이미지
-
jpg, png및 대부분의 이미지 파일은 비트맵
-
pixel은 digital image에서 격자를 구성하는 색조, 채도및 명도의 가장 작은 사각형으로 이미지 구성
-
convolution연산은 특성맵(feature map)인 랭크 3 텐서에 적용
*feature map : 입력으로부터 커널을 사용하여 합성곱 연산을 통해 나온 결과 -
이 텐서는 2개의 공간축(높이, 너비)과 깊이 축(채널축)으로 구성
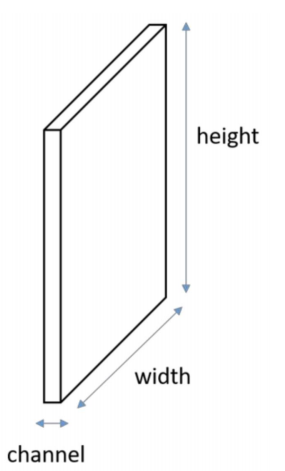
-
이미지는 R/G/B 3개의 channel을 가짐
-
image data를 밀집 신경망에 사용할 수 없는 이유 : input data의 형태가 1차원((1,N)벡터)이여야 한다. 즉, 3차원인 이미지 데이터는 input data로 사용할 수 없다.
-
image data를 효과적으로 비교하기 위해서 local feature를 찾아내고 local feature끼리 비교하고자 한다.
CNN
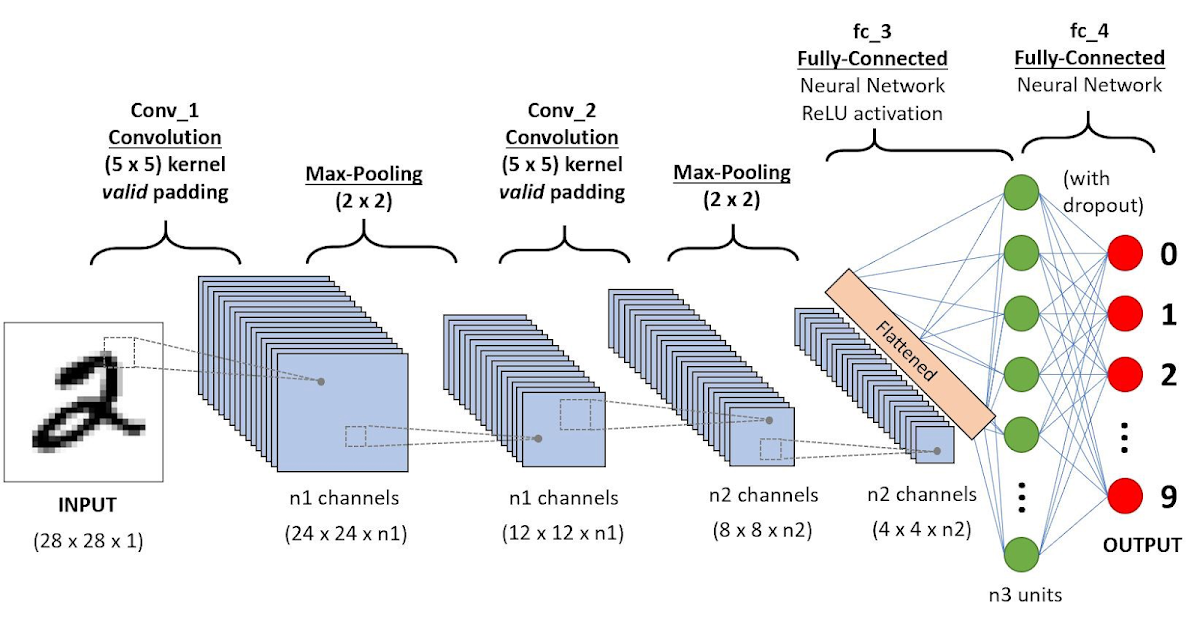
- 합성곱 신경망
- computer vision task에 사용되는 핵십 Deep learning 구조
- 이미지 내의 같은 패턴이 존재만 하면 매칭이 가능하다. 이미지 분류, 검색 등에 자주 쓰인다.
Convolution 방법
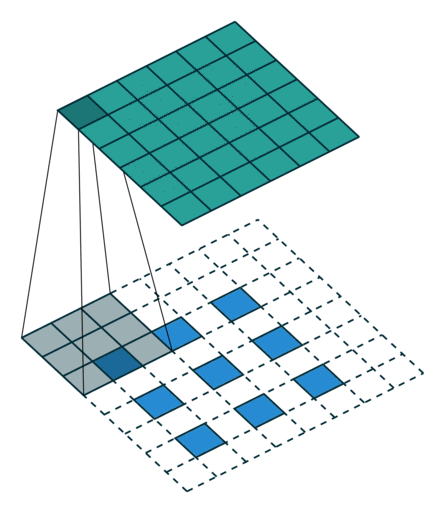
- RGB channel로 이루어진 이미지 data에 convolution filter(kernel)이 이미지를 훑어 내려가며(sliding) output 도출
Convolution Layer
-
Fully Connected Layer에서 가중치 매개변수 외에 편향이 존재 convolution Layer도 마찬가지다.
-
편향은 filtering후 더해주며 하나만 존재
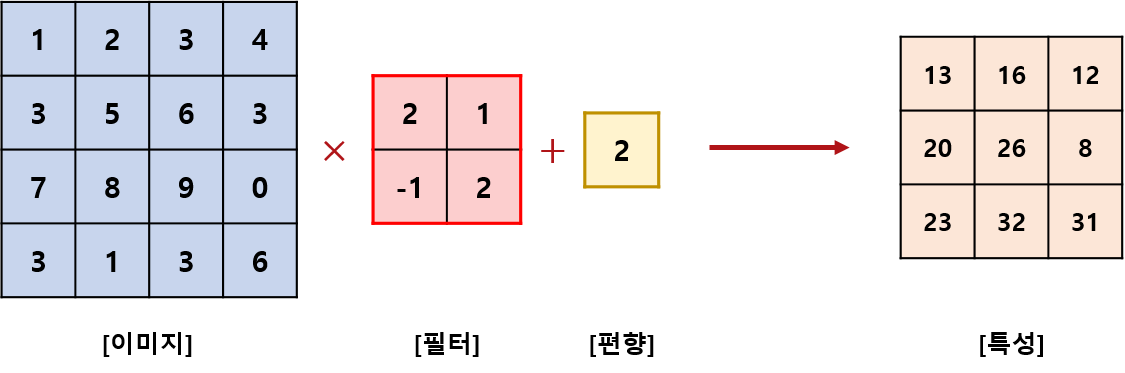
-
padding : 입력 데이터의 가장자리에 적절한 개수의 행과 열을 추가하고 고정된 값을 넣어 처리한 후 출력 크기를 조정
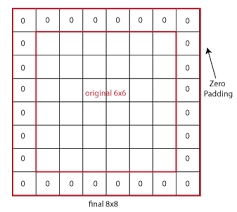
-
stride: filter를 적용하는 위치의 간격(연속적인 window사이의 거리)을 정하고 정한값만큼 window가 움직임
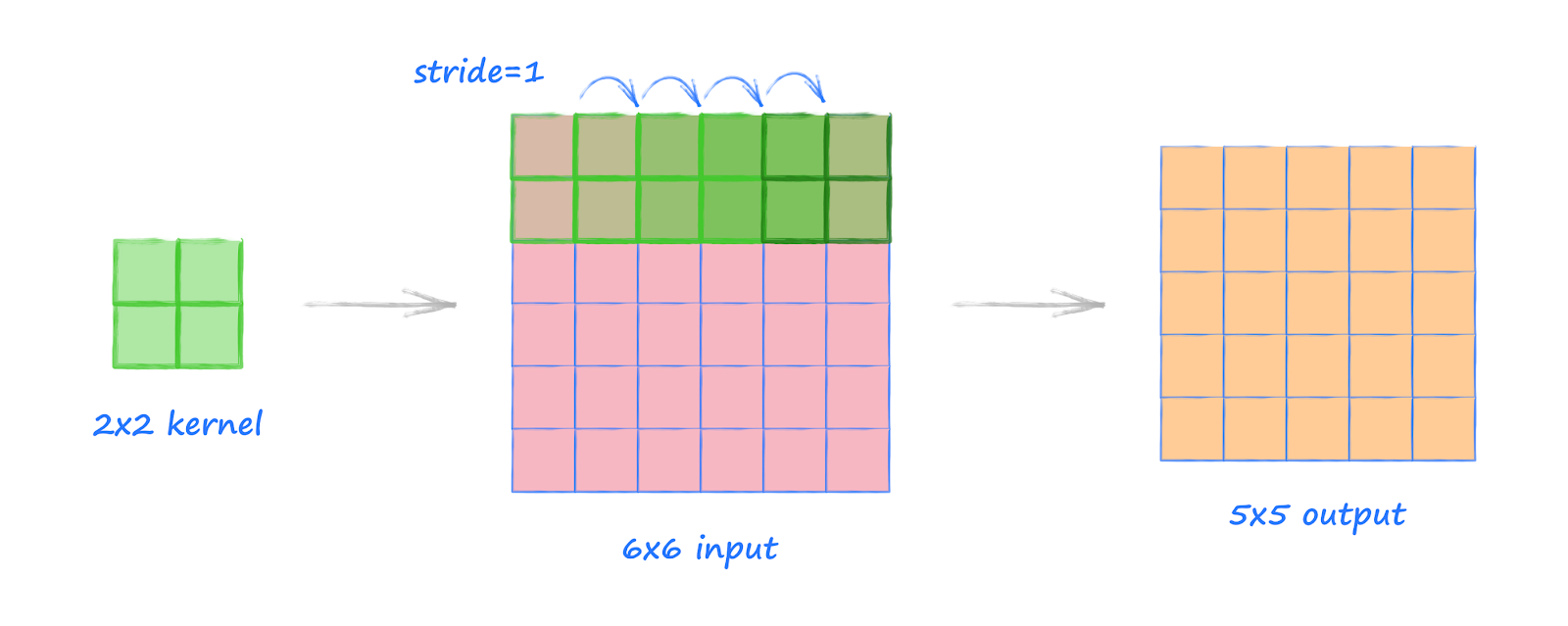
Pooling Layer
-
Pooling : feature map의 차원을 down sampling(data 개수를 줄여주는 과정)혹은 축소하여 연산량을 감소시키고, 주요한 특성 벡터를 추출하여 학습을 효과적으로 할 수 있게 한다.(Max Pooling, Average Pooling)

-
pooling layer는 convolution layer와 달리 학습하는 매개변수가 존재하지 않음
-
연산이 channel마다 독립적으로 이루어지기 때문에 input data의 channel수와 output data의 channel수가 같다.
-
input data의 미세한 차이에 robust하다.(변화가 민감하지 않다.)
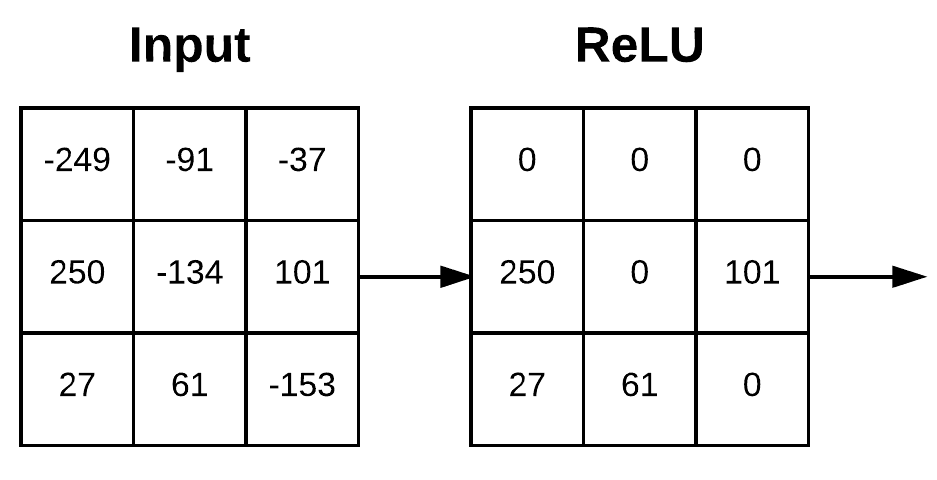
Relu(Rectified Linear Units) Layer
- convolution layer에서 도출된 output activation map을 입력으로 받아 Relu function을 이용해 양수값은 그대로 음수값은 0으로 clipping
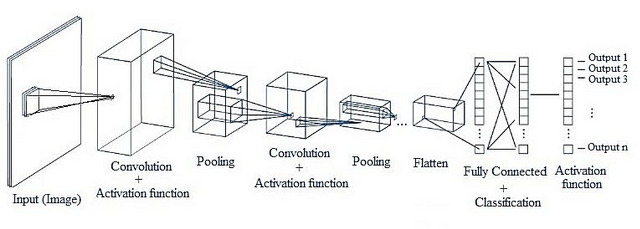
CNN구조
hyperparameter
- Convolution layer
- 필터수- 필터 사이즈
- pooling layer
- window size- window stride
- Fully connecter layer
- layer 수- 뉴런 수
다양한 cnn구조
- AlexNet
- VGGNet
- GoogLeNet
- RestNet
AlexNet
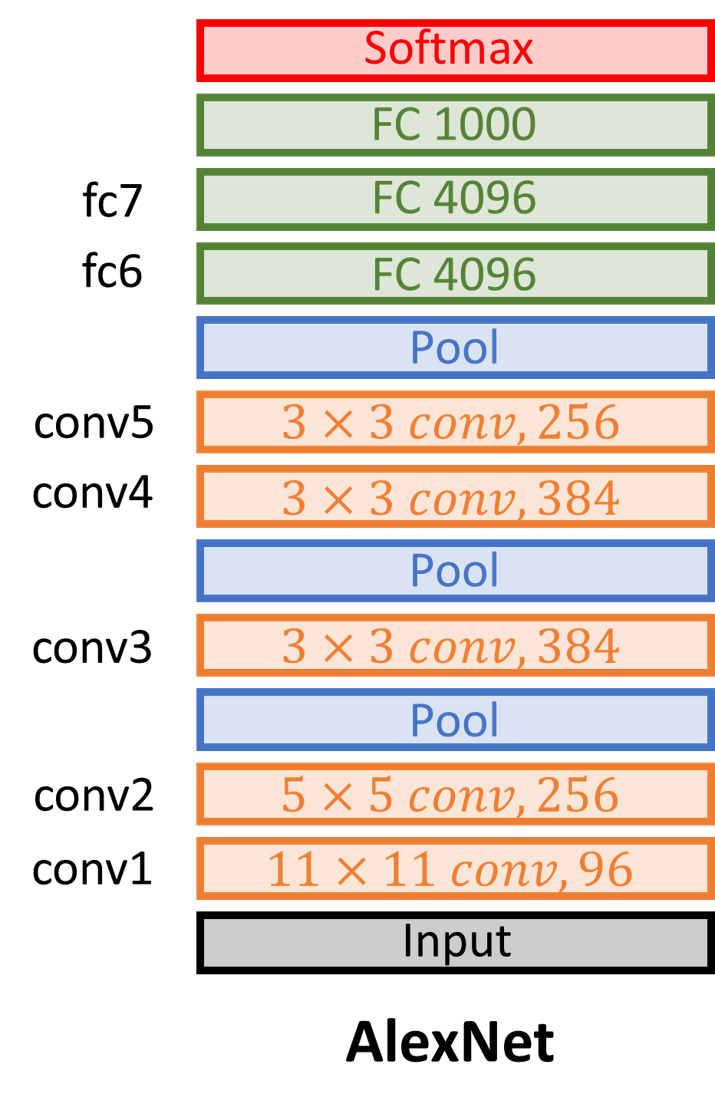
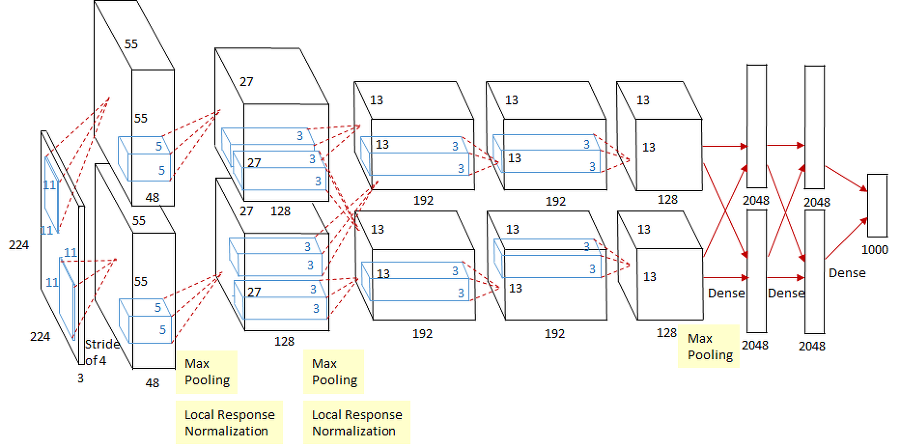

- input image size가 크기 때문에 convolution layer의 stride를 크게해주어 image size를 줄임
- Max pooling, drop out을 사용하고 Relu를 처음 사용함
VGGNet
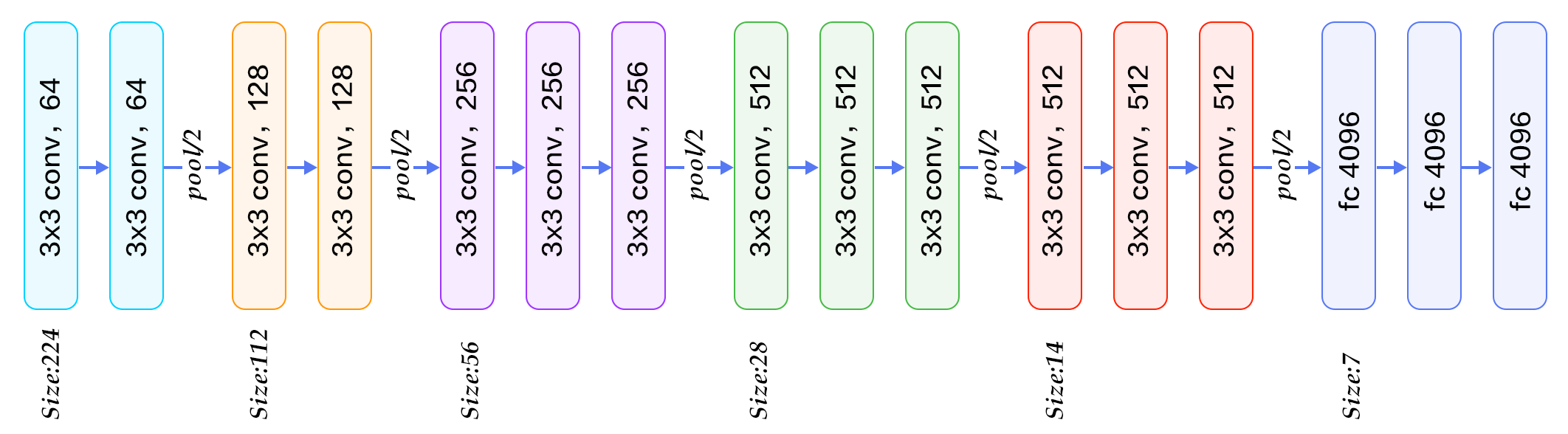
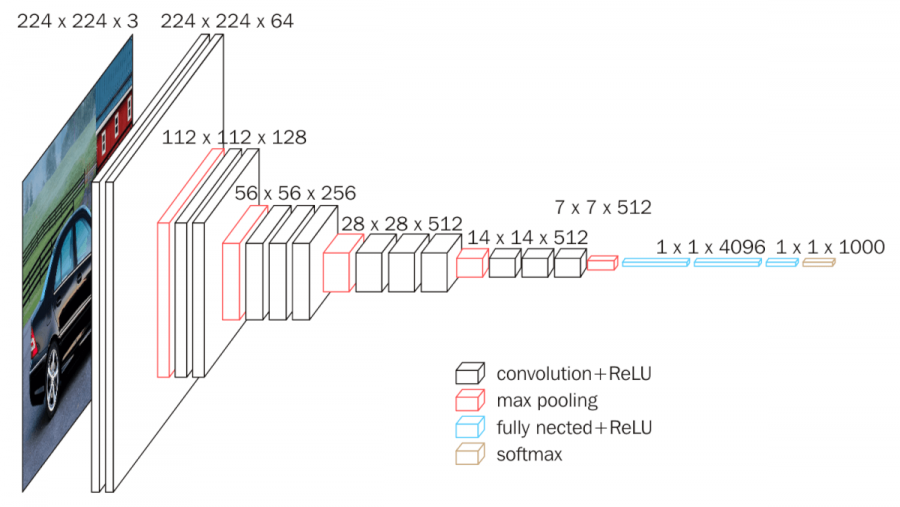
- conv layer(filter =(3,3), stride=1, padding=same)와 pooling layer(filter=(2,2), stride=2)를 반복적으로 사용하여 image channel size가 convolution layer마다 2배씩 증가하고 pooling layer마다 2배씩 감소
inceptionNetwork
-
1X1 Convolution
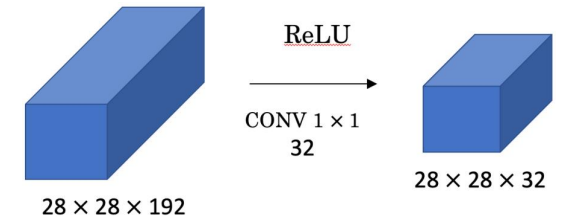
(28, 28, 192) 볼륨에 (1,1,192) convolution 적용 출력 볼륨은 28이고 필터의 수 = channel의 수 이므로 channel의 수를 늘리거나 줄일 수 있다. -
inception module
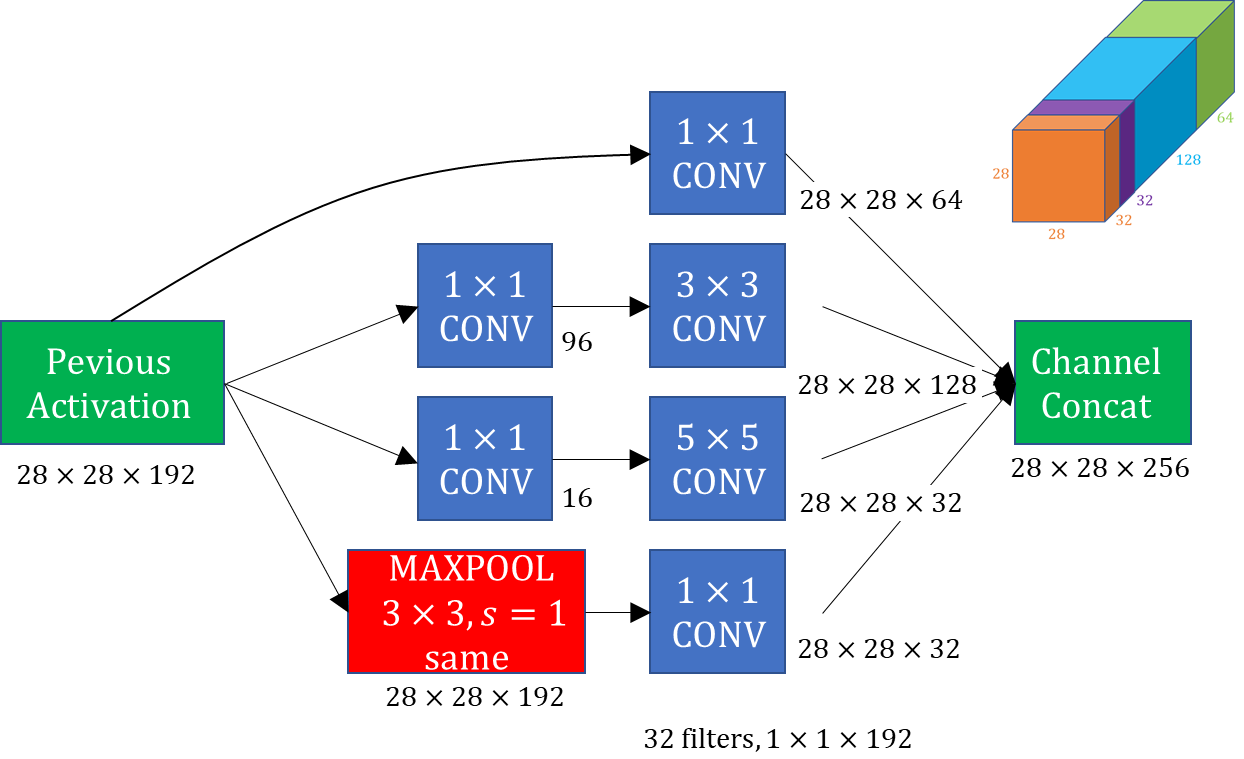
-
input에 대해 convolution(1X1, 3X3, 5X5)과 Maxpooling(3X3)과정을 통해 output을 쌓아 올린다.
-
단점은 연산량이 많아진다는 것이다.
-
inception Modeule은 layer에 1X1 convolution layer를 추가해 bottleneck layer를 구현함으로써 channel 수를 줄이며 연산량을 감소시키는 구조
-
ex) GoogleNet
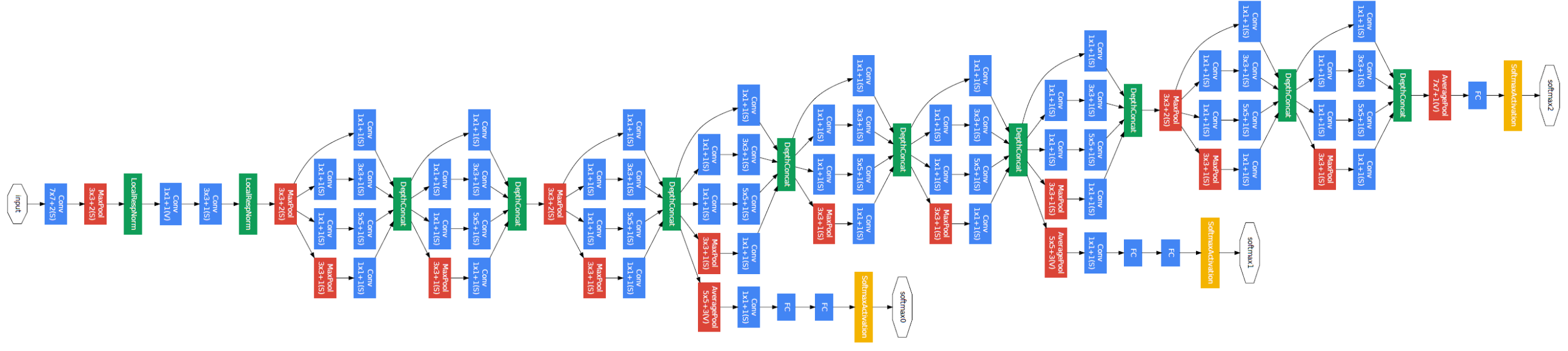
-
중간에 softmax layer가 추가로 달려있어 parameter가 잘 update 되도록 도와주며 output 성능에 도움을 준다.
-
Regularization(weight가 너무 크지 않게 해줌)
-
overfitting 방지
ResNet
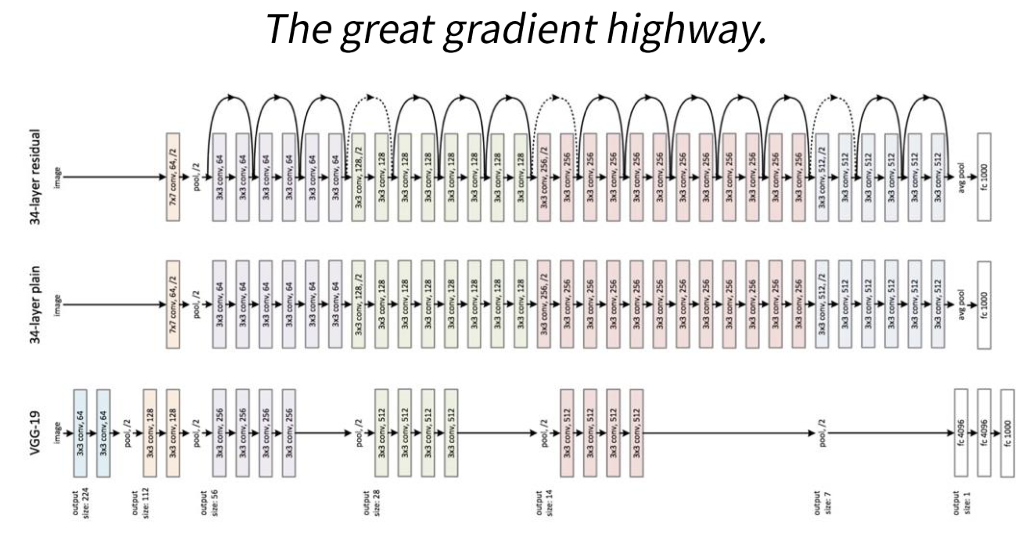
-
VGG-19구조에 conv layer를 추가해 shortcut mapping function 추가
-
Residual Block
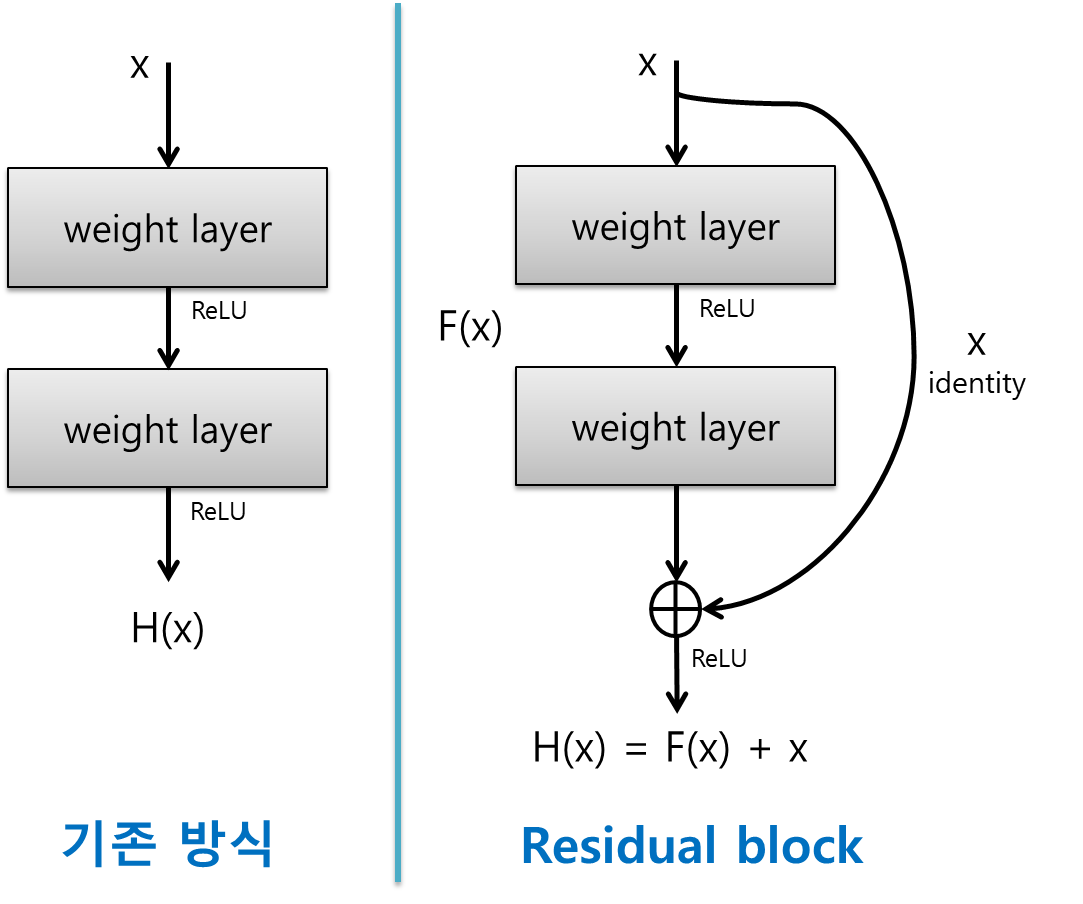
-
vanishing grad/ exploding grad 해소
