2022년 발표된 ‘Jury Learning: Integrating Dissenting Voices into Machine Learning Models’ 논문을 읽고 정리한 글입니다.
이전글에서도 언급했듯이 명확하게 구분되지 않는 문제를 구분하는 일이 딥러닝 연구할 때 골치 아픈 지점 중에 하나인 것 같습니다.
예를들어, Annotator A가 ‘참’이라고 생각했지만, B나 C는 A와는 다른 판단 기준으로 ‘거짓’으로 판단하는 경우가 있습니다. 그때마다 연구자는 고민하게 됩니다. 가이드라인을 더 상세하게 정해서 통일된 의견이 나올 수 있도록 할지, ABC 중 1/3이 참이라고 했으니 ‘1/3 참’ 데이터로 넘길지 등이죠. 전자는 가이드라인이 너무 길어져 annotator를 힘들게 할 수 있을 것이고, 후자는 자칫 신뢰할 수 없는 결과가 나올 수도 있을 겁니다.

이 논문은 그러한 문제를 해결하고자 합니다. 후자의 방법을 다수결보다는 고도화된 과학적 접근법으로 풀어냈습니다. 우선 annotator 개개인의 의사가 다를 수 있음을 존중합니다. 그래서 일단 annotator 각각마다 별개의 분류모델로 따로따로 학습합니다. 그리고나서 각각의 모델의 결과를 통합하여 결과를 제공하는데, 연구자가 임의로 annotator의 사회배경, 성격, 인종 등의 구성을 정해서 이런 식으로 통계적인 결과를 제공하는 겁니다. “백인, 히스패닉, AAPI, 흑인으로 균등하게 구성된 남성 6명, 여성 6명으로 구성된 이 집단의 경우 이들 중 58%가 거짓으로 동의할 것으로 예상됩니다.”라는 식으로요. 훨씬 객관적으로 보이지 않나요?
이렇게 개략적인 논문의 컨셉을 소개해드렸는데, 더 자세하게 Jury Learning이란 것이 무엇인지 살펴봅시다.
[Term]
- jury: 배심원
- online comment toxicity : 댓글 유해도
- MAE : 평균 절대 오차
- ROC AUC: ROC curve에서의 AUC 값 (Area Under Curve). 1에 가까울 수록 분류 잘됨
다수결 결정에 따른 기존 딥러닝 알고리즘의 문제점
이 논문은 ‘Jury Learning’이라는 새로운 학습법을 제시합니다. 이 글에서는 기존 다수결 기반 딥러닝에서 간과할 수 있는 지점을 지적하고 있습니다.
- 소수의 의견 무시할 수 있음
- 논쟁할 여지가 많은 task에서 아쉬운 성능
Jury Learning
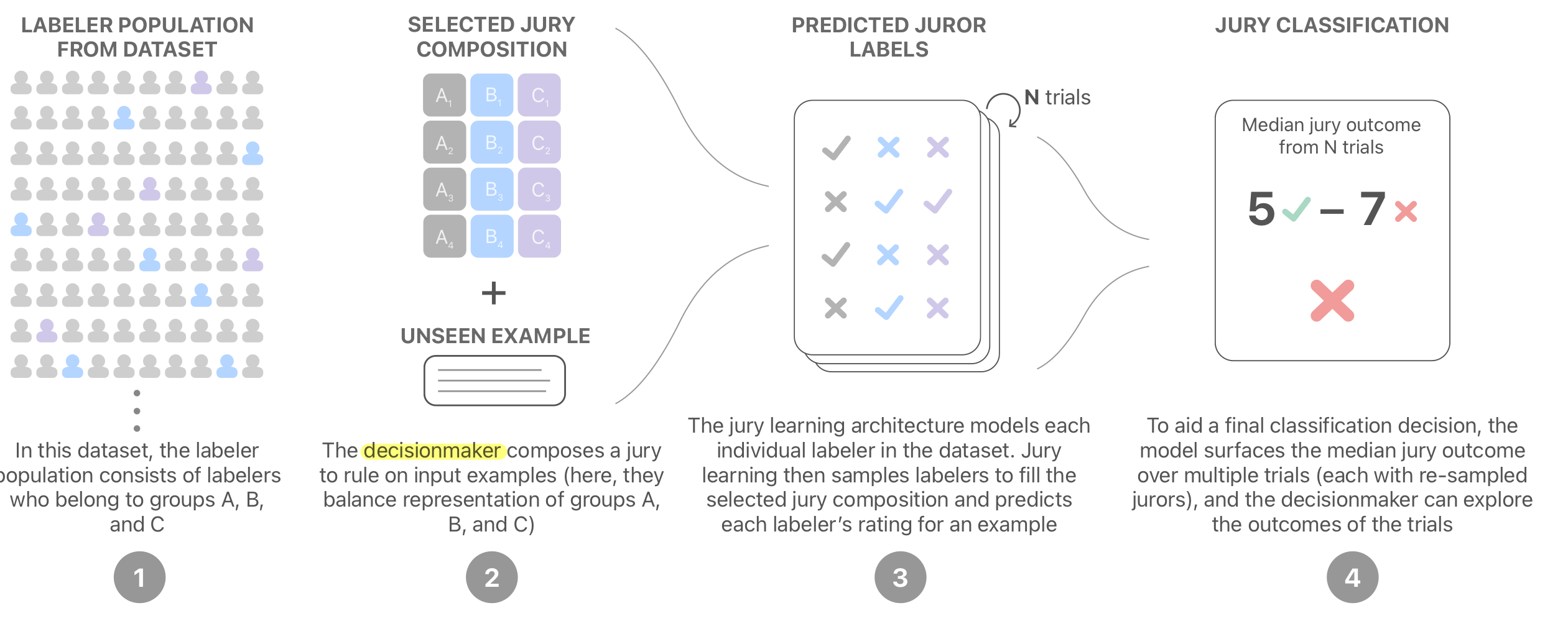
Jury Learning은 직역하면 ‘배심원 학습법’입니다. 미국 법정에서 12명의 배심원단을 무작위로 선정하는 것처럼, 참/거짓을 구분하는 배심원단을 연구자 입맛에 맞게 구성해서 결과를 제공하는 방식입니다. 위의 그림으로 Jury learning의 파이프라인을 설명할 수 있습니다.
과정 1)
임의의 기준(인종, 성별 등)으로 나눠진 각 A,B,C 집단으로 구성된 전체 어노테이터 집단이 있다고 합니다. 전통적인 딥러닝 방식이라면 상대적으로 B, C 집단의 의견이 무시될텐데요.
과정 2)
하지만 연구자는 A, B, C 집단의 비율을 정의하여 층화추출 방법으로 배심원단을 뽑습니다. (예시그림에서는 A 집단에서 4명, B 집단에서 4명, C 집단에서 4명으로 균등하게 12명의 배심원단을 뽑았습니다.)
과정 3)
그 다음 각각 N명의 배심원들마다 학습하여 총 N개의 모델을 학습시키고 이 모델의 결과로 이들의 예상 outcome을 추측합니다.
과정 4)
최종 결과를 낼 때는 2~3의 과정을 반복하여 집단의 뽑을 때마나 하나의 평균/과반수 jury outcome(각 배심원들의 예상 outcome을 평균내거나 과반수의 결과)을 도출하는 식으로 수 개의 jury outcome을 도출합니다. 그 다음 jury outcome들의 중앙값으로 예측 결과를 제공합니다.
Jury Learning outcome의 강점은 다음과 같습니다.
- 배심원들간 평균 outcome의 중앙값으로 결과가 나오기 때문에 소수의 배심원이 틀리는 경우도 커버할 수 있음.
- 불확실성에 대한 직접적인 측정값을 제공함. 예를들어 배심원단 중 85%가 거짓으로 판단하고 15%가 참으로 판단했다는 식으로 표현가능.
- 회귀 문제인 경우, 히스토그램 등으로 각 구간별 예측값의 분포도도 그릴 수 있음.

Jury Learning 활용 시나리오
만약에 배심원 구성이 변할 때 결과가 달라지는 것을 관찰했다면, 이런식으로 구성을 조정하여 적절한 배심원 구성을 직접 설정할 수도 있습니다. 만약 플랫폼 서비스에 여성회원이 더 많다면 여성 배심원을 늘리는 식으로 세부조정을 할 수 있습니다.
느낀점
- 저는 이런 의견 불일치가 있었을 때 하나의 가이드라인을 잘 세우는 쪽으로 문제를 해결해왔는데, 각자의 의견을 존중하는 이러한 접근방식이 있다는 것이 신선했습니다.
- 무조건 다수결이 집단을 대표하는 것이라고 여기고 있었지만, jury learning으로 소수의 의견도 포함하는 윤리적인 의사결정을 할 수 있겠다는 생각을 했습니다.
- 마치면서 데이터 라벨링에 대해 의견 불일치가 있는 경우를 극복한 또 하나의 프로젝트에 관한 논문인 [General-purpose tagging of freesound audio with audioset labels: task description, dataset, and baseline]도 추후 자세히 읽어봐야겠습니다.
