BERT(Bidirectional Encoder Representation from Transformers)
- Transformer기반 양방향 인코더 표현
BERT모델 구조
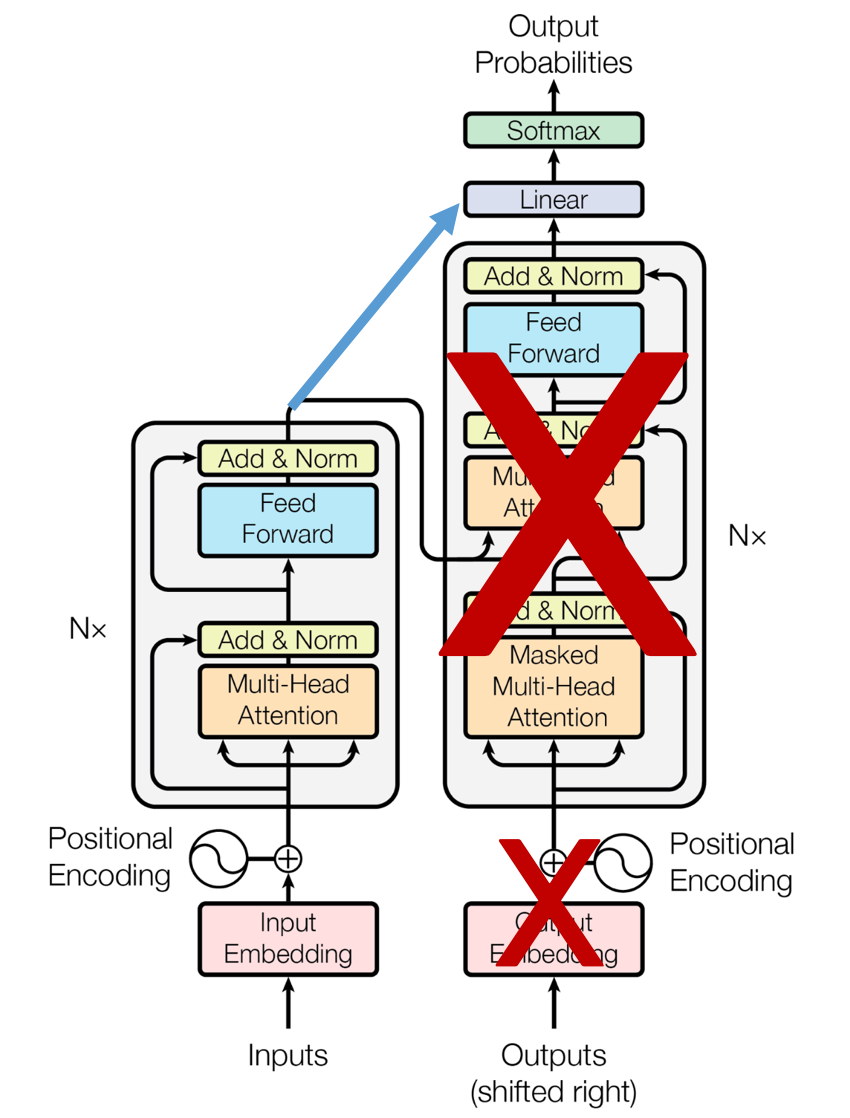
GPT(Generative Pre-trained Transformer)
-
unidirectional
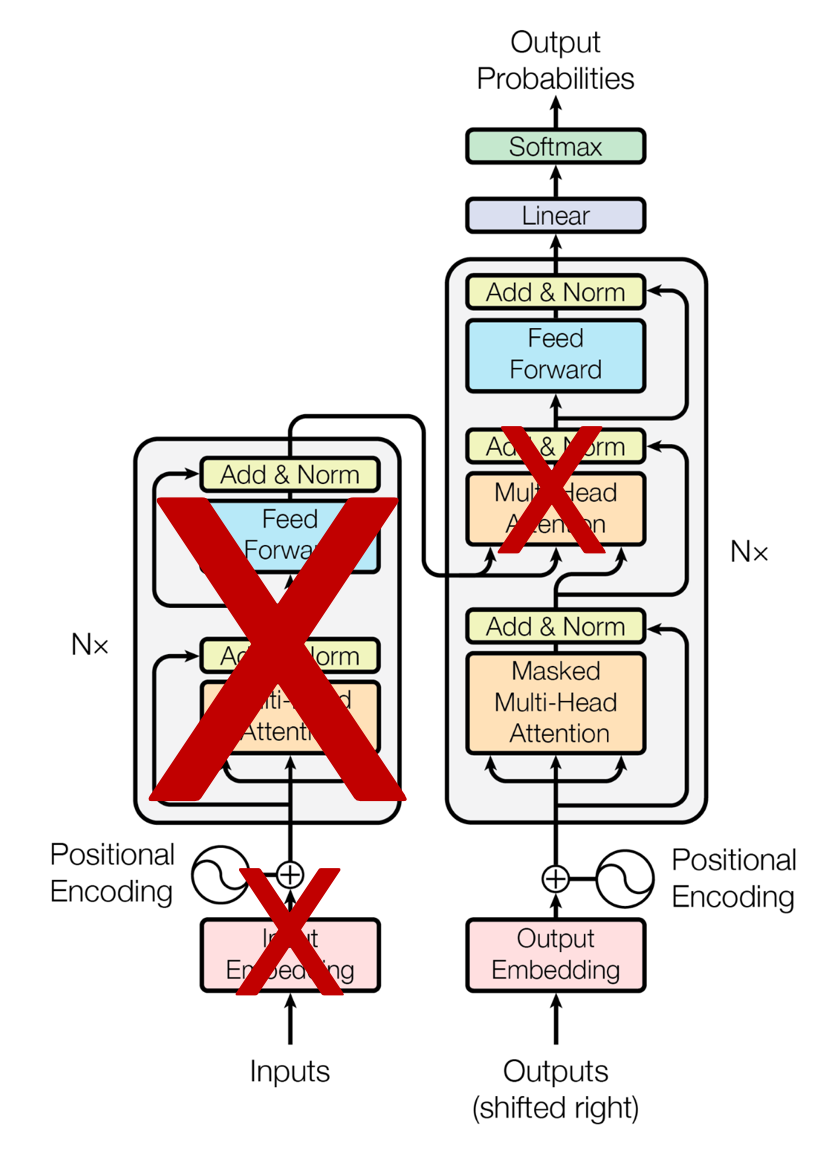
-
i 번째 입력 처리 시 i번째 이하의 토큰만 고려
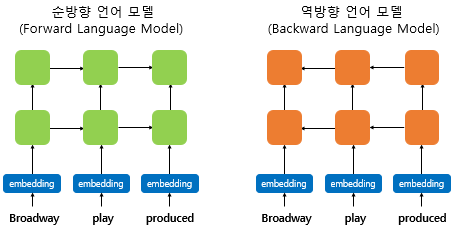
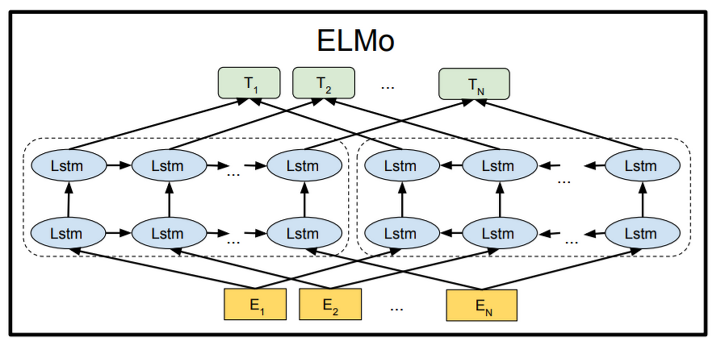
ELMo
-
RNN기반 모델, biLM을 이용
-
Shallow Bidirectional(Unidirectional의 두개를 단순 concat 한 것)
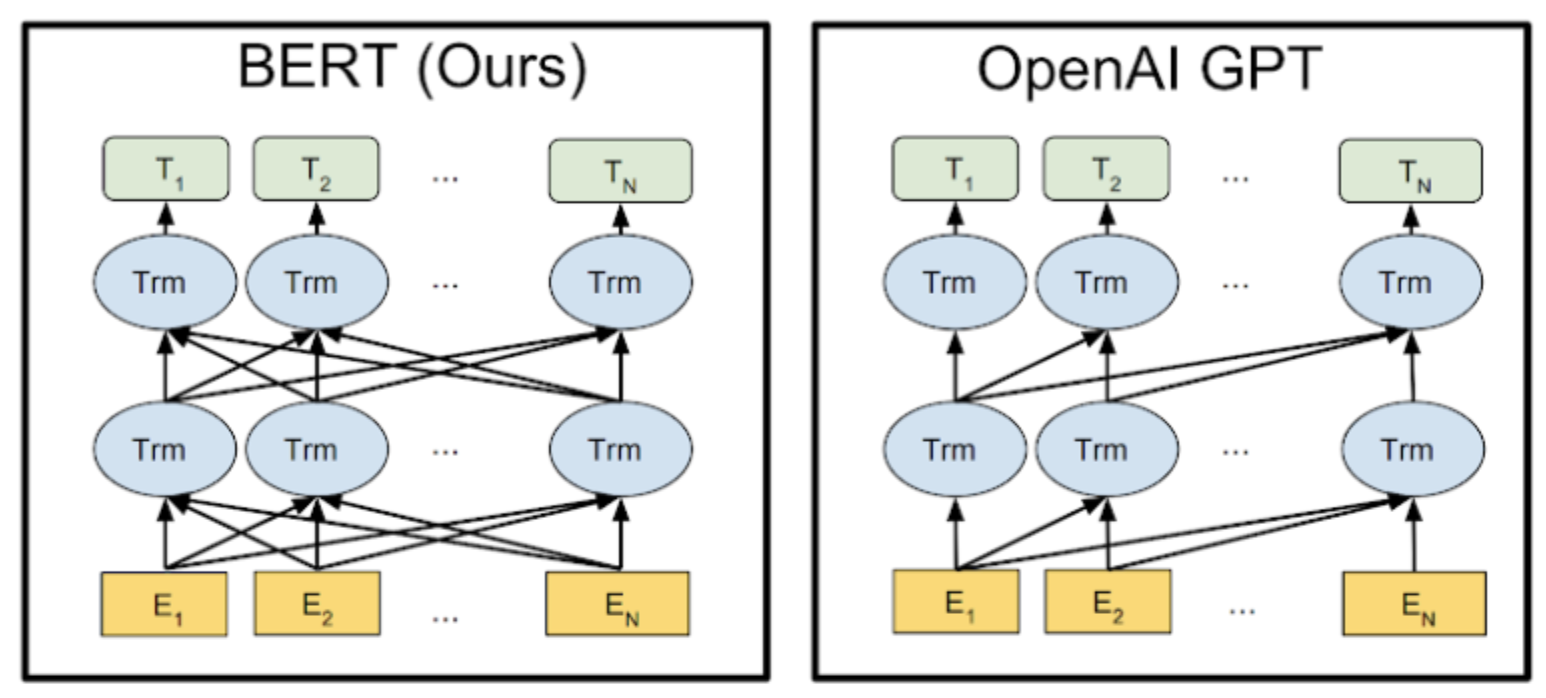
BERT
- Transformer의 인코더의 Self Attention 원리 이용
- Deeply Bidirectional
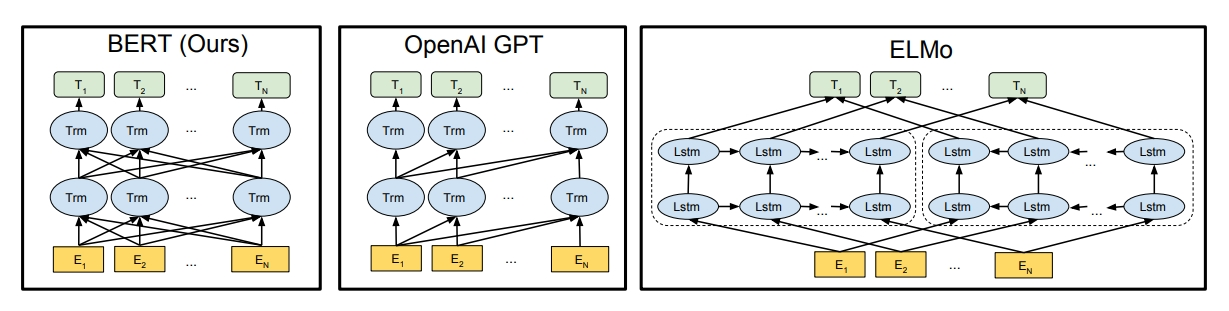
BERT구조
BERT base
- 12개의 transformer blocks
- n_head: 12
- Hidden size d = 768
- Total Parameters = 110million
BERT Large
- 24개의 transformer blocks
- n_head: 16
- Hidden size d = 768
- Total Parameters = 340million
자연어 처리(NLP) 분야
Natural Language Generation(NLG)
-
기계가 사람처럼 의미있는 문장을 생성하는 것
ex) 챗봇, 기계 번역, 자동 보고서 생성 -
GPT는 NLG에 적합 -> Unidirectional 모델이라서 : 문맥상 맞는 다음 단어나 문장을 예측하는 데 탁월
Natural Language Understanding(NLU)
-
기계가 사람처럼 문장을 이해하는 것
ex) 감성분석, 자연어 질의 응답, 자동요약, 텍스트 분류 -
BERT는 NLU에 적합 -> Bidirectional 모델이라서 : 텍스트 전반적으로 학습하는데 탁월
BERT의 구성
- BERT는 어떤 기법으로 만들어졌는가?
- Pre-training
- MLM(Masked Language Model)
- NSP(Next Sentence Prediction)
- Embedding Combination
- fine-tuning
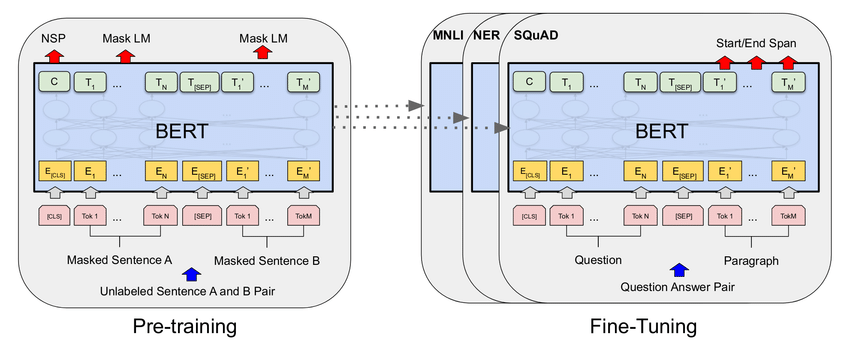
Pre-training VS Fine-Tuning
- 거대 데이터를 이용하여 미리 훈련(Pre-training)을 해두고, 사전 훈련된 모델을 필요한 task에 맞게 튜닝(Fine-Tuning)하는 것
Fine-Tuning VS Feature-Extraction
-
변형된 부분을 포함한 전체 모델 학습(Fine-Tuning) : BRET, GPT
-
새로 쌓은 부분만 파라미터를 업데이트(Feature Extraction) : ELMo
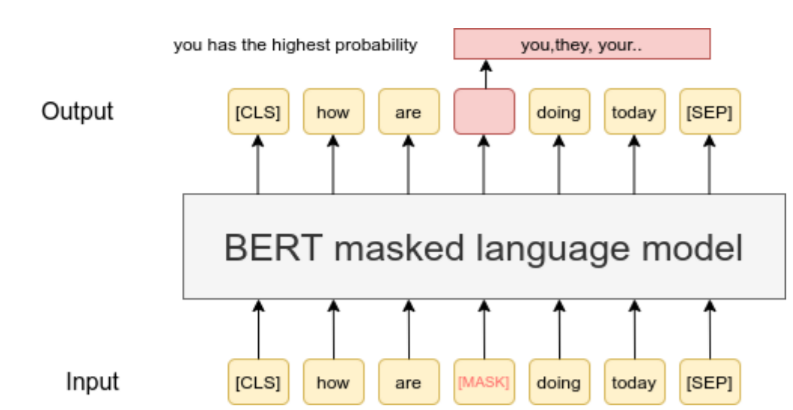
MLM(Masked Language Model)
-
BERT를 pre-traning할 때 사용한 기법 중 하나
-
일정 비율의 토큰을 가린 채 문장을 복원하도록 학습
-
다음 time-step의 토큰을 예측하는 기존 모델과 달리 MLM은 현재 time-step의 토큰을 예측하는 것
학습과 추론의 괴리를 없애기 위해
1. 전체 토큰 중 15%의 토큰만 추론 대상으로 선정
2. 15%의 토큰 중 80%(전체의 12%)를 MASK로 가림
3. 15%의 토큰 중 10%(전체의 1.5%)를 랜덤 토큰으로 변환
4. 15%의 토큰 중 10%(전체의 1.5%)를 그대로 놔둠
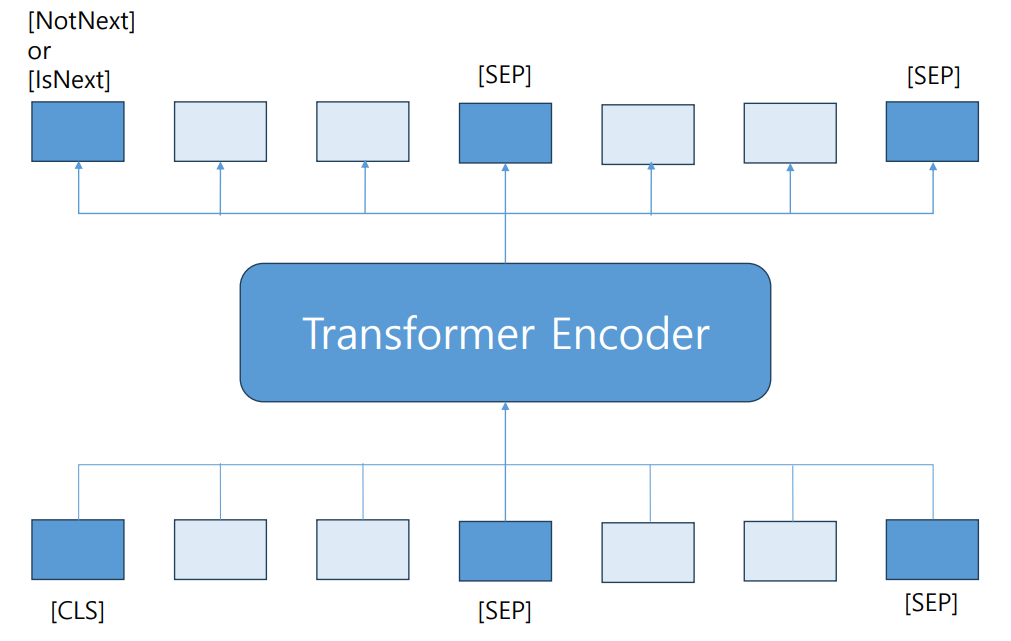
NSP(Next Sentence Prediction)
- BERT를 pre-training할 때 사용한 기법 중 하나
- 두 번째 문장이 첫번째 문장 다음에 나오는지 여부를 예측
- 문장과 문단 구분 시 2개의 특별한 토큰 추가
- [CLS]: 전체 시퀀스 분류
- [SEP]: 시퀀스 내 문장 분류
ex) [CLS] 오늘 날씨 어때?[SEP] 왠지 덥더라 [SEP]
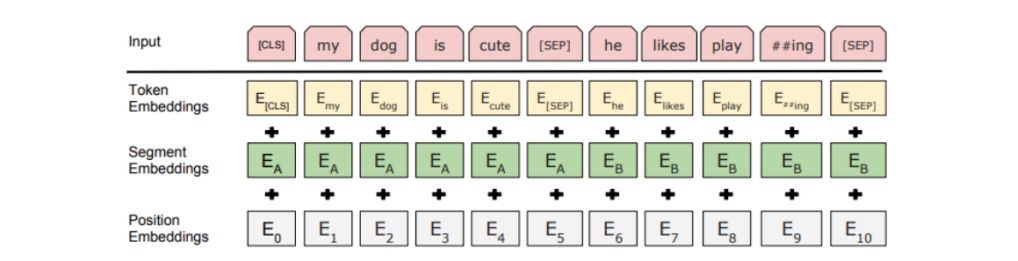
Embedding Combination
- 기존 transformer : 단어 임베딩 + 위치 임베딩
- BERT : 단어 임베딩 + 문장 임베딩 + 위치 임베딩
Fine - Tuning
- pre-training으로 얻은 모델을 기반으로 task에 맞게 변형, 조정 한 것
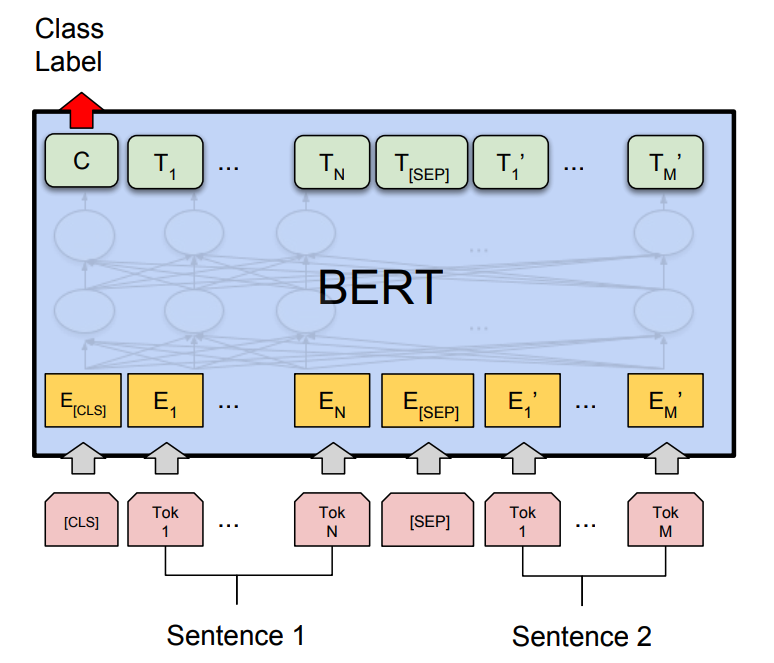
- 특히 text Classification같은 경우에는 [CLS] 토큰 위치에 linear layer와 softmax를 추가하여 분류
BERT의 task
- Pre-training으로 얻은 모델을 기반으로 task에 맞게 변형 및 조정
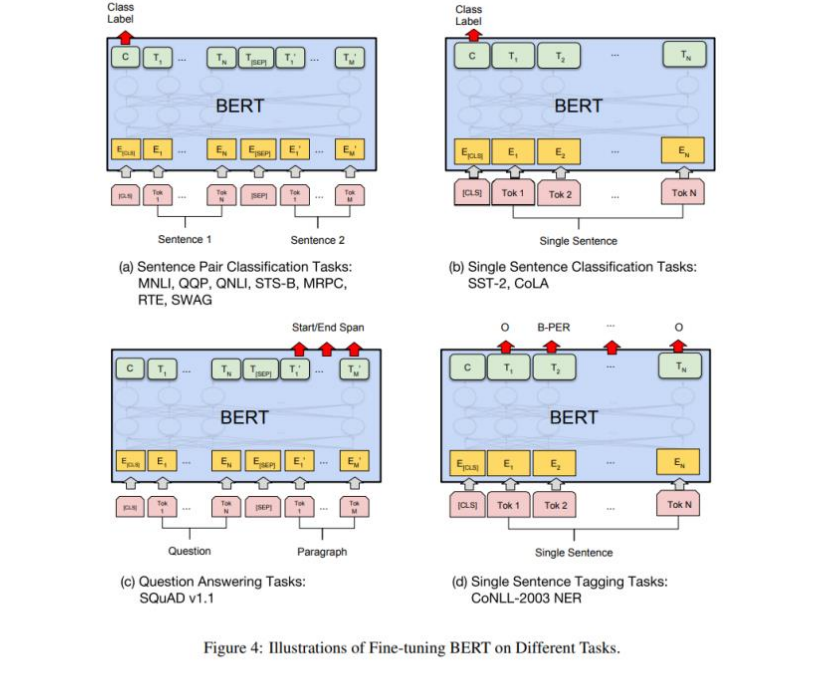
!! BERT는 NLU에서만 사용이 가능하며 NLG에서는 사용할 수 없다.
Hugging Face란?
https://huggingface.co/docs/transformers/index
- 인공지능 GitHub
- Model Hub 제공
- 사용자들이 모델을 공유하고 자신들의 코드를 공유한다.
- Pytorch, Tensorflow 코드로 모두 동작하므로 쉽게 불러오기 가능
- 모델 아키텍처 뿐만이 아니라 전처리 학습, 테스트코드도 받아보기 좋다
- BERT, GPT, CLIP등 NLU, NLG를 위한 다양한 아키텍처 제공
- CV 아키텍처도 존재한다.
