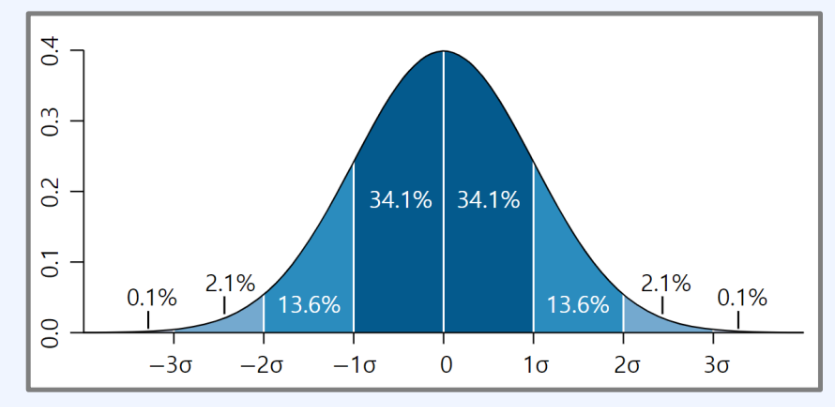
표준 정규 분포
- 평균이 0이고 분산이 1인 표준화된 정규분포이다.
- 확률 변수 X가 X~N(μ, σ)을 따를 때 다음 공식으로 표준화를 할 수 있다.
Z =(X − μ)/σ - 확률 변수 Z가 0이고 분산이 1인 정규분포를 따를 때
- Z는 표준 정규분포를 따른다고 말한다. Z~N(0,1)
- Z의 확률 밀도함수는 다음과 같다
f(z) =1/(root(2π))e^((-1/2)Z^2) - 표준 정규 분포의 경우 σ의 값이 1이므로 p(Z<=1)을 약 84.1%로 볼 수 있음
표준 정규 분포의 누적 분포 함수
- 아래 그래프에서 정규 분포의 누적 분포 함수 확인
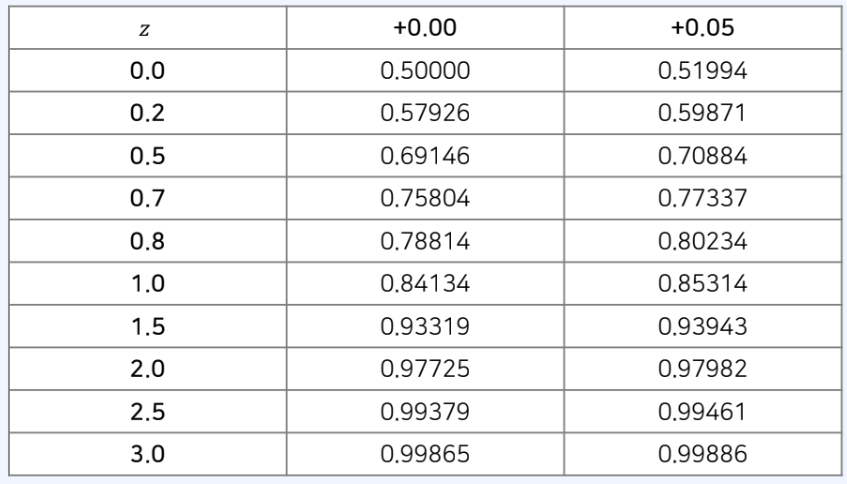
표준 정규 분포 표
-
정규 분포의 누적 분포 함수 값에 대한 표이다.
-
표준 정규 분포에서 P(0 <= z <= 0.75)는 얼마일까?
P(0 <= z <= 0.75) = P(z <= 0.75) - P(z <= 0) = 0.77337 - 0.5 = 0.27337
표준 정규 분포 예시
-
표준 정규 분포에서 z가 0.8이하일 확률은?
P(z <= 0.8) = 0.78814 -
IQ 판단시 평균을 100으로 설정한다.
-
한국 표준 편차를 σ를 24로 설정
-
IQ가 148이라면 상위 몇 %에 해당하냐
확률 변수 X가 X ~ N(100, 24^2)일 때 X가 148 이상일 확률은
P(X >= 148) = P(Z >= (148-100)/24) = P(Z >= 2)
P(Z >= 2) = 1 - P(Z <= 2) = 1-0.97725 = 0.02275
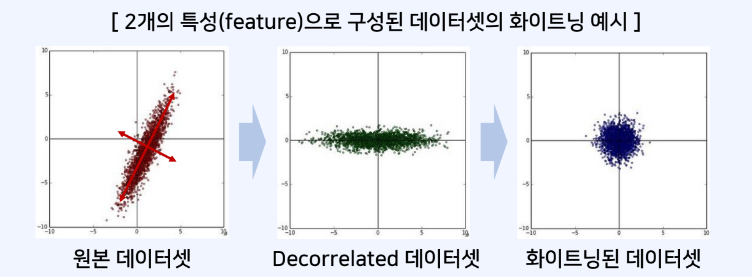
딥러닝 분야의 입력 정규화(input normalization)
-
입력 데이터를 정규화 하여 학습 속도를 개선할 수 있다.
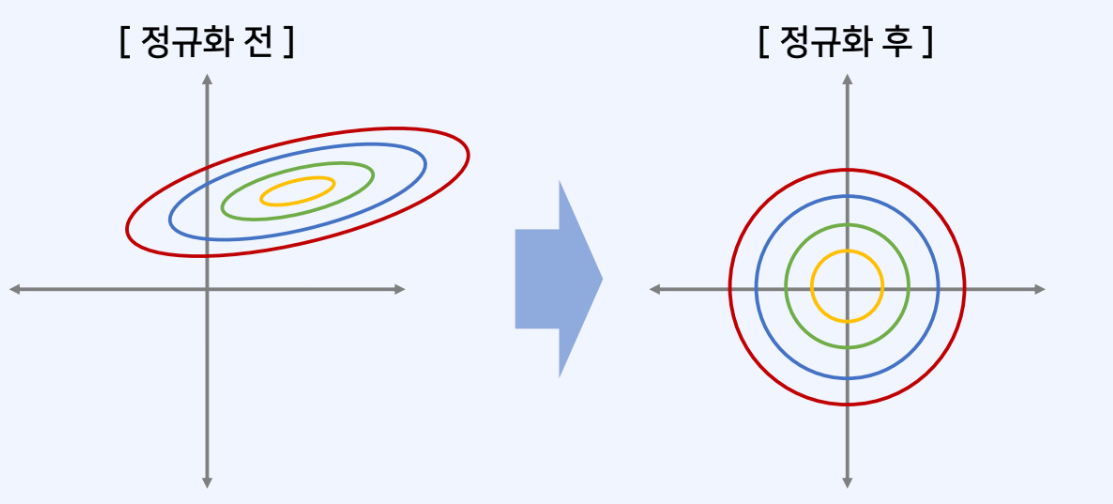
-
입력 데이터가 N(0,1) 분포를 따르도록 표준화 하는 예제
import numpy as np
import matplotlib.pyplot as plt
x1 = np.asarray([33,72,40,104,52,56,89,24,52,73])
x2 = np.asarray([9,8,7,10,5,8,7,9,8,7])
normalized_x1 = (x1-np.mean(x1)) / np.std(x1)
normalized_x2 = (x2-np.mean(x2)) / np.std(x2)
plt.axvline(x=0, color='gray')
plt.axhline(y=0, color='gray')
plt.scatter(normalized_x1, normalized_x2, color='black')
plt.show()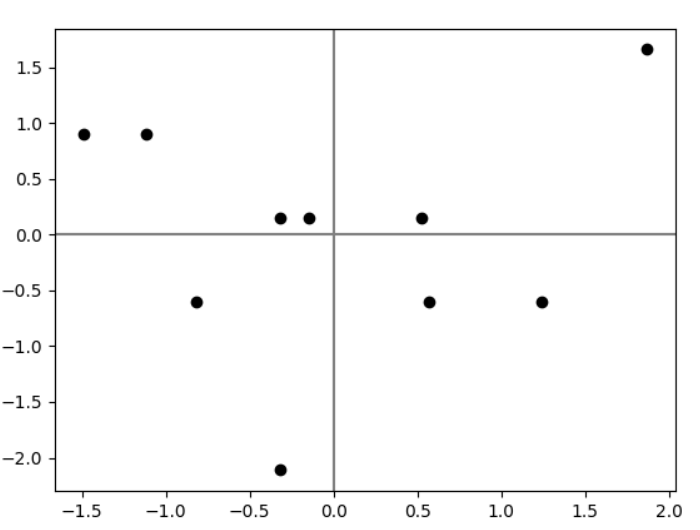
- 입력 정규화를 이용해 각 차원의 데이터가 동일한 범위 내의 값을 갖도록 만들 수 있다.
- 모든 특성에 대하여 각각 평균만큼 빼고 특정한 범위의 값을 갖도록 조절할 수 있다.
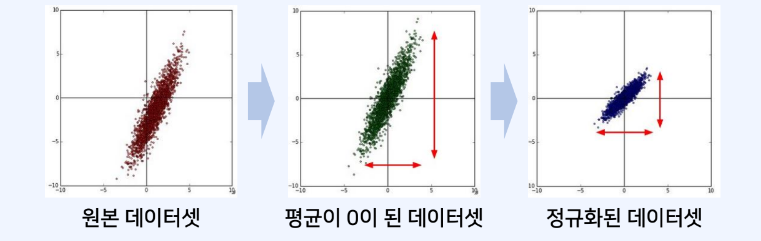
- 화이트닝은 평균이 0이며 공분산이 단위행렬인 정규분포 형태의 데이터로 변환한다.
- 일반적으로 딥러닝 분야는 PCA나 화이트닝보단 정규화가 더 많이 사용된다.