,Y) = E(XY) - E(X)E(Y) = 0이다.
- 두 확률 변수가 독립이면, 공분산은 0 이 된다.
-> 역은 성립하지 않음(공분산이 0 이라고 독립은 아님)
공분산 계산 예시
- 두 데이터가 양의 상관 관계를 가질 경우
- 확률 변수 X의 값이 크면, Y의 값도 큰 경우
- 수학점수가 높다면 영어 점수가 높은 경향이 있다.
- 성적이 낮은 학생은 둘다 낮은 경향이 있다.
- 총 10명의 학생의 수학 영어 성적 예시가 다음이다.
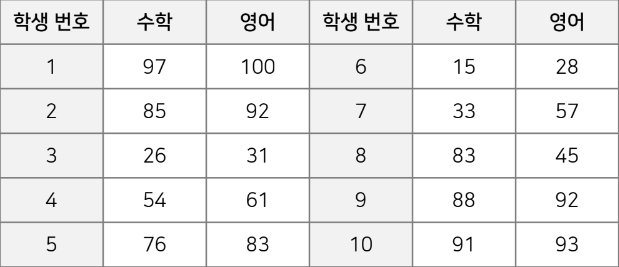
import matplotlib.pyplot as plt
X = [97, 85, 26, 54, 76, 15, 33, 83, 88, 91]
Y = [100, 92, 31, 61, 83, 28, 57, 45, 92, 93]
plt.plot(X, Y, "o")
plt.xlabel("math")
plt.ylabel("english")
plt.show()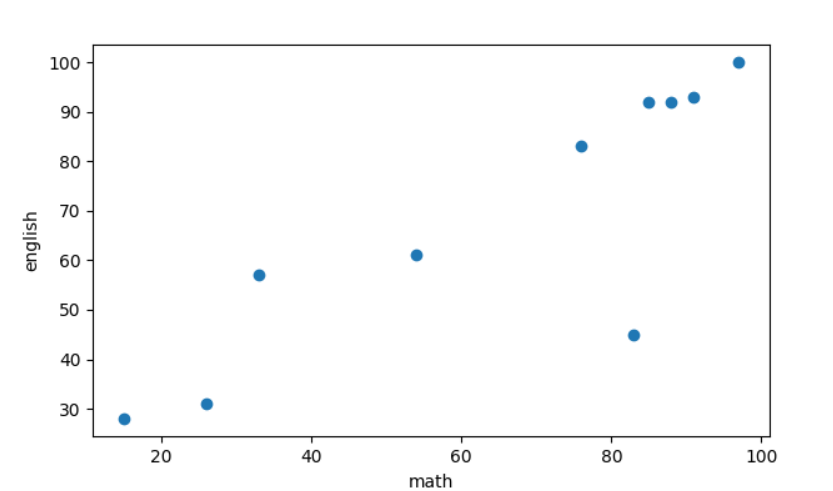
- 수학, 영어 성적에 대한 평균, 분산, 공분산을 구할 수 있다.
- 평균, 분산
X = [97, 85, 26, 54, 76, 15, 33, 83, 88, 91]
Y = [100, 92, 31, 61, 83, 28, 57, 45, 92, 93]
# 평균
def mean(lst):
lst_mean = 0
for i in lst:
lst_mean += i/len(lst)
return lst_mean
# 분산
def var(lst):
lst_var = 0
for i in lst:
lst_var += ((i - mean(lst))**2)/(len(lst) -1)
return lst_var
print(f"x_mean = {mean(X):.3f}, x_var = {var(X):.3f}")
print(f"y_mean = {mean(Y):.3f}, y_var = {var(Y):.3f}")
- 평균 분산 공분산
import numpy as np
np.set_printoptions(precision = 3) # 소숫점 아래 3자리 반올림
import math
X = [97, 85, 26, 54, 76, 15, 33, 83, 88, 91]
Y = [100, 92, 31, 61, 83, 28, 57, 45, 92, 93]
# 평균
def mean(lst):
lst_mean = 0
for i in lst:
lst_mean += i/len(lst)
return lst_mean
# 분산
def var(lst):
lst_var = 0
for i in lst:
lst_var += ((i - mean(lst))**2)/(len(lst) -1)
return lst_var
# 공분산
def covar(lst1, lst2):
lst_covar = 0
for x, y in zip(lst1, lst2):
lst_covar += ((x - mean(lst1)) * (y - mean(lst2)))/(len(lst1)-1)
return lst_covar
# 상관 계수
def corr_coeff(lst1, lst2):
lst_corr_coeff = covar(lst1, lst2) / math.sqrt(var(lst1)*var(lst2))
return lst_corr_coeff
print(f"sample covariance: {covar(X,Y):.3f}")
print(f"sample covariance (Numpy) : {np.cov(X,Y)}")
print(f"correlation coefficient: {corr_coeff(X,Y):.3f}")
print(f"correlation coefficient (Numpy) : {np.corrcoef(X,Y)}") - 결과 값
sample covariance: 703.267
sample covariance (Numpy) : [[915.511 703.267][703.267 743.733]]
correlation coefficient: 0.852
correlation coefficient (Numpy) : [[1. 0.852][0.852 1. ]]
