
📌 detect.py을 이용해 모델 결과 확인하기
python3 detect.py --source ../hello.jpg --weights ../model/best_model.pt --save-txt
detect.py에서 실행할 때 옵션을 --save-txt 등 자유롭게 옵션을 줄 수 있다.
또한 detect.py의 코드를 수정하면 다양한 옵션을 줄 수 있다.
그렇다면 result = model(image)를 실행한 결과에 대한 옵션은 어떻게 설정할까?
바로 모델을 load후에 해당 모델에 바로 적용할 수 있다!
# 모델 로딩
model = torch.hub.load('./yolov5', 'custom', path='./model/best_model.pt', source='local')
model.max_det = 4 # 객체 탐지 수
model.conf = 0.01 # 신뢰도 값
model.multi_label = True # 라벨링이 여러개가 가능하도록 할지
model.iou = 0.45 # 0.4 ~ 0.5 값
result = model(train_img, size = img_size) #이미지와 size를 넣어 결과를 얻어낸다
result.print() # 모델 적용 후 결과 출력
result.save(save_dir=output_dir,exist_ok=True) # 결과사진을 저장해당내용은 Yolov5 개발자의 질의응답에서 찾을 수 있었다 😊
https://github.com/ultralytics/yolov5/issues/36
그럼 판별한 결과값을 이미지가 아닌 Text로 저장할 수 없을까??
이 또한 위의 링크에서 찾을 수 있었다!
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Image
im = 'https://ultralytics.com/images/zidane.jpg'
# Inference
results = model(im)
results.pandas().xyxy[0]
# xmin ymin xmax ymax confidence class name
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie여기서 pandas( ).xyxy[0]을 까보면 안의 결과값을 얻어낼 수 있다!
내가 직접 파싱한 코드를 보여주면 아래와 같다.
ouput = result.pandas().xyxy[0] # 결과 text데이터 crop_result =[] for idx in ouput.index: name = match_name(ouput.loc[idx, 'name']) confidence = round(ouput.loc[idx, 'confidence'], 2) crop_result.append({"disease" : name, "percentage" : confidence})이 코드를 실행하게 되면 crop_result안에 확률, 병해명이 들어가는걸 확인할 수 있었다.
또한 해당 병해가 발견된 사진의 좌표들도 있지만 필요가 없어 제외시켰다.
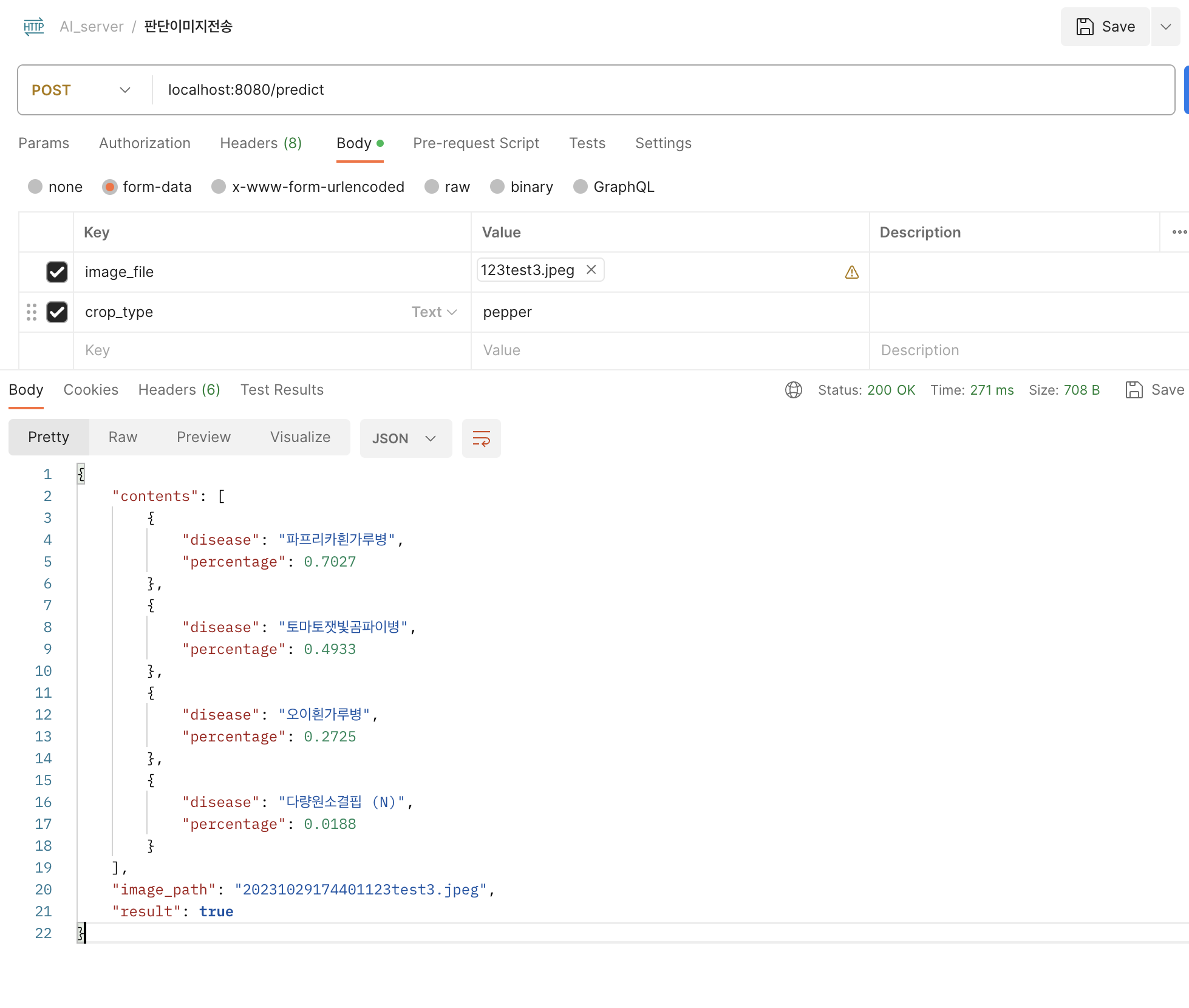
📌 결과 사진

안녕하세요