통계
1.확률 개요

특정 사건이 발생할 가능성(0~1) 사이의 실수로 표현N개의 학습 데이터로 기계학습 모델을 학습일반적으로 기계학습 모델의 출력은 "확률"형태ex1) 이미지 분류 모델이 이미지 x에 대하여 75% 라는 확률로 고양이라고 예측다양한 상황의 확률 계산을 위해서 경우의 수 계
2.확률 변수와 확률 분포
시행(trial): 반복 가능하며 매번 결과가 달라질 수 있는 실험 ex) 주사위 2개를 던지는 행위사건(event): 시행에 따른 결과를 의미 ex) 눈금의 합이 3이 되는 사건어떠한 사건이 일어날 가능성을 수로 표현한 것사건으로 인해 그 값이 확률적으로 정해지는 변
3.이산확률분포
결과 값이 두가지 중 한가지로만 나오는 시행ex1) 입학시험 -> 합격/불합격ex2) 동전 던지기 -> 앞면/뒷면베르누이 시행의 결과값은 0또는 1로 표현확률 변수는 0혹은 1의 값만 가질 수 있으므로 이산확률변수다.베르누이 확률변수의 분포를 베르누이 확률분포라고 한다
4.연속확률분포
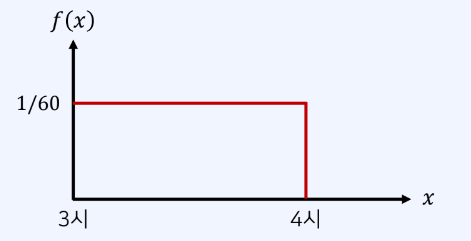
확률변수 X가 취할 수 있는 값이 무한한 경우 이를 연속확률변수라고 한다.특정한 값 x에 대한 정확한 확률 값을 표현 할 수 없다.\-> 따라서 특정 구간 a <= x <= b에 대한 확률로 표현연속확률변수가 주어진 구간내에 포함될 확률을 출력하는 함수확률변
5.표준 정규 분포
표준 정규 분포 평균이 0이고 분산이 1인 표준화된 정규분포이다. 확률 변수 X가 X~N(μ, σ)을 따를 때 다음 공식으로 표준화를 할 수 있다. Z =(X − μ)/σ 확률 변수 Z가 0이고 분산이 1인 정규분포를 따를 때 Z는 표준 정규분포를 따른다고 말한다. Z
6.독립변수와 종속 변수
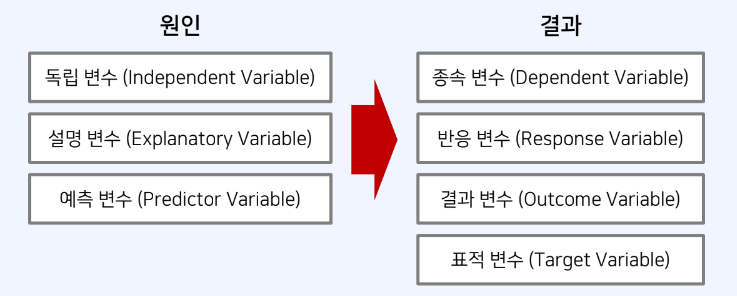
현실 세계에서 하나의 변수가 다른 변수에 영향을 미치는 경우가 많다.ex) 부모의 수입이 높으면 자녀의 학업 성적이 우수한가?독립변수: 부모의 수입 -> 종속변수: 자녀의 학업 성적독립: 다른 변수에 의해 영향을 받지 않는 변수(종속변수에 영향을 줌)연구자가 조정 가능
7.결합 확률과 주변 확률
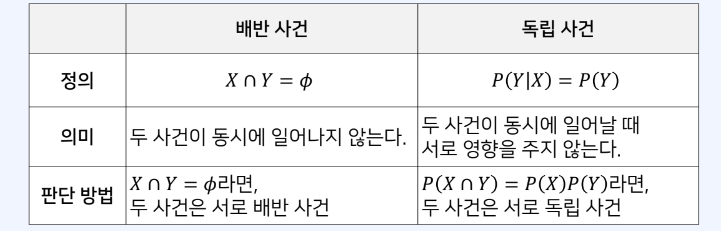
P(X∩Y) = P(X)P(Y)인 경우 두 사건 X, Y는 독립이다. 두 변수가 서로 영향을 주지 않는다는 의미ex) 오늘 동해바다에서 고래가 발견되는 사건 / 내가 시험에서 100점 맞는 사건한 사건의 결과가 다른 사건에 영향을 줄 때 이 두 사건 X, Y를 종속 사
8.조건부 확률
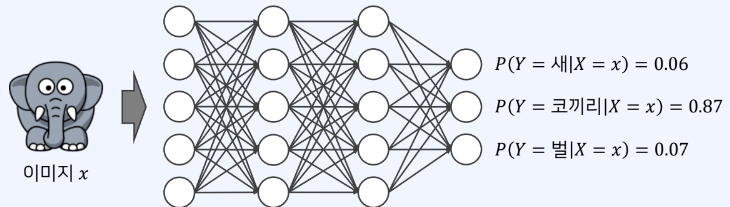
어떠한 사건이 일어나는 경우 다른 사건이 일어날 확률딥러닝 분야에서 "X사건이 단서일때, Y사건이 발생할 확률"로 이해 가능분류 모델은 일반적으로 다음과 같이 동작이미지 x가 입력, 클래스 y사 나올 확률P(Y=y|X=x)특정 사건이 발생하는 경우에 다른 사건이 발생할
9.베이즈 정리

입력 : 하나의 텍스트출력 : 텍스트가 특정 클래스에 속할 확률목표 : 하나의 텍스트(x) 가 스팸(y)일 확률 계산텍스트의 확률 변수를 X, 클래스의 확률 변수를 Y라고 하자클래스 2개 존재 y1 = 햄, y2 = 스팸P(Y|X)를 계산할 수 있으면 우리가 원하는 프
10.평균과 기댓값
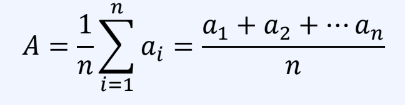
일반적으로 산술평균을 사용하며 다양한 종류가 존재한다.산술 평균(arithmetric mean) : 모든 관측값을 더해 관측값의 개수로 나눈 것평균이 특정 데이터 집단을 대표하기 적절한가?ex) 마이클 조던이 졸업한 지리학과가 평균 연봉이 가장 높게 나오는 오류가 존재
11.분산과 표준편차
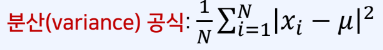
평균과 관측치에 대해 편차 제곱의 평균값을 의미한다.N개의 데이터의 평균이 주어졌을 때 분산은편차는 평균과의 차이라 다 더하면 0이 된다.분산이 작을 때 : 데이터가 평균에 가까울 수록분산이 클때 : 데이터가 평균에서 멀어질 수록표준편차는 분산의 양의 제곱근이다.분산이
12.공분산
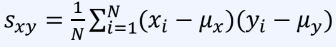
확률 변수가 하나일 때에 대해서 분산을 계산할 수 있었다.변수가 여러 개일 때(다변수 확률 분포)의 분산은?공식은 다음과 같다.평균으로부터 얼마나 떨어져 있는지를 나타냄평균값의 위치와 표본 위치 사이의 사각형 면적을 사용데이터 위치에 따라 부호가 다르게 반영된다.양수
13.확률 분포 추정
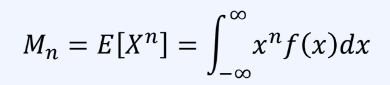
우리가 확률 분포를 미리 안다면 확률 변수를 직접 넣어 구할 수 있지만 현실에서는 확률 분포 함수에서 나온 데이터만을 얻을 수 있다.내재된 확률 분포 함수를 모를 때 어떻게 추정?우리가 가진 데이터로부터 확률 분포를 추정하는 기술데이터 형태에 따라 원하는 분포로 추정
14.최대 가능도 추정(maximum likelihood estimation)
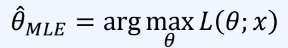
인터넷에서 x를 N개 수집했다.이런 N개의 데이터가 정규분포를 따른다고 가정하고, 정규분포를 추정해보자모수 추정 문제 : 표본 값 x에 대해서는 알고 있지만 모수 θ를 모르는 상황 모멘트 방법 말고, 최대 가능도 추정 사용 가능이론적으로 가장 가능성이 높은 모수(par
15.편향과 오차
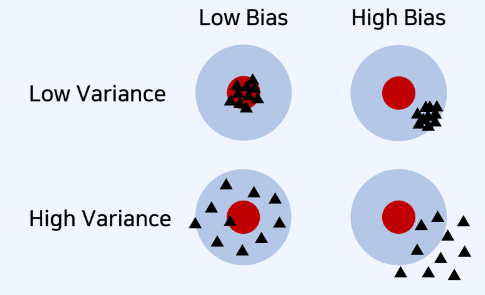
편향된 데이터 : 실제 데이터를 반영하지 못하고 편향된 데이터ex) 만일 얼굴 데이터셋이 서양인 위주라면 -> 동앙인 데이터에 대해 편향된것을 보여줌편향이 높을 때 : 모델이 예측한 값과 멀리 떨어짐분산이 높을 때 : 예측한 값들이 서로 멀리 떨어짐기계 학습 모델 성능
16.최소 제곱법과 추세선
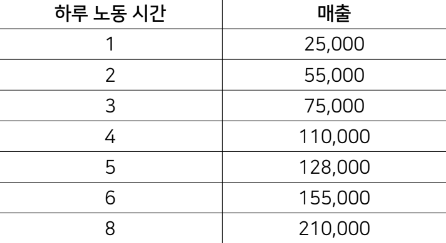
다음 노동시간과 매출액을 보고 7시간과 9시간을 일 했을 때 매출액을 구하시오해결 방법매출 데이터를 그래프로 표현 해보자노동시간과 매출이 성형함수의 형태를 지닌다.선형 회귀 : 주어진 데이터중 가장 합리적인 선형 함수를 찾아내는 문제학습 데이터가 3개 이상일 때 의미가
17.데이터 추출
기계 학습에서 데이터 랜덤 추출할때가 많다.리스트 내의 1개의 원소만을 추출\-> choice()메서드를 이용해 1개의 원소를 랜덤으로 추출\-> 결과 1~5 사이 정수 중 한개리스트에서 중복없이 여러 원소 추출\-> sample() 메서드 이용 k개의 데이터 중복없이