📌 광학 문자 인식(OCR)이란 무엇인가?
광학 문자 인식(OCR)은 텍스트 이미지를 기계가 읽을 수 있는 텍스트 포맷으로 변환하는 과정입니다. 예를 들어 양식 또는 영수증을 스캔하는 경우 컴퓨터는 스캔본을 이미지 파일로 저장합니다. 이미지 파일에서는 텍스트 편집기를 사용하여 단어를 편집, 검색하거나 단어 수를 계산할 수 없습니다. 그러나 OCR을 사용하면 이미지를 텍스트 문서로 변환하여 내용을 텍스트 데이터로 저장할 수 있습니다.
이번에는 파이썬을 통해 OCR모델을 만들어 아래와 같은 이미지에서 숫자를 인식해 보도록 하겠습니다.
Python TensorFlow를 통해 "0322"라는 결과값 얻기

📌 맥북(Mac M1 Pro)에서 TensorFlow 환경설정
맥북에서 TensorFlow를 돌리려면 환경설정이 복잡합니다.
anaconda환경에서 시도했지만 잘안되서 miniforge를 다운받아서 환경을 만들어주었습니다.
1. Miniforge 설치
아래의 링크에서 miniforge를 다운해줍니다
https://developer.apple.com/metal/tensorflow-plugin/
실행권한을 바꿔주고 miniforge를 설치해 줍니다.
chmod +x ~/Downloads/Miniforge3-MacOSX-arm64.sh
sh ~/Downloads/Miniforge3-MacOSX-arm64.sh
source ~/miniforge3/bin/activate
2. 가상환경 만들기
conda create --name py38 python=3.8
conda activate py38
3. 맥북 텐서플로우 설치
이 부분에서 버전을 잘못하여 오류가 나는 경우가 많습니다.
공식문서에 들어가보면 버전을 확인할 수 있습니다.
https://developer.apple.com/metal/tensorflow-plugin/
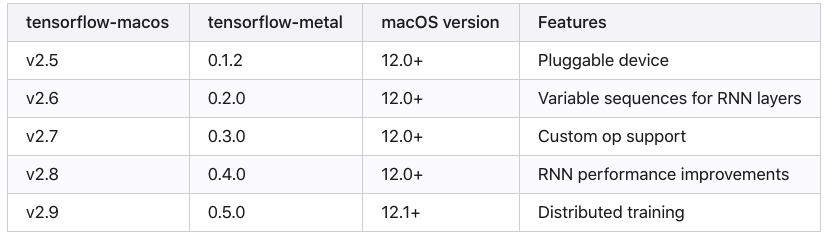
이번에는 "CaptchaCracker"를 이용하여 학습모델을 만들기 때문에 요구하는 버전에 맞춰줍니다.
conda install -c apple tensorflow-deps==2.5.0
pip install tensorflow-macos==2.5.0
pip install tensorflow-metal==0.1.2
https://github.com/WooilJeong/CaptchaCracker 에서 요구하는 버전은
텐서플로우 2.5.0 버전입니다.
마지막 CaptchCracker을 설치해 줍니다.
pip install CaptchaCracker --upgrade
깃허브에 있는 예제코드를 돌리면
import glob
import CaptchaCracker as cc
train_img_path_list = glob.glob("./image/*.png")
img_width = 200
img_height = 50
CM = cc.CreateModel(train_img_path_list, img_width, img_height)
model = CM.train_model(epochs=100)
model.save_weights("weights.h5")weights.h5 모델이 만들어지고, 이를 test.png에 적용을 해서 값을 가져오면 답이 나오게 됩니다.
import CaptchaCracker as cc
# 타겟 이미지 크기
img_width = 200
img_height = 50
# 타겟 이미지 라벨 길이
max_length = 4
# 타겟 이미지 라벨 구성요소
characters = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9'}
# 모델 가중치 파일 경로
weights_path = "./weights.h5"
# 모델 적용 인스턴스
AM = cc.ApplyModel(weights_path, img_width, img_height, max_length, characters)
# 타겟 이미지 경로
target_img_path = "./test.png"
# 예측값
pred = AM.predict(target_img_path)
print(pred)이미지의 수를 100개 정도 했었는데 정확도가 그렇게 잘나오지가 않았습니다...
학습시킬 데이터 수를 늘리면 정확도가 상승하겠지만 약 1000개 정도의 이미지를 다운하고 라벨링 하기에는 너무 오래걸릴 것 같아 다른방법을 찾았습니다.
그래서 찾은 결론은 Python라이브러리 중
Opencv와 pytesseract를 이용하여 정확도 높은 결과를 얻을 수 있었습니다!!
아래는 예시 코드입니다.
인자로 이미지(이미지 주소)를 넣으면 result에 값이 나오도록한 코드입니다.
여기에서 이미지 전처리까지 적용하여 정확도를 더욱 높였습니다def get_macro_protection_number(img): image_grey = cv2.imread(img, cv2.IMREAD_GRAYSCALE) max_output_value = 255 neighborhood_size = 99 subtract_from_mean = 10 image_binarized = cv2.adaptiveThreshold(image_grey, max_output_value, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, neighborhood_size, subtract_from_mean) result = pytesseract.image_to_string(image_binarized, config='--psm 6') print("분석결과 :",result) # plt.imshow(image_binarized, cmap='gray') # plt.show() return result
