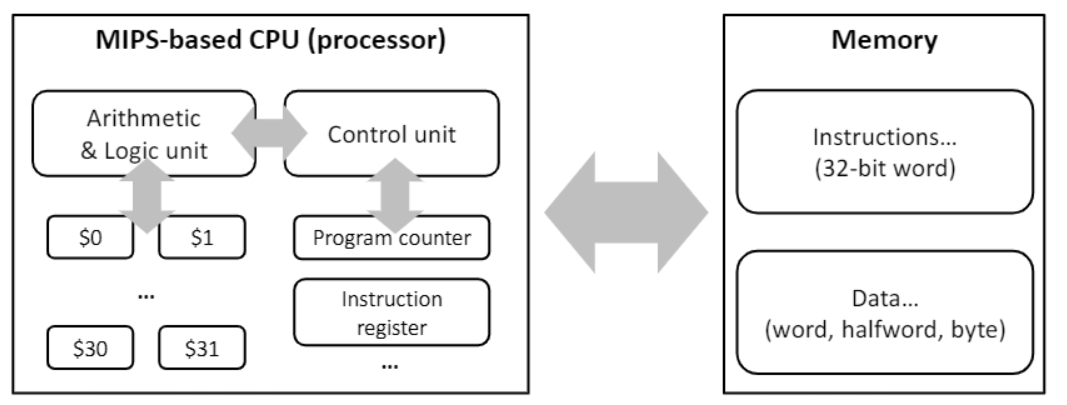
MIPS ISA의 일반적인 HW디자인
- CPU, 레시스터, 메모리
- Control unit(CU)는 프로세서의 작동을 지시한다.
- Arithmetic & logical unit(ALU)는 연산을 진행한다.
- $0,...,$31은 연산에 이용될 값을 가지고 있다. (general purpose register)
- Program Counter(PC)는 수행될 지시사항들의 memory address를 가지고 있다.
- Instruction Register(IR)은 현재 현재 지시사항을 가지고 있다.
- 지시사항의 수행
- 1단계(fetch) : CU는 "PC에 있는 메모리 주소에 있는 지시사항을 IR로 넣어준다."라고 말한다.
- 2단계(decode) : CU는 "IR에 저장되어있는 지시사항의 의미는 ADD $s1, $s2, $s3 이다."라고 말한다.
- 3단계(execute) : ALU는 $s1, $s2에 있는 값의 덧셈 연산을 진행하고 연산 결과를 $s3에 넣어준다.
Arithmetic operation
- 연산 지시사항
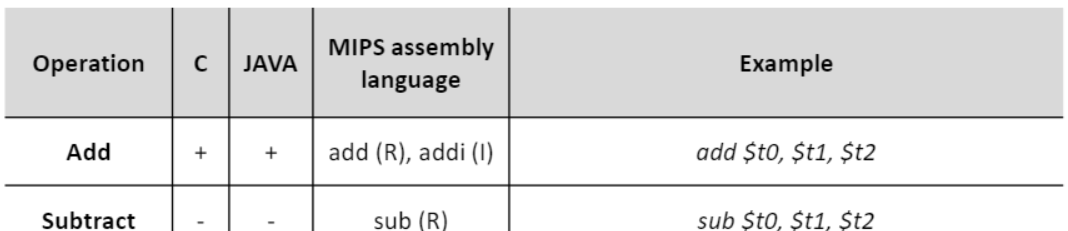
- addi가 있으니까 subi 뺄셈 연산자 존재? (X) -> addi 연산자를 이용하여 뺄셈을 함으로써 지시사항의 수를 줄일 수 있다.(대체 가능시 줄일 수 있다.)
Logical operation
-
비트 단위 조작 지시사항
- word 내의 비트 그룹을 추출하거나 삽입하는데 유용하다.
-
and 연산

-
OR연산
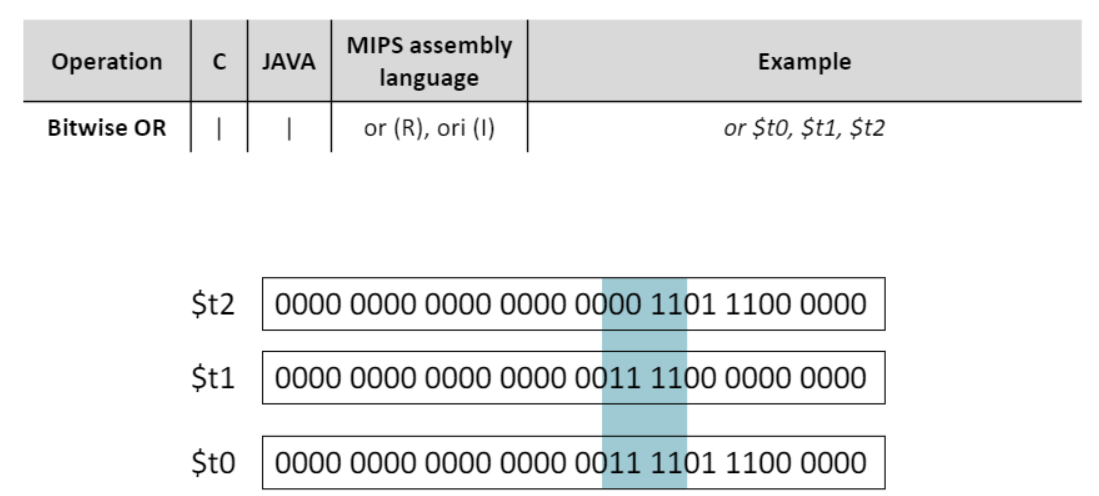
-
NOT 연산
- MIPS는 NOT 연산을 가지고 있지 않다.
- 대신 NOR R-type 지시사항을 가지고 있다.
- a NOR b == NOT(a OR B)
- 하지만 우리는 NOT 연산을 NOR을 이용하여 할 수 있다. : nor $t0, $t1, $zero


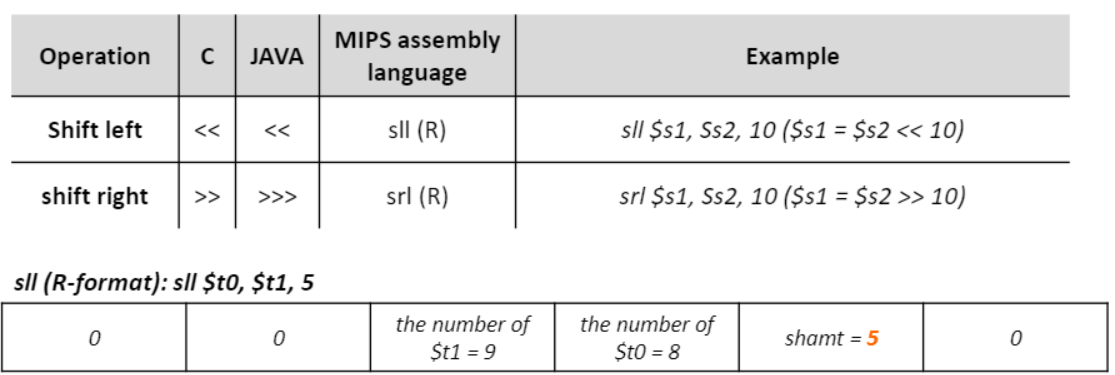
Shift Operation
- shamt : shift할 칸 수
- Shift left/right logic (sll/srl)
- 왼쪽/ 오른쪽으로 옮기고 0비트로 채우기
- (unsigned only) i비트로 sll = 2^(i) 로 곱하기
- (unsigned only) i비트로 srl = 2^(i) 로 나누기
Conditional operations
-
결정을 내리는데 이용하는 지시사항
- 일반적으로 goto statement와 라벨로 이루어져있다.
-
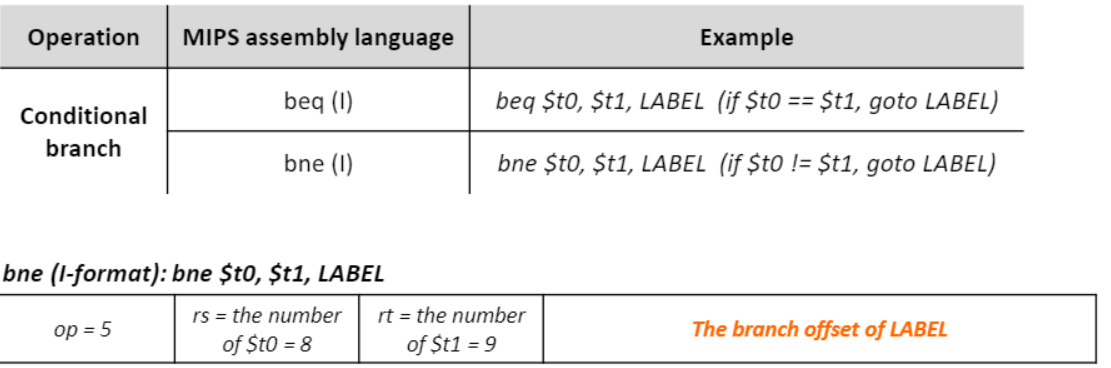
Conditional branch 연산
- beq(brench equal)/bne(branch not equal) 연산 : $t1과 $t2가 같다면/다르다면 LABEL로 이동
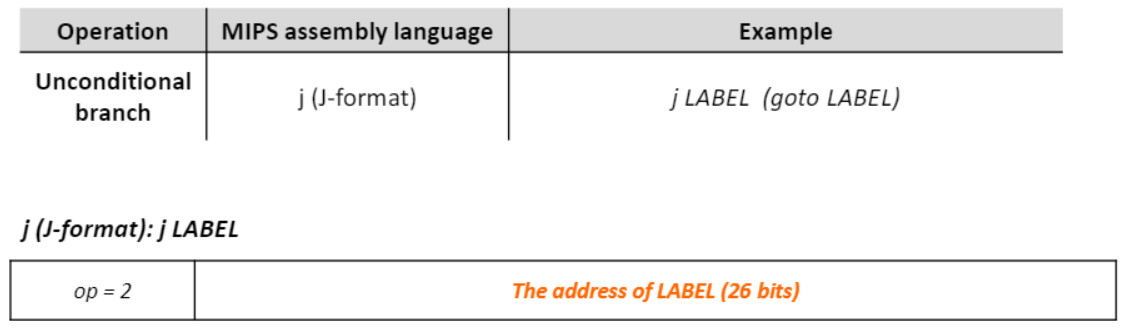
- Unconditional branch 연산
- j(J-포멧) : 조건 없이 LABEL로 이동해라
- 결정을 내리는데 필요한 지시사항
- 일반적으로 go to 지시 사항과 라벨로 구성되어 있다.
- 예시
C 코드 :
if(i == j) k = i+j; else k = i-j; //i,j,k의 주소 $ s0,$ s1, $s2MIPS 어셈블리어 코드:
bne $s0, $s1, ELSE
add $s2, $s0, $s1
j EXIT
ELSE:
sub $s2, $s0, $s1
EXIT:- 예시
C코드 :
while(A[i] != k) i += 1; // i, k의 주소 $s0, $s1, A는 words의 배열이고 base address가 $s2이다.MIPS 어셈블리어 코드:
LOOP: sll $t0, $s0, 2 // 2비트 왼쪽으로 이동하므로 4를 곱한것과 같다고 볼 수있다. i 값을 4배 함으로써 int형 데이터 위치 A[i]를 찾으려고 하는 과정이다.
add $t0, $t0, $s2 // base address에 i*4의 값을 통해 A[i]를 구할 수 있다.
lw $t1, 0($t0)
beq $t1, $s1, EXIT
addi $s0, $s0, 1
j LOOP
EXIT:- 하지만 blt(less than), bge(greater then or equal to)와 같은 branch 지시사항이 존재하지 않는다.
- <, >, <=... 은 =, != 보다 훨씬 복잡하고 느리다.
- 만일 우리가 하나의 지시사항으로 이러한 작업들을 branch와 결합한다면 HW는 더 복잡해질 것이고, 모든 지시사항에 대한 성능은 감소할 것이다.(instruction count 감소, Clock period or CPI 증가-> 성능저하가 일어날 수 있다.)
- beq와 bne는 일반적인 케이스이다.(복잡한 지시사항이 아니다.)
- 대신에 MIPS는 goto 지시사항이 없는(결정 결과만 저장해라) 다른 조건 연사자들을 제공한다.
- slt(set on less then)는 beq와 bne와 함께 이용된다.(더 복밪한 branch instruction가능하지만 ISA는 복잡하게 하지 않는다.)
slt $t0, $t1, $t2
bne $t0, $zero, LABEL // 만일 $t1이 $t2보다 작다면 LABEL로 가라
beq $t0, $zero, LABEL // 만일 $t1이 $t2보다 크다면 LABEL로 가라
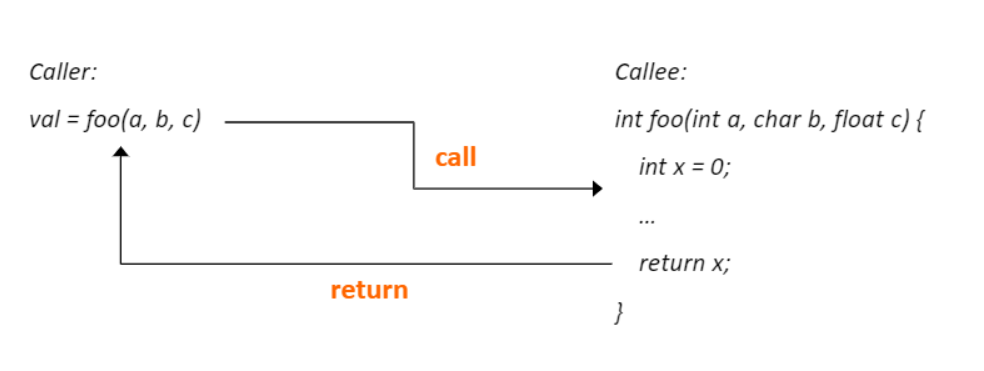
Procedures
- 프로그램 속의 함수들
- 다른 절차들과 calling/returning하는 절차들
- 어느 절차(caller)는 다른 절차(callee)를 호출한다.
- callee는 caller에게 값을 return한다.
-
Calling / Returning
1) caller는 input arguments과 return address(callee 이후 수행될 instruction의 주소)를 callee에게 전해준다.
2) caller는 callee에게 control을 준다.
3) callee는 주어진 input arguments로 연산을 수행한다.
4) callee는 caller에게 return 값을 전해준다.
5) callee는 caller에세 control을 준다.
6) caller는 저장된 것들을 다시 불러온다. -
Q) input params, return address, return values를 어떻게 전달해 줄까?
-> 우리는 위 값들을 전달해주기 위해서 registers를 이용한다.
-
하지만 우리가 생각해봐야 할 점은 다른 procedure가 같은 register를 이용한다면 => register 값은 overwritten 될 것이다.
-
또한 MIPS는 작은 양의 레지스터만을 사용한다, 하지만 우리는 많은 arguments들을 pass하고 싶다.
-
Q) 우리는 이 문제들을 어떻게 처리해야 할까? & 누가 이 문제들을 처리할 것인가?
Procedures : stack
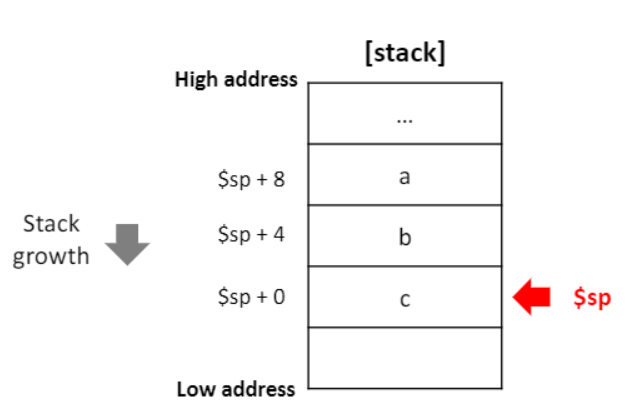
- 각 procedure를 작동시키기 위해 stack을 모든 정보들을 저장하는데 사용한다.(stack을 이용하여 주요한 정보를 이용한다.)
- stack은 메모리에 저장되어 있다.
- $sp 레지스터는 메모리의 stack의 가장 위쪽을 point한다.
- 편리성을 위해서 stack은 낮은 주소로 자라난다.
Procedures : register saving
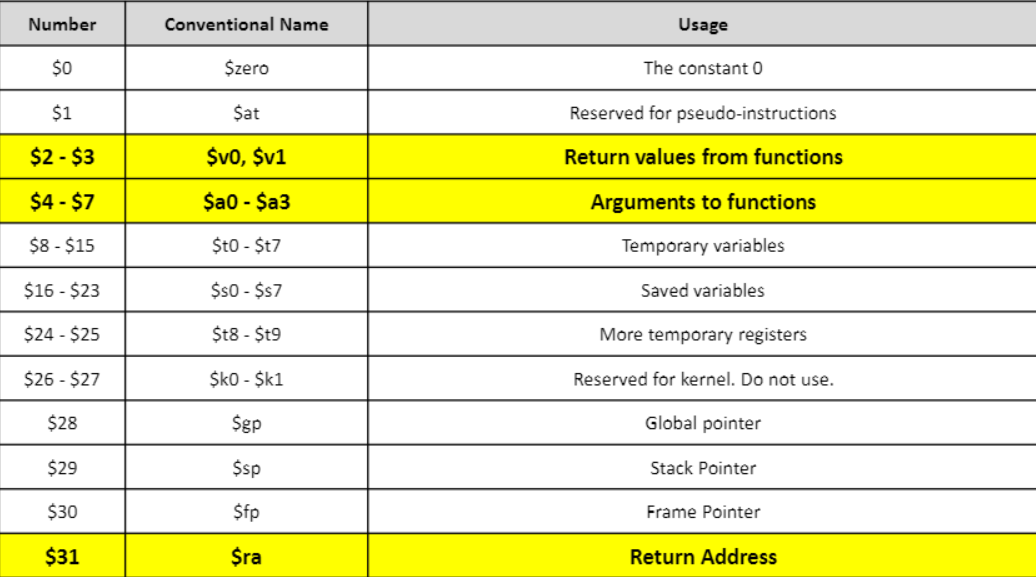
-
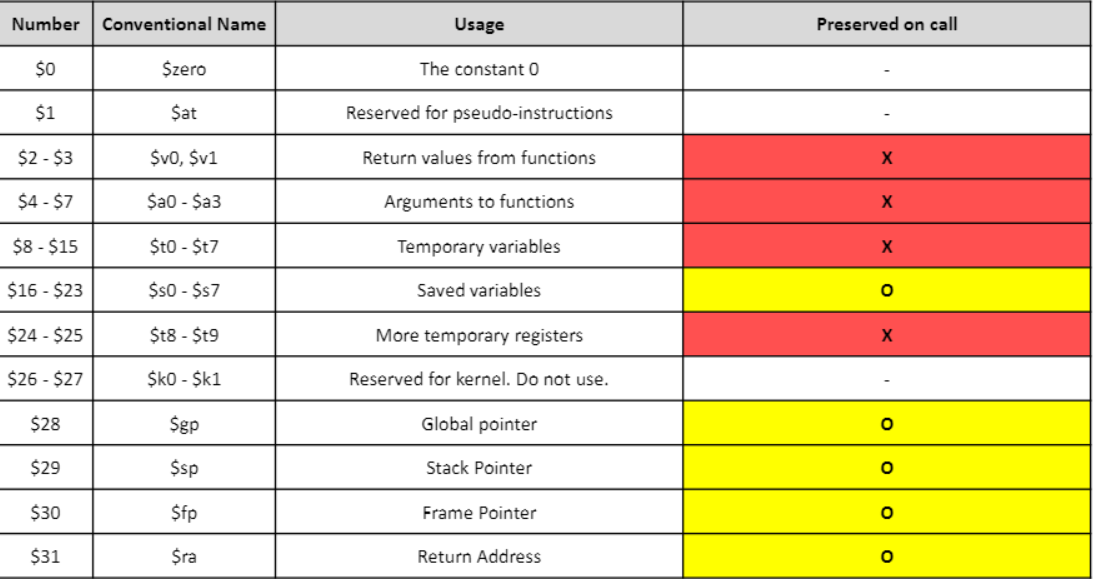
몇몇 레지스터들의 값은 call과정에서 보존되어야 한다.
- 이는 calling/returning이 완수된 이후에도 값들을 복구할 수 있어야 한다.
-
해당 표는 call에서 보존되는 레지스터와 보존되지 않는 레지스터의 값들을 보여준다. (ex) func1 이 func2를 call하였을 때 func1의 $s0는 복구가능하지만 $t0는 복구 불가하다.)
-
callee가 보존되는 레지스터 값을 이용한다면, callee는 calling 이후에 그 레지스터에 있는 값을 stack에 저장하고, returning 이루에 저장되어 있던 값을 복구한다.
-
caller가 보존되지 않는 레지스터들에 값들을 보존해야 한다면, caller는 calling이전에 stack을 값을 저장하고, returning이루에 저장되어있던 값들을 복구한다.

Instructions of procedure calls
- jal PROCEDURE_LABEL
- caller의 return address(calling-returning과정 이후에 진행된 지시사항 위치)는 $ra에 저장이 된다.
- target address로 jump한다(PROCEDURE_LABEL)
- jr $ra
- $ra에 저장된 주소로 jump한다.(다른 register들도 피연산자로 사용될 수도 있다.)
- add $ sp, $ sp, -4 // stack growth가 낮은 주소로 자라나므로 4바이트의 공간을 아래쪽 방향으로 확보해 준다.
sw $ t0, 0($ sp) // $t0 값을 $sp의 top에 저장해 준다.- $t0에 저장되어 있는 데어터를 top-of-stack에 PUSH한다.
- lw $ t0, 0($ sp) // top-of-stack에 저장되어 있는 데이터를 pop하고 $t0에 저장
addi $sp, $sp, 4 // stack pointer가 가리키는 방향을 한칸 낮춰준다.- top-of-stack에 저장되어 있는 데이터를 pop하고 $t0에 저장해 준다.
- 예시)
C코드
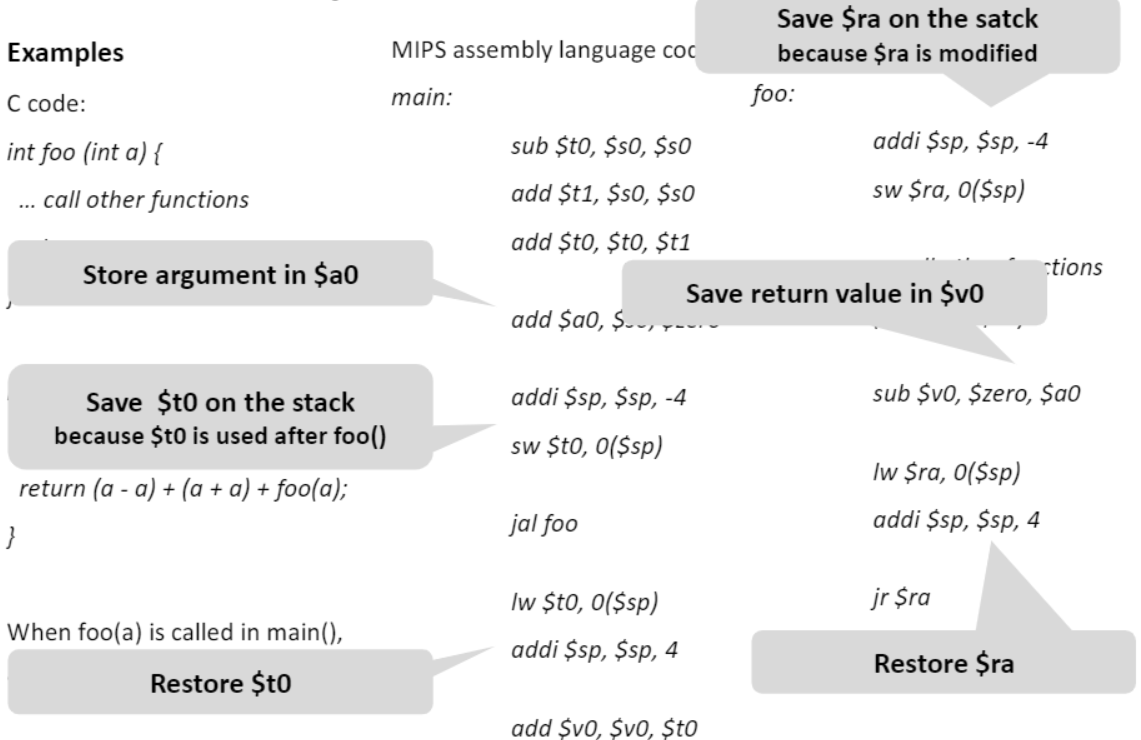
foo(a)가 main()에서 call 되었을 때 a는 $s0에 저장되어 있다.
int foo(int a){
... 다른 function call을 한다
return -a;
}
int main{
...
return (a-a) + (a+a) + foo(a)
}MIPS 어셈블리 언어 코드
main:
sub $t0, $s0, $s0
add $t1, $s0, $s0
add $t0, $t0, $t1
add $a0, $s0, $zero // 인수 passing을 위해서 $a0이용한다.
addi $sp, $sp, -4
sw $t0, 0($sp) // stack pointer의 top에 t0의 값 저장
jal foo // main의 다음 코드의 주소(lw...)를 $ra에 저장한 후에 foo로 jump한다.
lw $t0, 0($sp) // foo함수 진행이전에 $t0의 값을 다시 $t0로 돌려주기
addi $sp, $sp, 4
add $v0, $v0, $t0
foo:
addi $sp, $sp, -4
sw $ra, 0($sp) // stack pointer의 top에 main함수의 return address를 저장해준다.
... 다른 함수 call // (jal, $ra를 수정한다.)
sub $v0, $zero, $a0 // $v0는 return value pass를 위해 사용된다.
lw $ra, 0($sp) // $ra에 main함수의return address를 넣어준다.
addi $sp, $sp, 4
jr $ra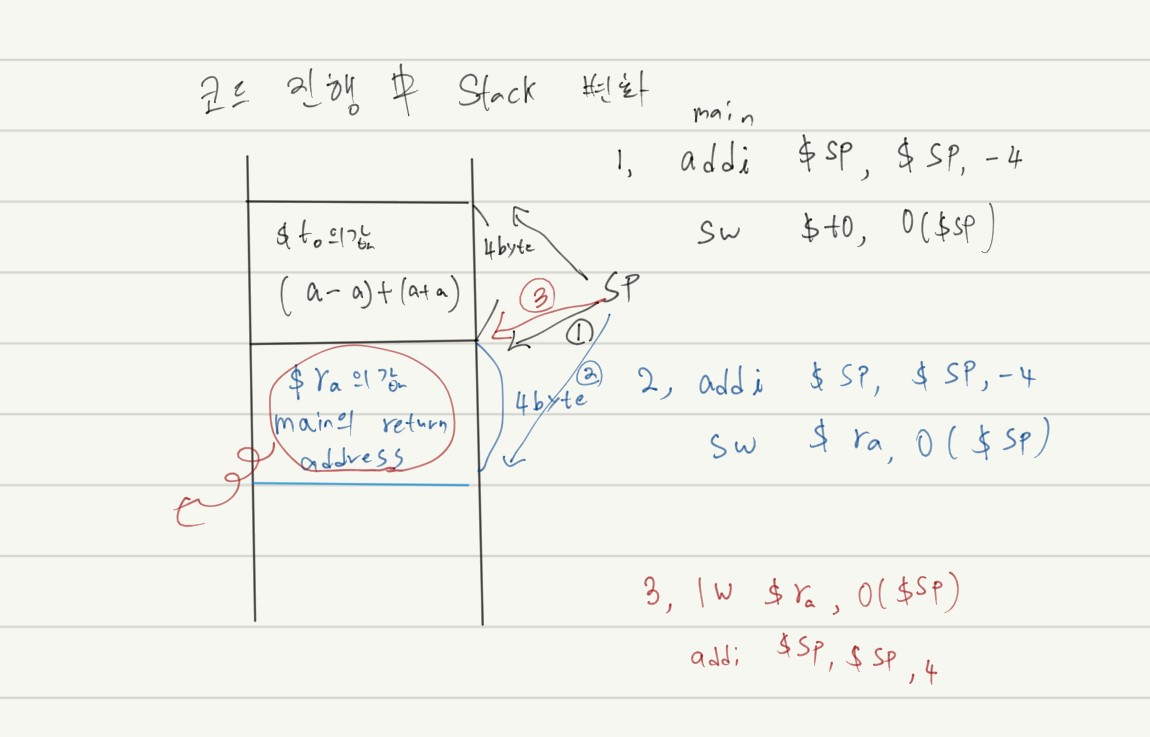
- 연습 : leaf procedure(callee,다른 프로시저를 호출하지 않는 프로시저)
C코드
- a,b,c,d는 $a0, ... , $a3(pass argument) 에 존재
- e는 $ s0에 저장될 것이다.($ s0는 스텍에 저장해야함.)
- $v0에 결과값을 넣어줄 것이다.
int leaf(int a, b, c, d){
int e;
e = (a+b) - (c+d);
return e;
}MIPS 어셈블리어 코드
leaf:
// 1. $s0를 스텍에 저장
addi $sp, $sp, -4
sw $s0, 0($sp)
// 2. 작업 진행
add $t0, $a0, $a1
add $t1, $a2, $a3
sub $s0, $t0, $t1
add $v0, $s0, $zero
// 3. $s0를 restore
lw $s0, 0($sp)
addi $sp, $sp, 4
// 4. Return
jr $ra- 연습 : non-leaf procedure(다른 프로시저를 call하는 프로시저)
C코드
- n은 $a0에 있다.
- 결과는 $v0에 있다.
int sum(int n){
if(n == 0) return 0;
else return (n + sum(n-1));
}MIPS 어셈블리어 코드
sum:
bne $a0, $zero, L1
add $v0, $a0, $zero
jr $ra
L1:
addi $sp, $sp, -8
sw $ra, 4($sp) // $ra는 preserved로서 callee가 스텍에 return address 저장
sw $a0, 0($sp) // $a0는 non-preserved로서 caller가 stack에서 저장해야 한다.
addi $a0, $a0, -1
jal sum
lw $ra, 4($sp)
lw $a0, 0($sp)
addi $sp, $sp, 8
add $v0, $v0, $a0
jr $ra
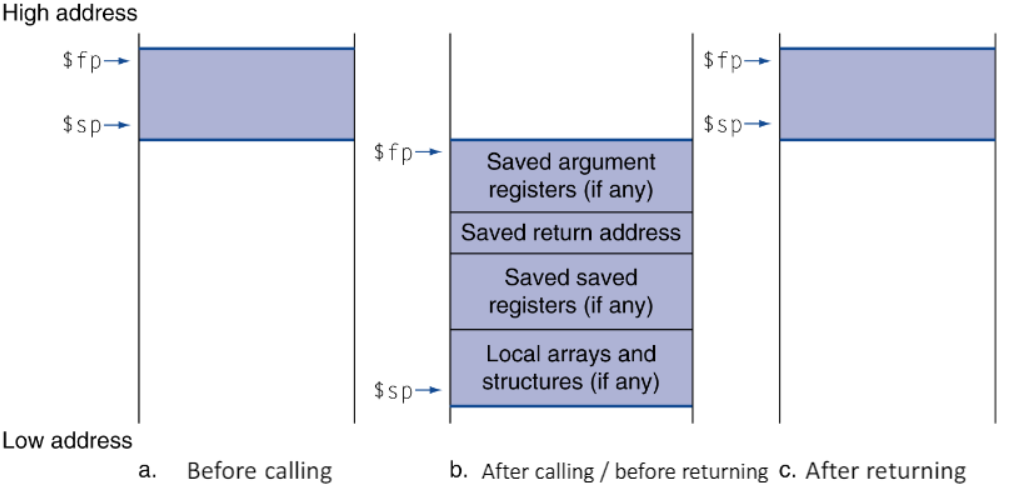
MIPS 메모리 할당 : local data
- procedure call에서 register와 local variable은 stack에 저장되어 있다.
- 우리는 stack의 분할을 "activation record", "procedure frame"이라고 부른다.
- frame pointer($fp)는 frame의 첫 word를 point한다.
- 프로시저의 수행 과정에서 $fp는 안정되어 있다. 이는 변수의 high address를 언급하기 위해 사용된다.
- 쉽게 이해하기 위해 activation record의 higest address는 $fp, lowest record는 $sp로 특정 함수의 공간을 위치해준다.
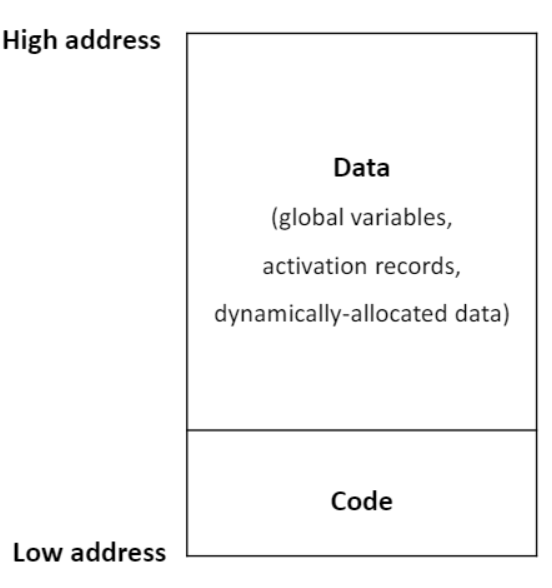
MIPS 메모리 할당 : data + code
- 프로그램에는 다양한 type의 data+code가 존재한다.
e.g.) global data, dynamically allocated data,...
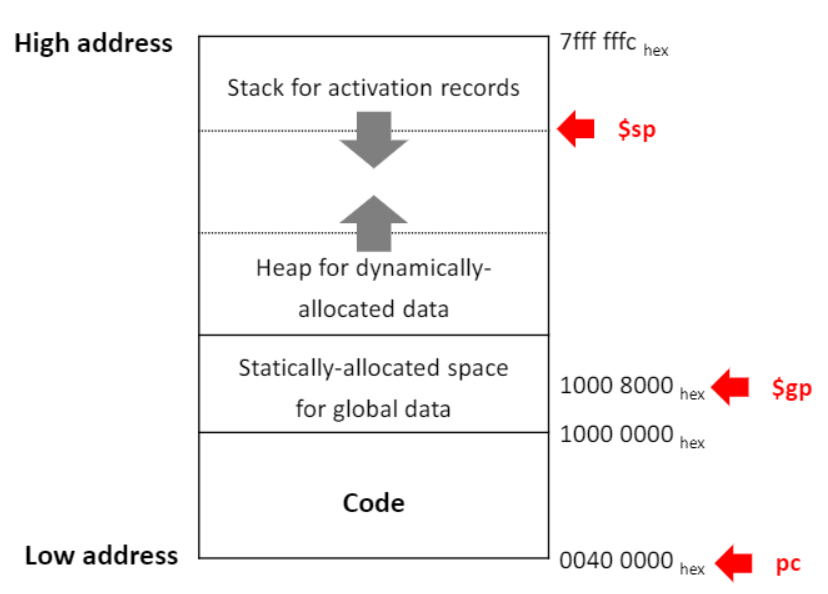
- Global variable
- global variable에 대한 참조는 같은 곳을 point 한다. (main(), foo() 모두 global var a를 가르킨다. a의 life cycle은 프로그램의 life cycle과 동일하다.)
- global variabel은 activation record에 저장될 수 없다.
- 대신에 global variable들은 고정된 주소에 할당된다.
- Activation records
- stack에서 관리된다.
- stack growth는 high address -> low address로 성장한다.(stack 포인터는 메모리 공간에서 위에서 아래로 증가)
- activation record의 life cycle은 주어진 프로시저의 life cycle과 동일하다.
- Dtnamically-allocated data (ex. malloc())
- 동적으로 할당된 데이터는 heap에서 관리된다.
- heap growth는 low address -> high address로 성장한다.(stack과의 출돌을 피하기 위해서 반대호 heap pointer는 메모리 공간에서 아래에서 위로 증가한다.)
- 동적 할당된 데이터의 life cycle은 malloc() ~ free() 까지가 된다.
- MIPS의 메모리 주소는 32비트로 구성되어 있다. (MIPS 64는 64비트)
- 즉 0000 0000 ~ ffff ffff 총 4GB 크기의 메모리 공간 존재
-
Q) 야 load/store instruction에서 address offset을 저장하는데 드는 비트수는 얼마인가?
-
A) I-form에서 opcode: 6비트, rs: 5비트, rt: 5비트, offset: 16비트로 offset을 표현하는데 드는 비트 수는 16비트이다.
-
Q) 그럼 우리가 메모리의 모든 부분을 어떻게 접근해야 되는거냐?
Addressing mode
- 우리가 지시사항을 디코딩한 후에 우리는 상응하는 일을 수행할 것이다.
- 이때, 우리는 data또는 지시사항에 접근을 해야 한다.(이는 instructions, 레지스터, 메모리 등에 저장될 수 있다.)
1. Immediate addressing(데이터가 instruction에 존재)
- instruction에 포함되어 있는 data에 직접적으로 접근한다.
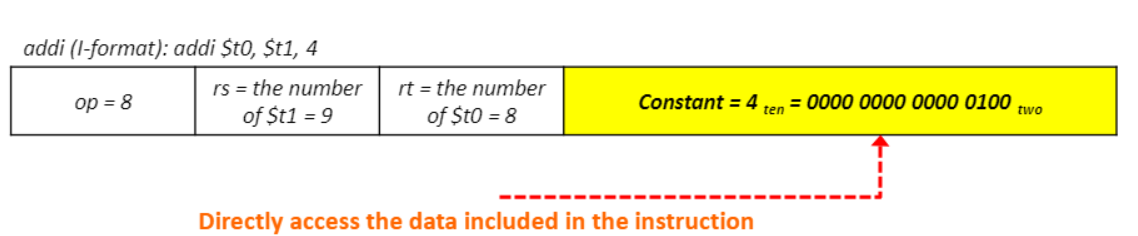
2. Register addressing(데이터가 register에 존재)
- instruction에서 사용된 data가 저장되어 있는 register로 접근한다.
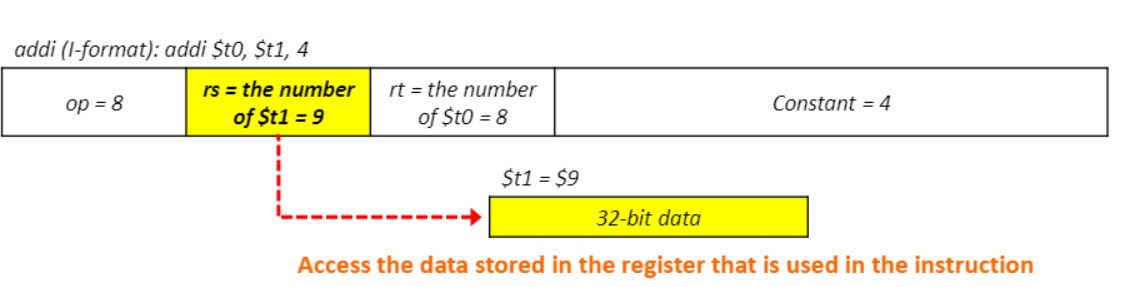
3. Base addressing(data가 메모리에 존재 -> load/store)
-
1) 레지스터에 접근한다.($ s0 = base address에 접근하는데) & immediate 피연산자(offset 접근하는데)
-
2) target address를 계산한다. (target address = base address + offset(16비트의 signed num))
-
3) target memory 주소의 데이터에 접근한다.
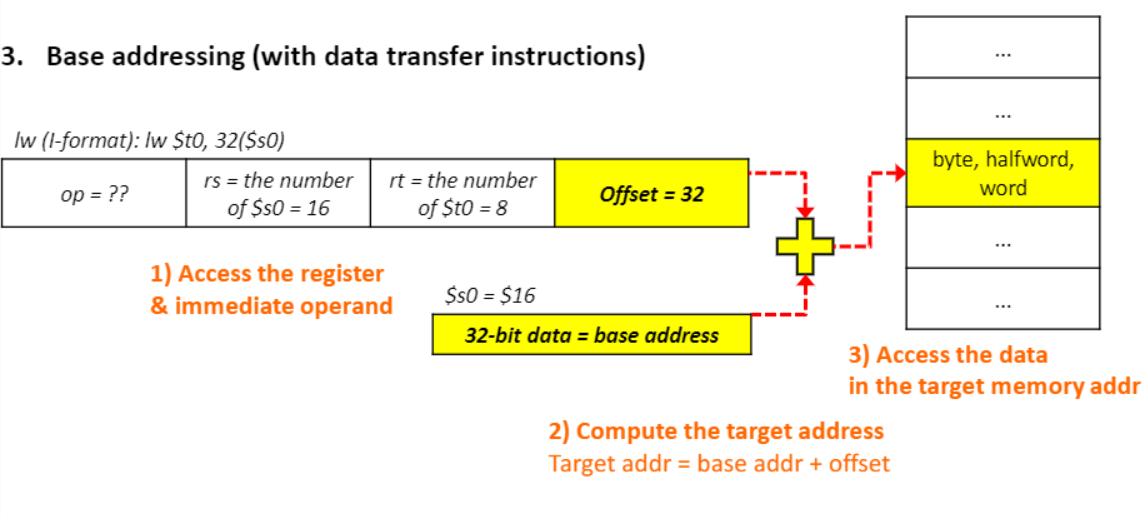
4. PC - relative addressing(현재 지시사항 주소 -> branch instruction)
-
가정 : 대부분 branch의 target은 현재 instruction과 근처에 존재한다.
-
HW 구현에서 PC는 현재 지시사항을 컴퓨팅하기 전에 4(MIPS instruction 32비트 = 4바이트)가 이미 증가해 있다.
-
1) immediate operand(offset) & PC에 접근한다.
-
2) target address를 계산한다. (taget address = PC + offset X 4 -> offset X 4 = offset << 2 더 많은 표현 가능)
-
3) target 메모리 주소의 instruction에 접근한다.
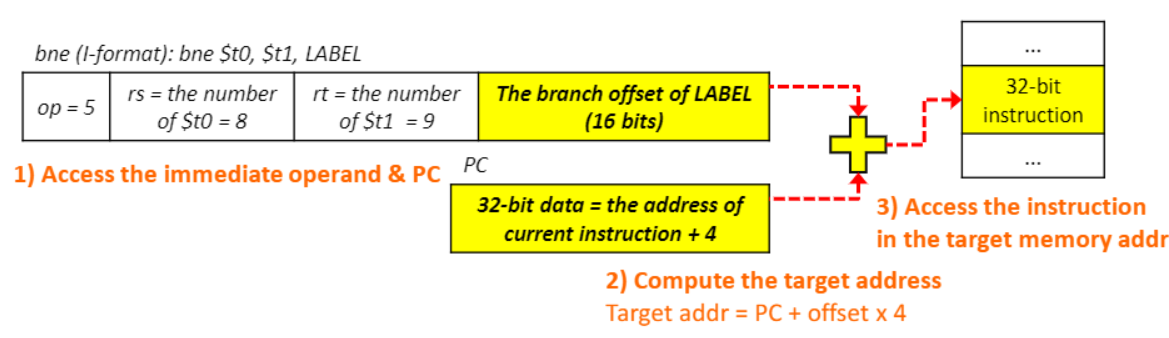
- 예시)
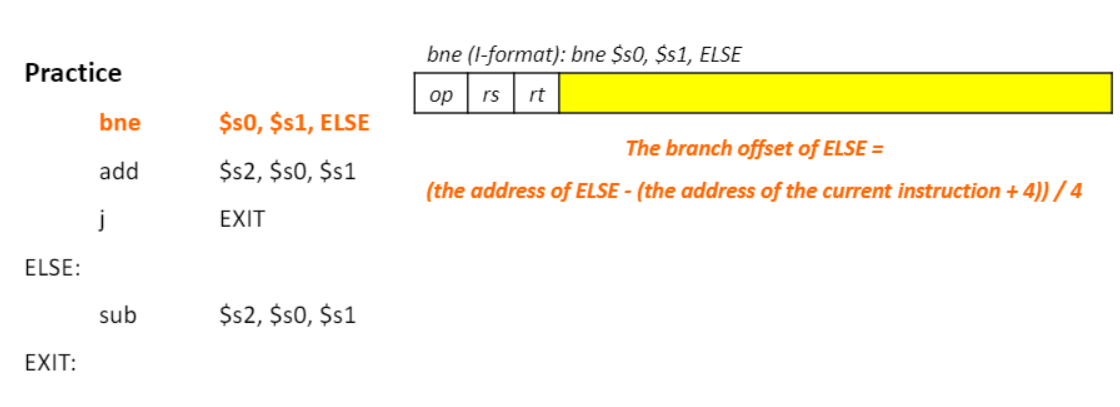
-
해당 코드에서 bne $ s0, $ s1, ELSE 부분의 코드의 주소가 0이라고 하자 add는 4, j는 8, ELSE는 12가 된다.
-
bne에서 target address(Else주소) = PC + offset X 4 = add instruction 주소 + (ELSE 주소 - (add instruction 주소)/4) X 4 = 12
5. Pseudo direct jump addressing(with branch instruction)
-
1) instruction & PC 주소로 접근
-
2) target address를 연산한다.(target address는 32비트 여야 하므로 target addr(32비트) = PC의 31...28(0000) 과 address X 4(28비트)를 병합한다. -> target address는 0000 ....으로 나옴)
-
3) target memory addr의 instruction에 접근한다.
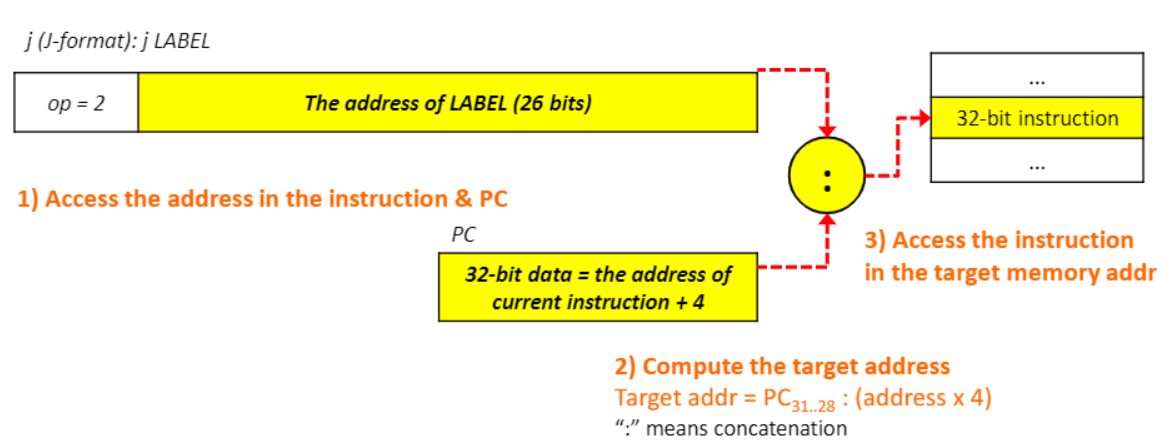
- 예시)

-
EXIT의 address를 80000이라고 하자
-
PC는 79992값을 가지고 있다.
-
target address = PC31...28(0000) : address of Exit X 4
-
EXIT의 저장된 주소 = EXIT의 address /4 = 20000
Q) 만일 branch가 16비트의 offset을 가지고 표현하기 너무 멀다면 우리는 어떤식으로 code를 다시 작성해야 할까?

-
다음 beq에서 L1의 address가 2^17 보다 크다고 할 때
-
우리는 bne로 반대의 경우 코드를 작성한 후 jump를 진행한다.
32-비트 상수 지원
-
가끔 우리는 32비트 상수를 이용할 일이 생긴다.
-
MIPS는 32비트의 immediate operand를 "lui"라는 특별한 instruction을 지원한다.
- lui instruction(i-format)은 16비트의 상수를 기반으로 상위 16비트의 레지스터를 정리한다.
-
예시)
lui $ s0, 61 // 61(10진수) = 0000 0000 0011 1101(2진수)
# lui instruction이루 $s0에 저장되어 있는 레지스터의 값은
0000 0000 0011 1101 0000 0000 0000 0000(2진수) 가 된다. // 뒤의 값은 모두 0으로
# ori 명령어는 OR연산을 진행한다.
ori $s0, $s0, 2304 //2304(10진수) = 0000 1001 0000 0000(2진수)
# 이 두 명령을 진행하고 나서 $s0의 값은
0000 0000 0011 1101 0000 1001 0000 0000(2진수) = 4000000(10진수)- 명령어에 접근하는 대신에 레지스터에 있는 32비트의 상수를 lui와 ori를 이용하여 저장할 수 있다.
ISA 디자인 더보기
-
더 좋은 연산을 제공하는건 어떤가? (blt, bge..)
- 이는 instruction count를 줄일 수 있다.
- 하지만 이는 clock period/CPI를 증가시킨다.(HW의 복잡도를 늘리기 때문에)
- 이는 instruction count를 줄일 수 있다.
-
작업 복잡성이 늘어나면 위험하므로, 간단한 instruction만을 사용한다.
-
common ISA를 빠르게 만들어라!!
요약
-
ISA는 컴퓨터 언어이다 & SW와 HW사이의 interface이다.
-
ISA는 다음을 정의한다.
- instruction type
- data format
- instruction format
- data/instruction 접근 방법
- 프로시저를 지원하는 방법
-
MIPS ISA는 아래의 디자인 원칙을 통해 디자인 되었다.
- 디자인 원칙 1 : 단순성은 정규화를 선호한다.
- 모든 산술 지시사항들은 단일 operation과 3개의 피연산자를 포함한다.
- 디자인 원칙 2 : 작은것이 더 빠르다.
- MIPS의 연산 지시사항의 피연산자는 작은 수의 register로 결정되어야 한다. MIPS는 더 복잡한 데이터는 메모리에 넣고 메모리와 레지스터 사이의 data transfer를 지원한다.
- 디자인 원칙 3 : 일반적인 case를 더 빠르게 만들어라
- 상수 제어에 16비트의 immediate operands를 이용한다 + $zero(0레지스터이용 -> 많이 쓰기 때문에)
- 디자인 원칙 4 : 좋은 디자인은 좋은 comprise를 요구한다.
- 모든 지시 사항들을 같은 길이 + 지시사항의 format을 최대한 비슷하게 해라 data들은 또한 2's complement rule에 근거해 이진수 표현을 한다.
- 디자인 원칙 1 : 단순성은 정규화를 선호한다.
