최대 가능도 추정
-
인터넷에서 x를 N개 수집했다.
-
이런 N개의 데이터가 정규분포를 따른다고 가정하고, 정규분포를 추정해보자
-
모수 추정 문제 : 표본 값 x에 대해서는 알고 있지만 모수 θ를 모르는 상황
-
모멘트 방법 말고, 최대 가능도 추정 사용 가능
-
이론적으로 가장 가능성이 높은 모수(parameter)를 찾는 방법
-
모든 추정 중 가장 널리 알려진 방법중 하나
-
확률 분포 X에 대한 확률 함수를 다음과 같이 표현
p(x; θ) -
이때 x는 확률 분포가 가질 수 있는 실수 형태의 값
-
x,θ 모두 스칼라 또는 벡터
-
가지고 있는 데이터x를 토대호 모수 θ를 찾는 문제로 이해
-
즉, 확률 밀도 함수에서 모수를 변수로 간주
-
가능도 함수 : L(θ; x) = p(x; θ)
-
추정하고자 하는 확률 분포에 따라 가능도 함수를 다르게 정의 가능
1)베르누이 확률 분포를 추정하는 경우
-> θ = μ
2) 정규분포를 추정하는 경우
-> θ = (μ, σ^2) -
최대 가능도 추정은 다음과 같은 문제를 해결하는 것이 목표이다.
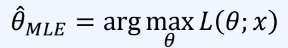
-> 가지고 있는 정보를 토대로, 가능도(likelihood)를 최대로 만드는 parameter를 찾는다.
정규분포 추정 예시
-
정규 분포의 확률 밀도함수는 다음과 같다.
-> 모수 θ를 알고 있으며, 적분했을 때 면적이 항상 1이다.
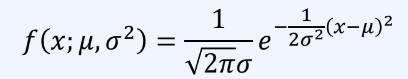
-
가능도 함수는 다음과 같다.(x가 상수)
-> 데이터 x를 알고 있으며 적분했을 때 면적이 1이 아닐 수 있다.
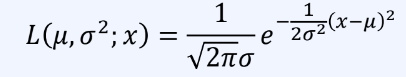
-
분산이 4로 알려져 있고, 값이 5인 데이터를 가지고 있다고 할 때
-
[5,7,9] 중에서 어떤 값이 평균에 가장 적합할까?
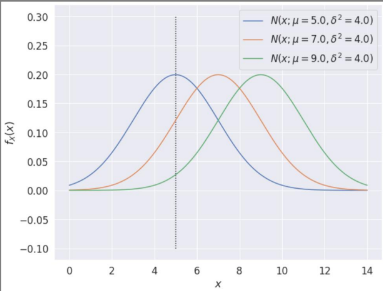
-> 5가 제일 적합
여러개의 데이터가 있는 경우 가능도 측정
-
N개의 데이터 {x1,x2,...,xN}을 가지고 있는 상황을 고려
-
각 표본 데이터는 같은 확률 분포에서 나온 독립적인 값이다.
-
독립적 : x1과 x2는 서로 영향을 주지 않는다.
-따라서 N개의 데이터가 동시에 나올 결합 확률 밀도 함수는
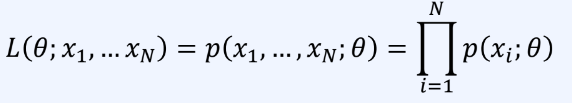
-
4개의 데이터를 얻은 상황을 가정
{-5, 0, 3, 10}
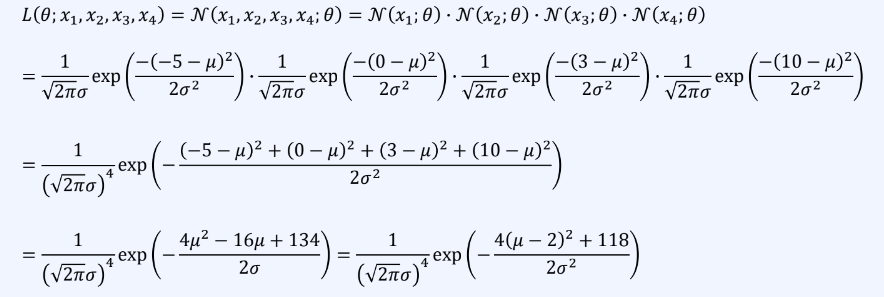
결과 값이 가능도를 나타내는데 여기서 σ값과 상관없이 μ= 2일때 항상 최대값을 가진다.
-
정규분포의 최대 가능도 함수를 다음과 같이 정리 할 수 있다.
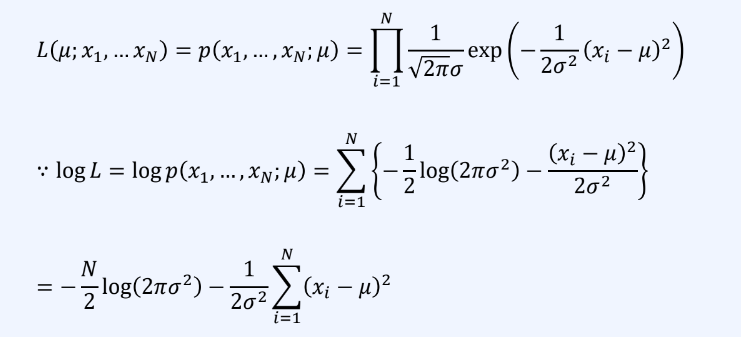
-
결과값을 μ와 σ^2으로 미분한 값이 0일 때 가능도 값이 최대가 된다.
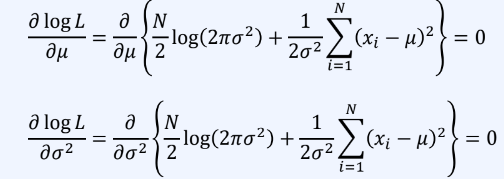
-
식을 전개하면 해는 다음과 같다.
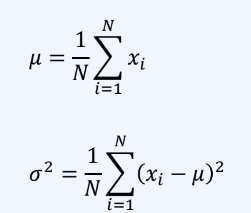
-> 정규분포의 평균은 표본 평균과 같고 분산은 표본 분산과 같다.
