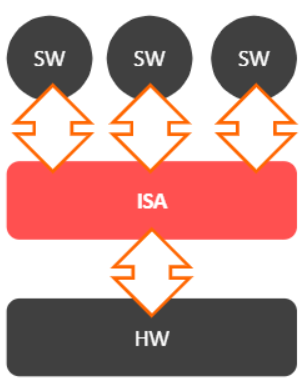
Instruction Set Architecture(ISA)
- 컴퓨터의 언어 & SW와 HW 사이의 인터페이스
- 이는 밑과 같이 정의된다.
- 지시 사항의 종류(e.g. 산수, 조건, 데이터 전송, branch,....)
- 지시 사항대로 data를 이용하는 방법
- 데이터의 형태
- 지시 사항의 형태
- 지시 사항들은 프로그램의 성능에 영향을 미친다.
CPU time = Instruction count X CPI X Clock period
- 서로 다른 컴퓨터들은 다르지만, 약간 유사한 지시 사항들을 가지고 있다.
- 왜 유사한가?
- 컴퓨터가 무조건 제공해야하는 기본적인 작동이 있다.(e.g. add, multiply, load, store....)
- 공통의 목표를 달성하기 위해 디자인 되었다.(공통 목표 : "성능을 최대화 하고, 가격과 에너지를 최소화 하면서 HW와 컴파일러를 만들기 쉬운 언어를 찾는다.")
MIPS ISA
-
우리는 MIPS라고 불리는 특정한 ISA디자인에 대해 알아볼 것이다.
-
MIPS : Microprocesser without Interlocked Pipelined Stages
- MIPS-기반의 프로세서는 90년대에 가장 잘 팔리는 프로세서였다.
- 임베디드 시스탬의 상당량이 여전히 MIPS를 이용하고 있다.
- 가장 최근의 ISAs(e.g. x86, ARMv7, ARMv8)또한 MIPS와 유사한 아키텍처를 가지고 있다.
-
MIPS의 디자인 원칙의 지식에 기반으로 하여, 우리는 다른 ISA들을 이해할 수 있으며, 새로운 ISA를 만들어 낼 수 있다.
-
가장 중요한 디자인 원칙
- 원칙 1 : 단순성은 규칙적인 것을 선호한다.
- 원칙 2 : 작은것이 더 빠르다.
- 원칙 3 : 공통의 경우를 가장 빠르게 만들어라.
디자인 원칙1
-
단순성은 규칙적인 것을 선호한다.
-
정규화 : 모든 MIPS 산술 지시사항은 1개의 연산과 3개의 피연산자를 포함한다.
- MIPS 어셈블리어 예시
- add a,b,c // a = b + c
- sub a,a,b // a = a - b

- MIPS 어셈블리어 예시
-
정규화는 구현을 더욱 단순하게 만든다.
- 고정된 숫자의 피연산자를 가진 HW는 다양한 피연산자 수를 가진 HW보다 더 단순하다.
-
정규화는 더 높은 성능을 더 낮은 비용으로 가능하게 만들어준다.
-
예제) 언어 번역
C 코드
f = (g+h) - (i+j)
MIPS 어셈블리 언어로 컴파일 했을 때
add t0, g, h
add t1, i, j
sub f, t0, t1
디자인 원칙2
-
작은 것이 더 빠르다.
-
피연산자에 대한 MIPS의 산술 지시 사항은 작은 수의 레지스터를 선택해야 한다.
-
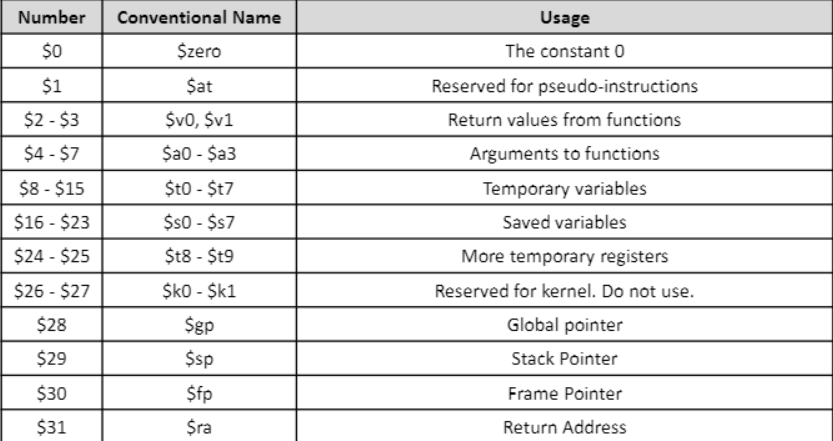
레지스터란?
- 데이터를 위한 빠른 위치들
- MIPS에서는 32개의 32-bit 레지스터가 존재한다.(MIPS64에는 64개의 64-bit 레지스터 존재)
-
왜 MIPS는 32개의 레지스터만 사용하냐?
- 아주 큰 숫자의 레지스터는 clock period를 증가시킬 수 있다.
- 왜냐면 이는 멀리 이동할 때 전기적 신호를 더 많이 쓰기 때문이다.
-
MIPS 디자이너는 레지스터의 #과 clock period 사이에 균형을 맞추기 위해 노력했다.
-
32는 5비트를 나타낸다고 할 수 있다.(32 = 2^5)
-
디자인 원칙에 따라
1. 모든 MIPS 산술 지시사항은 단일 피연산자 & 3개의 피연산자를 포함하고 있다.
2. 산술 연산자의 피연산자는 32개의 레지스터들 중 하나에서 선택되어야 한다. -
예제) 언어 번역
C 코드
f = (g+h) - (i+j); // f,g,h,i,j가 s4레지스터들에 할당되어 있다고 가정하자.
MIPS 어셈블리 어로 컴파일됬을때 코드
add $t0, $s1, $s2
add $t1, $s3, $s4
sub $s0, $t0, $t1
메모리 지시사항 : 메모리 정렬
-
프로세서는 레지스터에 작은 양의 데이터를 저장해 놓을 수 있찌만, 우리의 실제 세계의 프로그램들은 더 많은 변수들을 가지고 있다. 그들 중 상당부는 복잡한 데이터 구조를 지니고 있다.(e.g. 배열...)
-
우리는 그런 남은 또는 복잡한 구조를 유지하기 위해 메모리를 사용한다.
- 메모리는 몇십억의 데이터 구성요소를 가지고 있는 큰 일차원적인 배열이다.
-
레지스터 피연산자를 요구하는 MIPS 산술연산 지시사항을 위해 MIPS는 두 종류의 데이터 전송 지시사항을 제공한다.
- 값을 메모리에서 레지스터 안으로 Load한다.
- 결과를 레지스터에서 메모리로 저장한다.
메모리 지시사항 : address
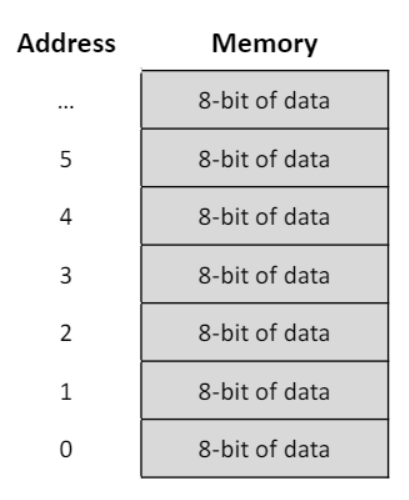
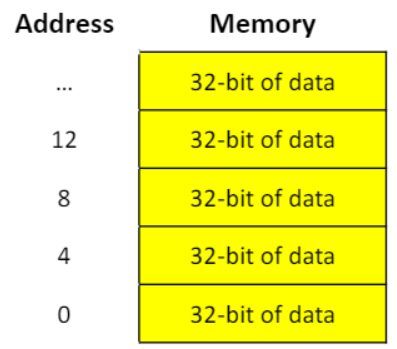
- 메모리 주소는 0에서 시작하는 메모리 배열의 인덱스 값이다.
- MIPS는 byte addressing을 이용한다.(각 주소는 8-bit 의 데이터를 식별한다.)
- 하지만 대부분 데이터 요소들은 1byte보단 크므로 "words"를 이용한다.
- MIPS에서 word는 32비트다
- 레지스터는 32비트의 데이터 만을 가지고 있다.
-
정렬 제약
- 데이터는 일반적인 범주 내에서 메모리에 할당되어야 한다는 요구 사항.
e.g) 각 데이터의 시작주소는 N의 배수여야 한다.(N이 데이터의 크기일 때) - 이것은 논리의 단순화를 만들어준다.
- MIPS에서 words는 4의 배수의 주소만을 가질 수 있다.
- 데이터는 일반적인 범주 내에서 메모리에 할당되어야 한다는 요구 사항.
-
몇몇 데이터는 1또는 2 바이트를 이용한다(halfword). 그들은 1또는 2바이트 할당되어 있다.
-
Q1) A[]은 halfword의 배열이다. A의 base address는 0이다. 그럼 ,A[5]의 시작 주소는 무엇인가?
A는 halfword이므로 데이터의 크기는 2이다. A[0]의 시작 주소가 0이므로 A[5]의 시작 주소는 2X5 = 10이 된다.
- Q2) a,b,c 3가지 변수가 순차적으로 메모리에 저장되었을 때 a,b는 1바이트가 필요했지만 c는 word이다. a의 시작 주소가 0이라고 할 때 c의 시작 주소는 얼마인가?
a, b는 1바이트가 필요하므로 메모리에 a의 시작주소 0, b의 시작 주소 1로 2바이트 크기의 공간을 차지하고 있다. c는 word즉 4바이트 크기를 지니고 있으므로 시작 주소가 4의 배수여야 한다. 즉 2는 시작 주소가 될 수 없고 4가 시작 주소가 된다.
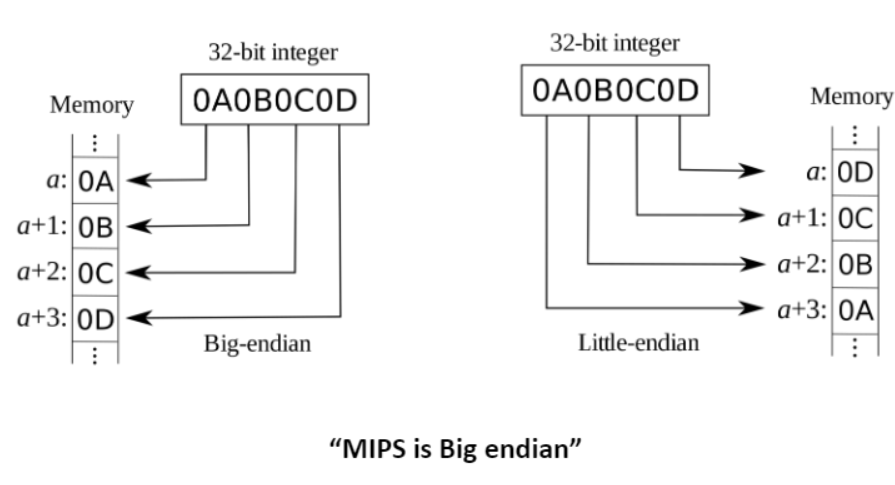
- Byte ordering
- 빅인디언 : 가장 큰 바이트를 가장 처음에 넣고 가장 작은 바이트를 마지막에 넣는다.
- 리틀인디언 : 가장 작은 바이트를 가장 처음에 넣고 가장 큰 바이트를 마지막에 넣는다.
-
lw reg1 offset(reg2) : 32비트의 메모리 주소를 가리키는 주소값 (reg2의 값 + offset)에서의 값을 reg1으로 넣는다.(load명령어)
-
sw reg1 offset(reg2) : reg1의 값을 32비트의 메모리 주소를 가리키는 주소값 (reg2의 값 + offset)에 저장한다.(store 명령어)
-
이런 지시사항들은 byte addressing을 통해 word를 load하고 저장한다.
-
lh/sh와 lb/sb 지시사항은 halfwords(16비트), 8비트의 데이터를 load하고 저장한다.
-
예제
c코드
g = h + A[8]
A는 4바이트의 word이다.
g와 h의 값은 $s1과 $s2에 저장되어 있다.
A의 base 주소는 $s3이다.
MIPS 어셈블리어로 컴파일
lw $ t0, 32($s3) // A배열의 첫번째 주소 + offset(32)을 t0 레지스터에 넣어준다.
add $s1, $s2, $t0 // g에 h와 A배열을 더하여 저장해 준다.
메모리 지시사항 연습
- 연습1
c코드
A[12] = h + A[8]
A는 4바이트 words 배열이다.
h의 값은 $s2에 존재한다.
A의 base 주소는 $s3에 존재한다.
MIPS 어셈블리 언어로 컴파일한 코드
lw $ t0, 32($ s3)
add $ t0, $ s2, $ t0
sw $ t0, 48($s3)
- 연습2
c코드
f = (g+h) - (i+j);
f,g,h는 $s0, $s1, $s2에 각각 존재한다.
halfwords i와 j는 각각 메모리에 연속적으로 저장되어 있다.
i의 시작 주소는 $s3에 저장되어 있다.
MIPS 어셈블리어 컴파일 코드
add $ t0, $ s1, $ s2
lw $ t1, 0($ s3)
lw $ t2, 2($ s3)
add $ t3, $ t1, $ t2
sub $ s0, $ t0, $ t3
Registers Vs memory
-
레지스터는 메모리보다 접근하기 빠르다.
-
메모리의 데이터 연산은 추가적인 지시사항을 요구한다.(load, store)
-
가장 좋은 성능을 위해선, 컴파일러는 레지스터를 가능한 많이 사용해야 한다.
-> 레지스터 최적화가 아주 중요하다.
디자인 원칙3
-
일반적인 case를 빠르게 만든다.
-
Common case : 프로그램은 연산과정에서 상수를 많이 사용한다.
- 예시
- 배열에서 다음 요소를 가리키도록 인덱스를 증가시킨다.
- 대부분의 프로그램에서 50%의 피연산자는 작은 상수값이다.(a = a+5)
-
solution : 상수를 다루기 위한 16비트의 immediate 피연산자를 지원한다.(항상 메모리로 접근하는 것은 비효율적이다.)
- immediate 피연산자는 작은 상수를 의미한다.(1,2,3,4....)
- addi $t0, $t0, 4 // addi는 add의 immediate instruction이다.
- 우리는 immediate operands로 상수를 load하기 위한 메모리 접근을 피할 수 있다.
-
solution : MIPS register 0($zero)는 상수 0을 가지고 있다.(0을 많이 쓰기 때문에)
- 이는 덮어 쓸 수 없다.
- 이것은 또한 유용한 변화를 제공하므로써 지시 사항 구조를 단순화한다.
- Q. add지시어와 $zero를 이용하여 $t0와 $t1 두개의 레지스터 사이의 값을 교환해라
add $t0, $t1, $zero
- Q. add지시어와 $zero를 이용하여 $t0와 $t1 두개의 레지스터 사이의 값을 교환해라
-
예제
f = A[10] - i +4;
A는 1 바이트 배열이며 base address는 $s0에 저장되어 있다.
f와 i는 $s1과 $s2에 각각 저장되어 있다.
MIPS assembly언어 코드로 컴파일된 코드
lb $ t0, 10($ s0)
sub $ t1, $ t0, $ s2
addi $ s1, $ t1, 4
-> instruction 수를 줄여 성능을 늘린다.
MIPS ISA에 대한 요약
- 기본적인 디자인 원칙
- 디자인 원칙 1. 단순성은 규칙성을 좋아한다.
- 모든 MIPS 연산 지시사항은 단일 연산과 3개의 피연산자를 가진다.
- 디자인 원칙 2. 작은 것이 더 빠르다.
- MIPS의 연산 지시사항의 피연산자들은 작은 수의 레지스터들에서 골라져야한다.
- MIPS는 더 복잡한 데이터를 메모리에 보관하고 메모리와 레지스터 사이의 데이터 전송을 지원한다.
- MIPS의 연산 지시사항의 피연산자들은 작은 수의 레지스터들에서 골라져야한다.
- 디자인 원칙 3. 일반적인 case를 더 빠르게
- 작은 상수를 다루기 위해 16비트의 immediate 피연산자를 제공한다. + $zero
저장된 프로그램 개념(ISA에 지시사항/수 binary code 바꾸는 것이 명시되어 있음)
- 데이터와 지시사항은 이진수로 표현되어 있고 메모리에 저장되어 있다.
데이터들 표현 : 숫자들
- 숫자들은 컴퓨터 하드웨어에 1또는 0의 형태로 저장되어 있다.
- 이들은 base 2 숫자들(이진 수)로 여겨진다.
- 이진수의 i번째 숫자d는 이진수로 d x 2^i로 표현된다.(i는 0부터 시작)
- 1011(2) = (1 x 2^3 + 0 x 2^2 + 1 x 2^1 + 1x2^0)(10) = 11(10)
- 이진수들은 words로 저장되어 있다.
- MIPS에서 words는 32비트(4바이트) long 이며 MIPS는 빅 인디언 방식을 가진다.
- 가장 큰 바이트를 가장 처음에 넣는다.(가장 왼쪽에 위치 또는 가장 아래에 위치) - 비트를 오른쪽에서 왼쪽으로 0,1,2,3... 숫자를 매긴다.(또는 위에서 아래로) - 예를 들어 1000 1000 1010 1010 0000 0000 0101 0101(2)일때
데이터들 표현 : unsigned numbers
-
n비트를 이용함으로써 우리는 0 ~ 2^n - 1 의 unsigned 숫자들을 표현할 수 있다.

-
그렇다면 우리는 부호가 있는 숫자들은 어떻게 표현할 것이냐?
데이터들 표현 : signed numbers
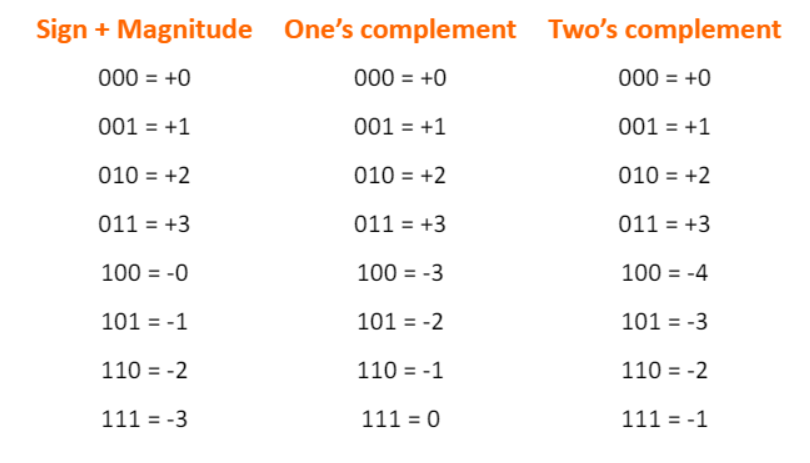
- 부호가 있는 숫자들을 표현하는 많은 방법이 존재한다.
- 우리는 0의 개수와 연산 효율성을 따져봐야 한다.
-
sign + magnitude : MSB가 0일때는 양수/ 1이면 음수, 이후 자리수가 값이 된다.ex) 110 = -(11(2)) = -3
-
One's complement : MSB가 0일때는 양수/ 1이면 음수, 음수라면 모든 수를 반전시킨다. ex) 110 -> 001 -> -1
-
two's complement : MSB가 0일때는 양수/ 1이면 음수, 음수라면 모두 뒤집고 +1 ex) 110 -> 001 -> 010 -> -2
-
우리가 two's complement 방법을 사용한다면, 단순한 연산을 통해 연산 결과를 알 수 있다.(추가적인 연산이 필요없음) 또, 위의 표에서 보듯이 다른 방법과는 다르게 two's complement방식은 0의 개수가 1개이다.

데이터들 표현: two's complement numbers
- n비트를 이용함으로써 우리는 two's complement numbers 로 -2^(n-1) ~ 2^(n-
1) - 1

- 2's complement number에서 양수 / 음수 상호 변환
- 모든 비트를 반전시키고 1을 더하는 것이다.(1->0 or 0->1 이후 +1)

- 다음 표에서 다른 모든것들 이외에 가장 작은 수 -2^(15) 를 변환할 때를 주의해야 한다. -> 2's complement number로 표현할 수 있는 범위는 -2^(n-1) ~ 2^(n-1) - 1 이기 때문에 2^(15)는 표현할 수 없다.
- 부호 확장
- 가끔 우리는 n비트의 숫자를 n비트보다 더 많은 비트를 이용하여 표현해야 할 수도 있다. - 16비트 immediate는 연산을 위해 32비트로 변환되어야 한다. - lb/lh 지시사항은 메모리 공간에서 byte/halfword 를 load하고 32비트 레지스터에 저장한다. - sign bit를 왼쪽으로 반복시킨다.
ex)
addi $30, $t0, 16
해당 코드에서 $t0은 word로 4바이트 크기다. 16은 2바이트 halfword이므로 signed extention이 필요하다.
지시사항 표현
-
데이터와 같이 지시사항 또한 이진수로 인코딩/표현 된다.
-
우리는 인코딩된 지시사들을 machine instructions라고 부른다.(non-encoded 지시사항 : 어셈블리어 , ex) add $t0, $t1, $t2)
-
지시사항을 표현하기 위해 ISA는 instruction 포멧(지시사항의 나열)을 정의한다.
ex) 인코딩된 비트의 연속에서 어떤 부분이 무엇을 위해 이용될것인가? -
문제 : 모든 지시사항을 표현하기 위해서 우리는 많은 instruction format을 필요로 할 것이다 + 다른 포멧을 디코딩하기 위해서 우리는 복잡한 컴퓨터구조를 필요로한다.
디자인 원칙4 : 좋은 디자인은 좋은 compromise를 요구한다.
-
compromise(타협점) : 모든 지시사항을 같은 길이로 일관되게 유지한다.(MIPS 지시사항들은 32비트의 instruction words로 인코딩되어 있다.)
-
이를 바탕으로, MIPS는 포멧을 가능한 유사하게 유지한다.(일정성)
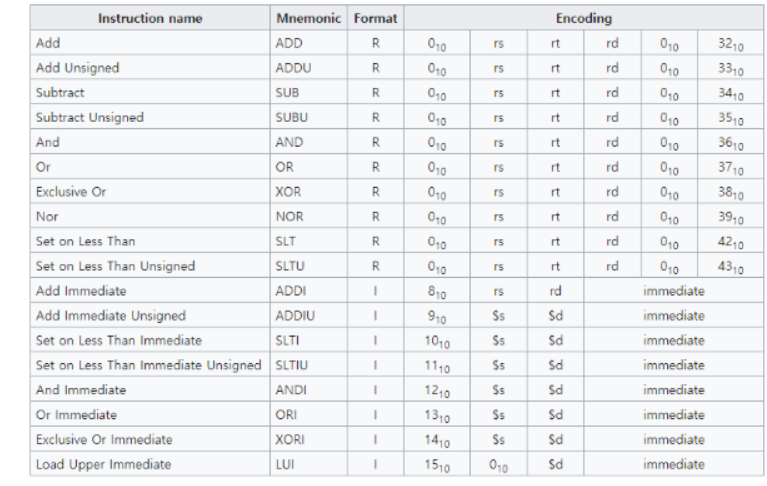
지시사항 표현 : R-format
- Register 피연산자만을 사용하는 지시사항

-
op(opcode) : 기본적인 지시사항의 작동(지시사항이 무엇을 하는지)
-
rs : 첫번째 소스 레지스터 피연산자
-
rt : 두번째 소스 레지스터 피연산자
-
rd : 대상 레지스터 피연산자
-
shamt : shift 양(shift 작업을 위해 이용된다.)
-
funct : 함수 코드(작동의 구체적인 변화)
-
ex) add(op) $t0(rd), $t1(rs), $t2(rt)
-
shift 양(0~31양 만큼 shift가능)
0000 .... 0001
0000 .... 0010 -
Q) MIPS는 얼마나 많은 레지스터를 이용하냐?
-> 32개의 레지스터를 사용한다.
지시사항 표현 : I-format
- Immediate 피연산자를 이용하는 지시사항

-
op : 기본적인 지시사항의 작동(R-formet과 유사하다.)
-
rs : 첫번째 소스 레지스터 피연산자
-
rt : 두번째 소스 레지스터 피연산자
-
상수 또는 주소(memory space를 거치지 않음)
-
Q) immediate operand를 위해 MIPS가 얼마나 많은 바이트를 사용하냐?
-> 32비트 -> 4바이트
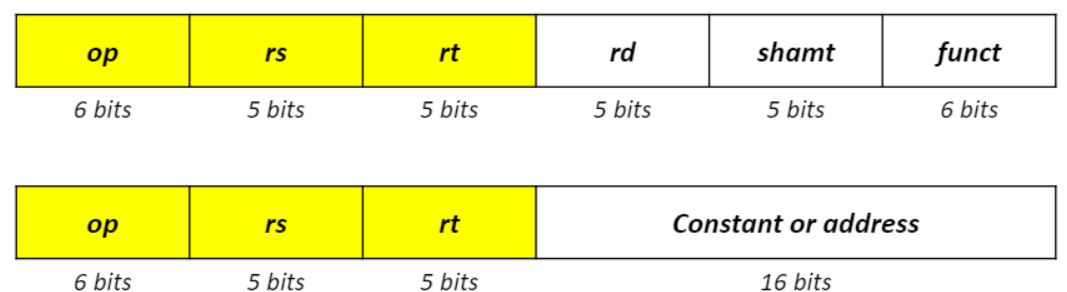
-
위의 디자인 원칙4에서 MIPS는 가능한 유사한 포멧을 지닌다.(R-포멧과 I-포멧은 32비트 instruction word)
지시사항 표현 보기
- R-format의 op코드는 0이다.

요약
- 중요한 디자인 원칙
- 디자인 원칙1 : 단순성은 일관성을 선호한다.
- 모든 MIPS 연산 지시사항은 단일 연산과 3개의 피연산자를 가진다.
- 디자인 원칙2 : 작은 것이 더 빠르다.
- MIPS의 피연산자 지시사항은 작은 수의 레지스터에서 선택되어야 한다. MIPS는 더 복잡한 데이터를 메모리에 넣고 메모리와 레지스터 사이의 데이터 이송을 지원한다.
- 디자인 원칙3 : 일반적인 case를 빠르게 만들어라
- 작은 상수를 다루기 위한 16비트의 immediate 피연산자 + $zero 를 지원한다.
- 디자인 원칙 4 : 좋은 디자인은 좋은 compromise를 요구한다.
- 모든 지시사항을 같은 길이로 유지 + 지시사항의 포멧을 최대한 비슷하게 만들어라(data(숫자들)는 2's complement rules에 의해 이진수로 표현된다.)
- 디자인 원칙1 : 단순성은 일관성을 선호한다.
- 디자인 원칙 1: Clock Period 또는 CPI를 낮춘다.
- 디자인 원칙 2: Clock Period 또는 CPI를 낮춘다.
- 디자인 원칙 3: instruction count를 낮춘다.
- 디자인 원칙 4: Clock Period 또는 CPI를 낮춘다.
