REPEATABLE READ란?
Repeatable Read는 트랜잭션 내 읽기 일관성을 보장하는 Database의 Isolation Level이다.
예를 들어서 Transaction에서 최초 User 테이블의 name 컬럼 데이터를 읽었다면 이는 가장 최근에 커밋된 언두로그 또는 커밋된 메인 데이터의 데이터를 읽고 있는 것이며, 해당 Transaction이 끝날 때까지 이 Trasanction은 그 데이터를 기반으로 동작한다.
즉, 1번 트랜잭션이 User id 1번을 "홍길동"으로 읽었다고 치자. 그러면 그 데이터는 해당 트랜잭션이 끝날 때까지 다른 트랜잭션의 변경에 관계 없이 계속 "홍길동"인 것이다. (1번 트랜잭션에서 변경한 경우는 제외)
보통 자주 쓰이는 데이터 베이스를 기준으로
- Oracle : Read Committed
- Postgres : Read Committed
- MySQL : Repeatable Read
의 Isolation Level을 기본으로 갖는다.
Transaction의 Isolation 적용 타이밍
자 위의 설명을 토대로 아래 시나리오를 생각해보자.
현재 user_test의 id = 1은 "홍길동"인 상황.
- 1번 트랜잭션 시작
- 2번 트랜잭션 시작
- 2번 트랜잭션에서
update user_test set name = '강길동' where id = 1;로 name 변경 후 커밋 - 1번 트랜잭션에서
select user_test.name from user_test where id = 1;
이렇게 동작했을 때 어떤 데이터가 나올까?
나는 당연히 홍길동이 나올줄 알았다.
- 1번 트랜잭션이 시작될 당시의 "홍길동"으로 커밋된 데이터를 가지고 있기 때문에 2번 트랜잭션과 관련없이 "홍길동"이 출력될줄 암
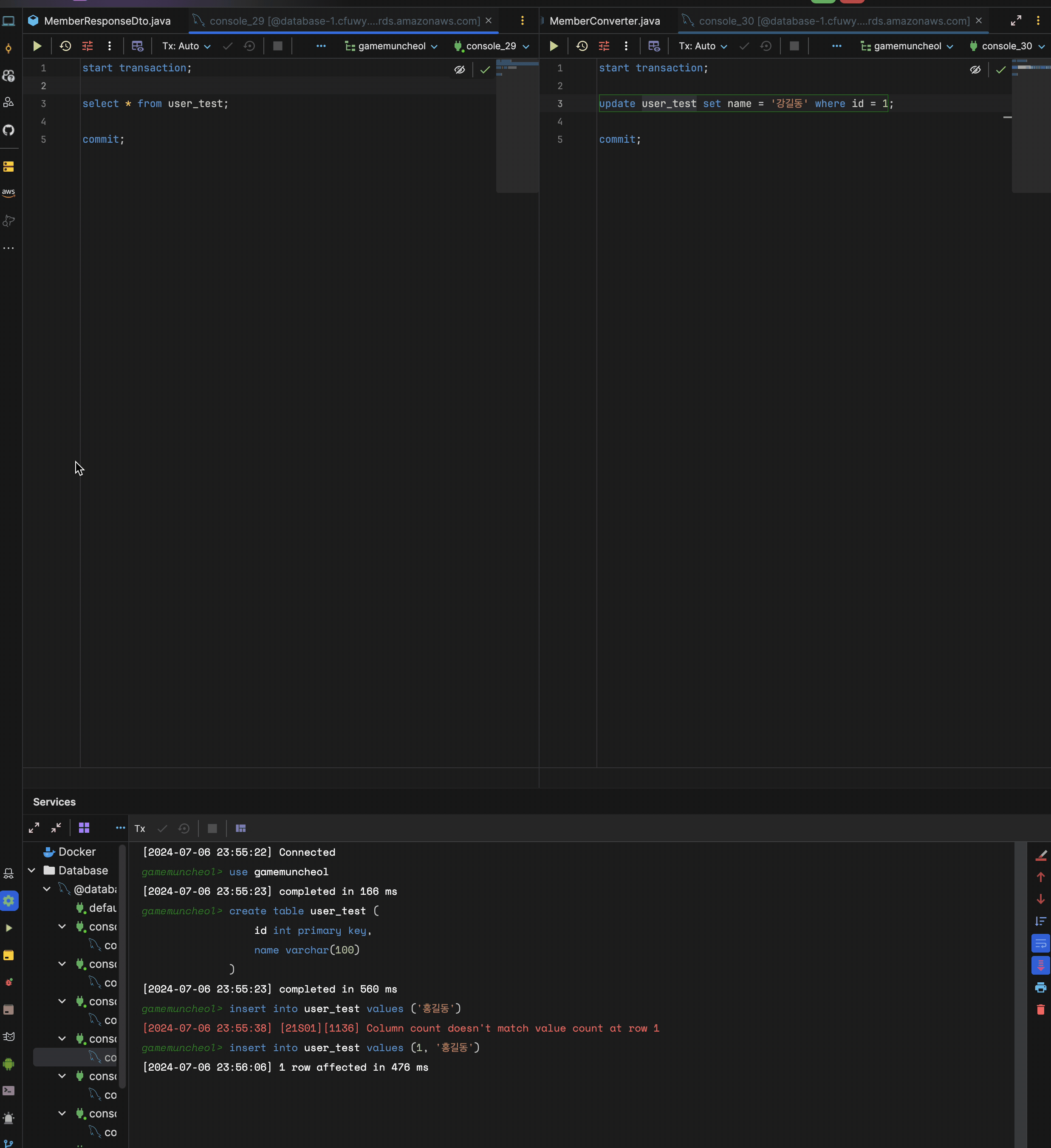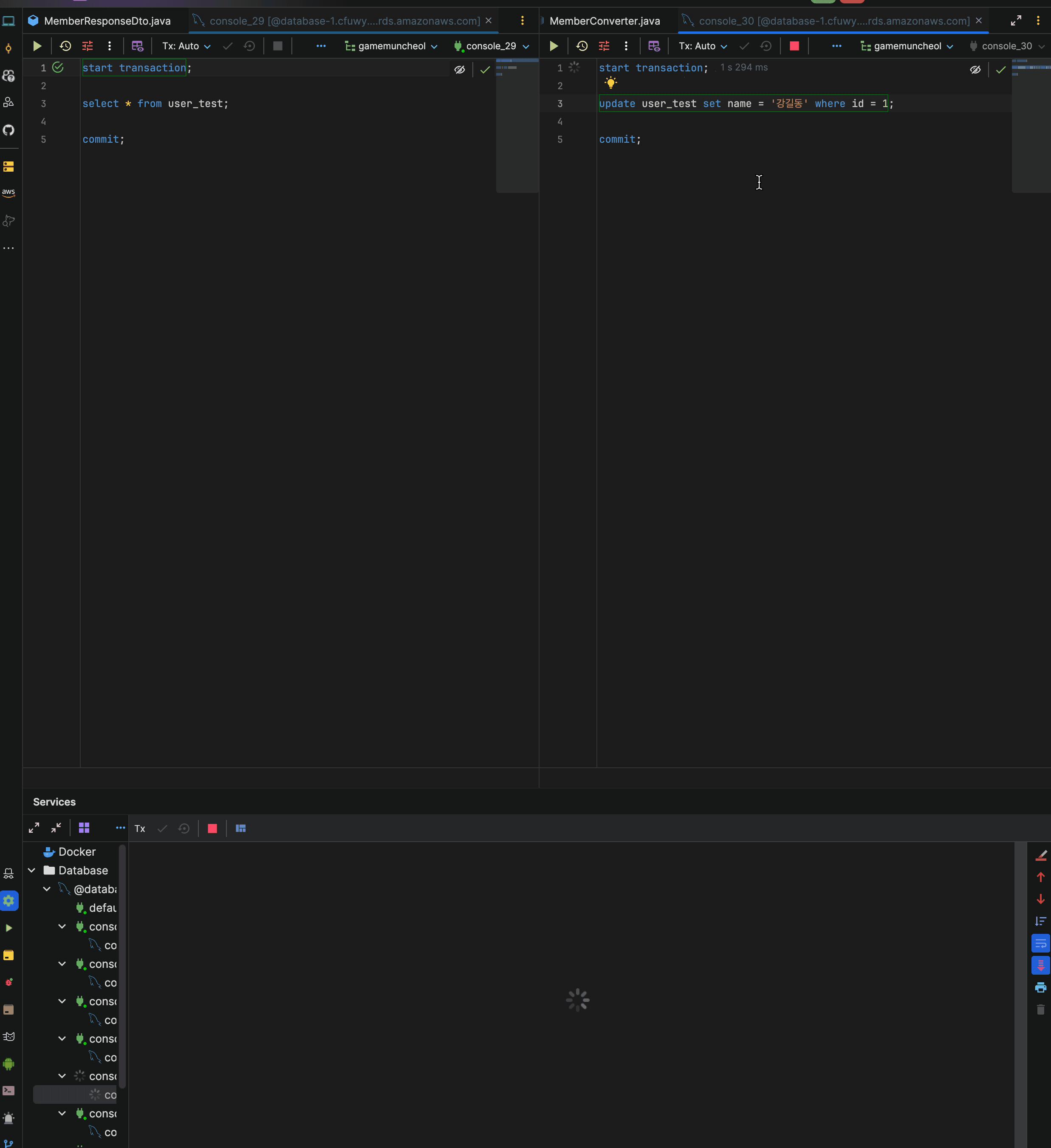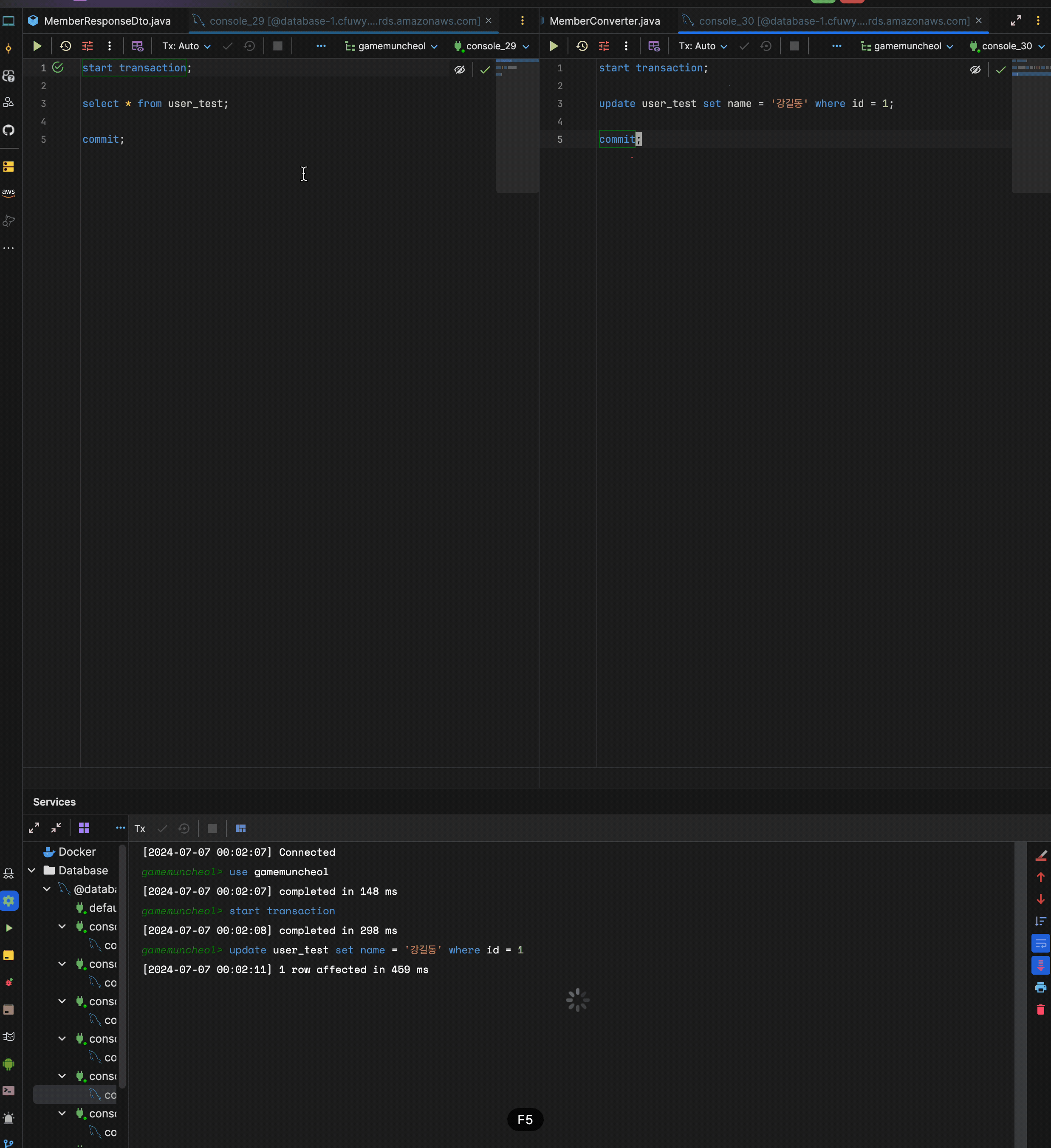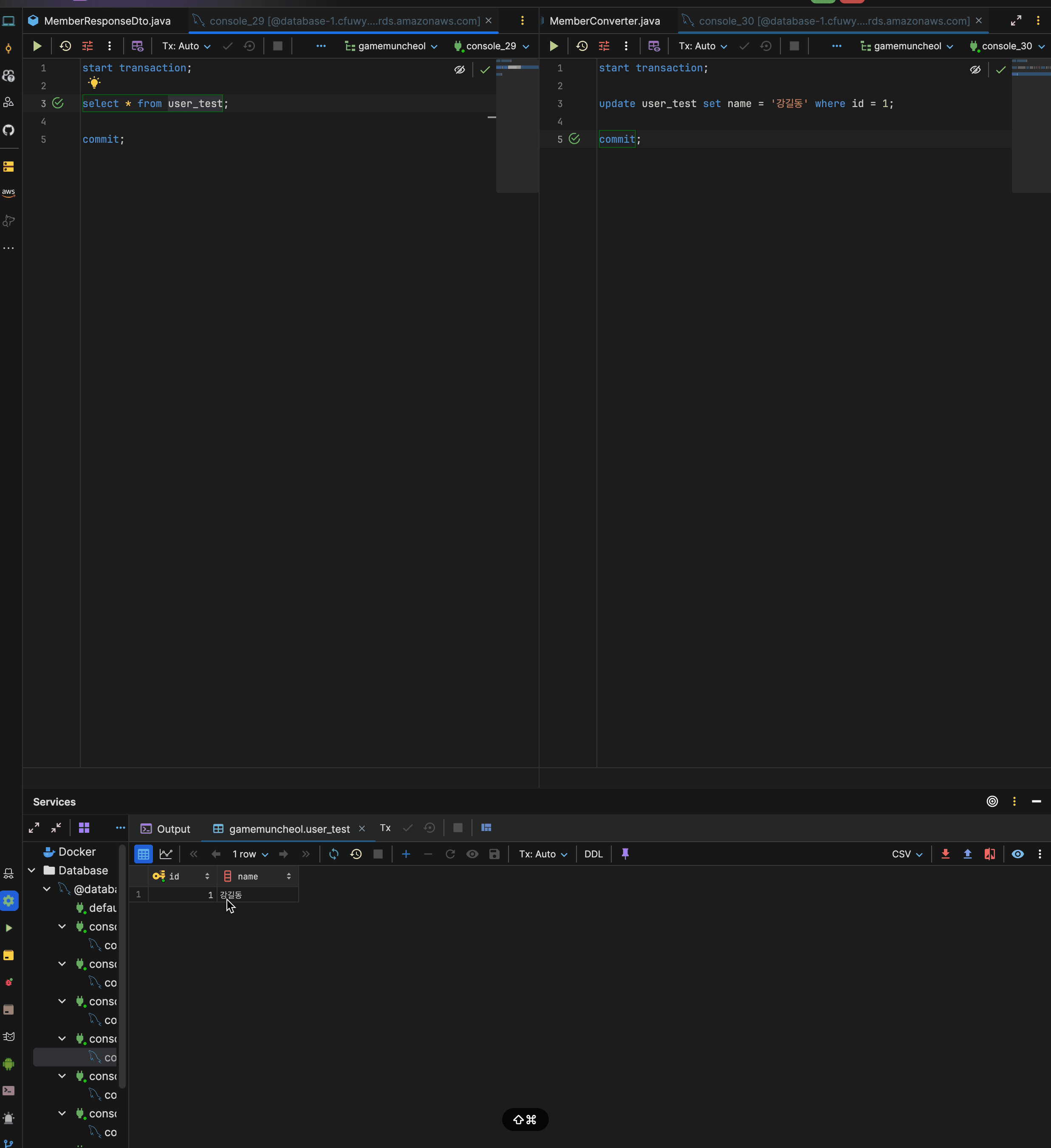
하지만 실제로 해보면 데이터는 강길동이 나온다.
왜 그럴까?
MySQL 공식 문서에 보면 이 이유가 나온다.
결론적으로 얘기를 하자면 일관적 읽기(Consistent Read)는 첫 번째 읽기부터 적용된다고 써져있다.
- 다른 트랜잭션에 의해 수행된 변경사항과 관계 없이 특정 시점을 기준으로 쿼리 결과를 표시하는 읽기 작업
- 쿼리된 데이터가 다른 트랜잭션에 의해 변경된 경우 원래 데이터는 Undo Log의 내용을 기반으로 재구성
- Repeatable Read 격리 수준을 사용하면 스냅샷은 첫 번째 읽기 작업이 수행된 시간을 기준으로 함
consistent read
A read operation that uses snapshot information to present query results based on a point in time, regardless of changes performed by other transactions running at the same time. If queried data has been changed by another transaction, the original data is reconstructed based on the contents of the undo log. This technique avoids some of the locking issues that can reduce concurrency by forcing transactions to wait for other transactions to finish.With REPEATABLE READ isolation level, the snapshot is based on the time when the first read operation is performed. With READ COMMITTED isolation level, the snapshot is reset to the time of each consistent read operation.
Consistent read is the default mode in which InnoDB processes SELECT statements in READ COMMITTED and REPEATABLE READ isolation levels. Because a consistent read does not set any locks on the tables it accesses, other sessions are free to modify those tables while a consistent read is being performed on the table.
For technical details about the applicable isolation levels, see Section 17.7.2.3, “Consistent Nonlocking Reads”.
See Also concurrency, isolation level, locking, READ COMMITTED, REPEATABLE READ, snapshot, transaction, undo log.
Database Lock과 Repeatable Read
이전에 썻던 Post에서 동시에 시작된 트랜잭션에서 Lock이 끝나고 최신 데이터가 들어오는 경우가 있었다.
문제 코드는 아래와 같았는데, commentConverter.requestToEntity에서 사실 처음으로 select문을 하기 때문에 Transaction 1, 2가 동시에 시작된다면 이 때를 기준으로 commentCount를 둘 다 0으로 들고 있고 이후 fidnByIdForUpdate에서 락 이후 데이터를 받았을 때 Repeatable Read이기 때문에 트랜잭션 2도 결국 0에서 시작할줄 알았다.
하지만 결과는 두 트랜잭션이 동시에 수행이되면 commentCount는 2가 된다.
@Transactional
public Comment save(CommentSaveDto request, Member member) {
validatePostNotReplied(request);
Comment comment = commentConverter.requestToEntity(member, request);
em.clear();
Post post = postRepository.findByIdForUpdate(request.postId())
.orElseThrow(() -> new NotFoundException(PostStatus.POST_NOT_FOUND));
log.info("[CUSTOM LOG] PESSIMISTIC_WRITE 락 획득: commentCount = {}", post.getCommentCount());
long count = post.getCommentCount();
count++;
post.setCommentCount(count);
postRepository.save(post);
log.info("[CUSTOM LOG] post 저장 : commentCount = {}", post.getCommentCount());
return commentRepository.save(comment);
}왜 그럴까?
이 이유를 또한 MySQL 공식문서에서 다음과 같은 문장이 나온다.
A SELECT ... FOR UPDATE reads the latest available data, setting exclusive locks on each row it reads. Thus, it sets the same locks a searched SQL UPDATE would set on the rows.
FOR UPDATE 옵션을 써서 Exclusive Lock을 걸었을 경우(Java의 경우 @Lock(LockModeType.PESSIMISTIC_WRITE)에 해당) Isolation Level의 동작과 관련 없이 가장 최신의 데이터를 가져온다.
락 사용 안하는 경우 실험
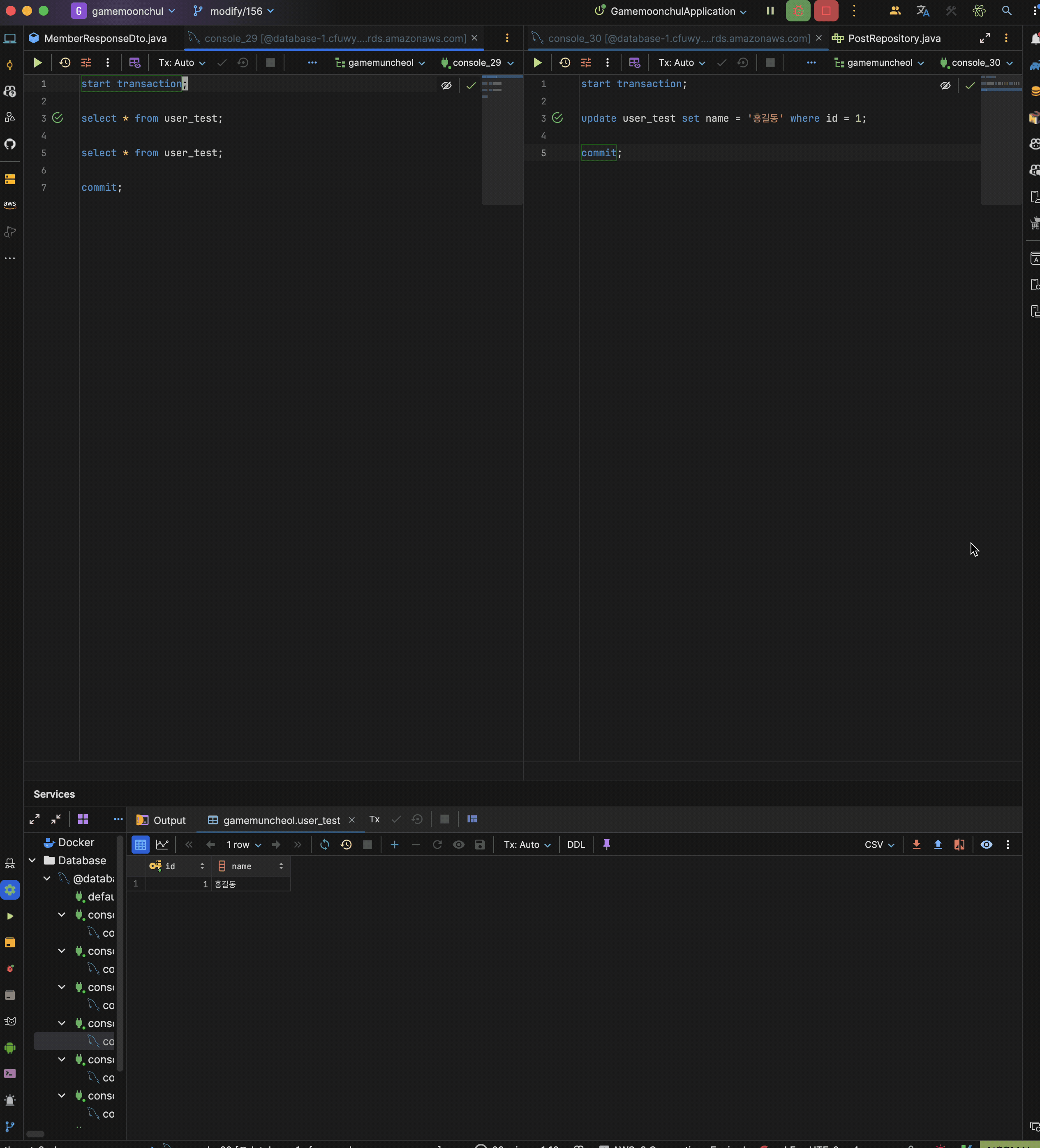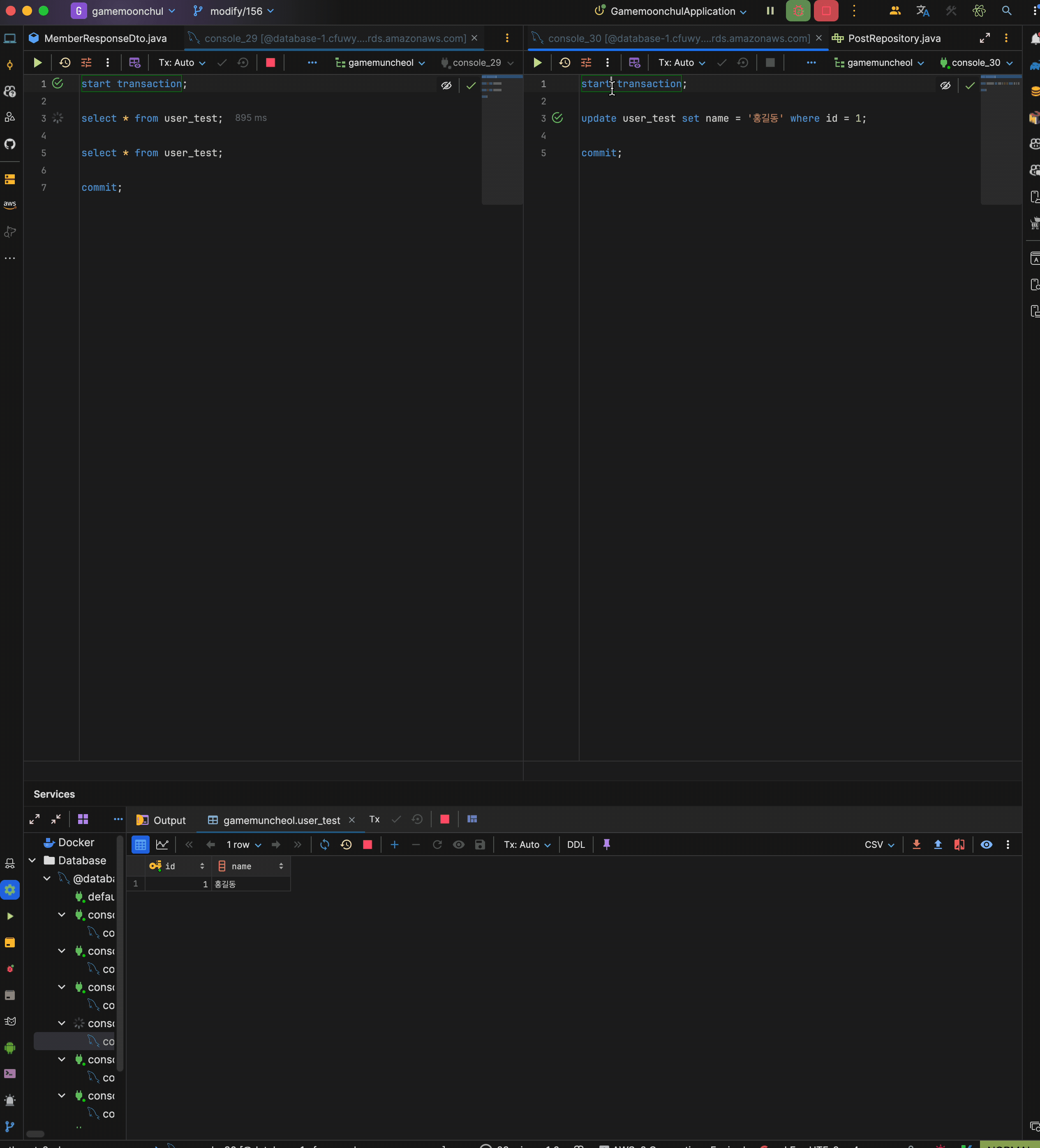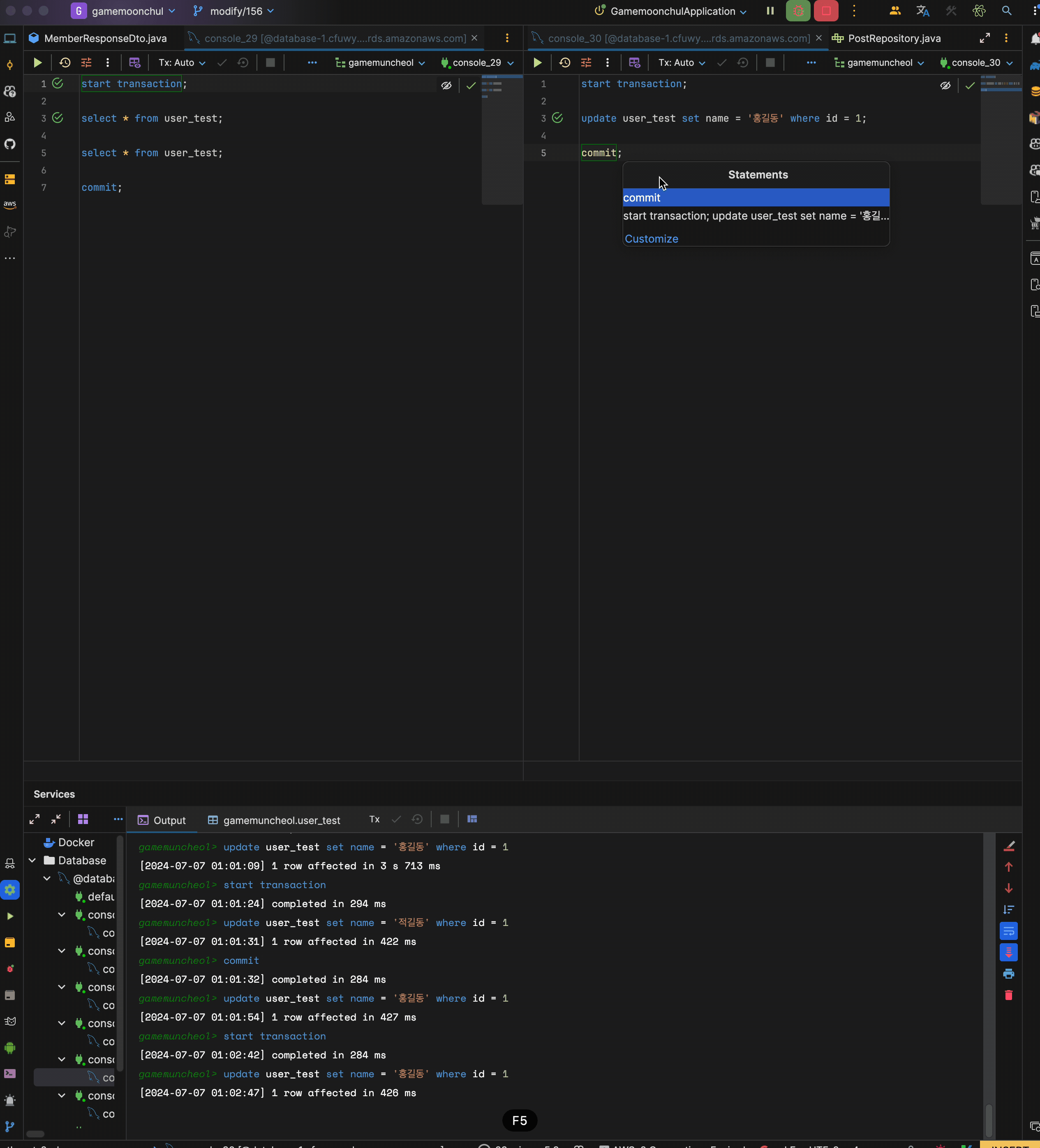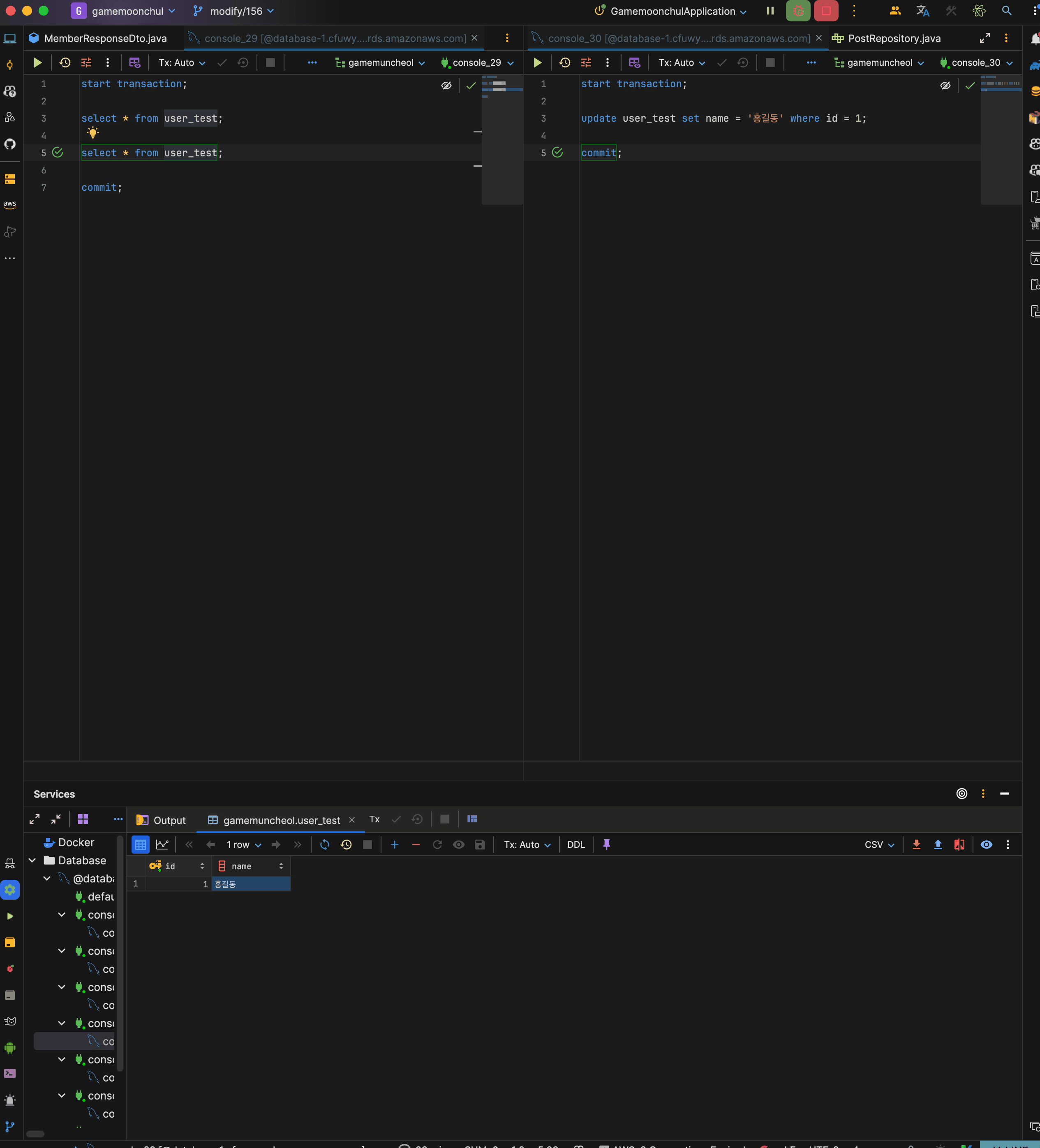
현재 test user id = 1은 홍길동인 상황
시나리오
- transaction 1 시작
- trasnaction 1에서 현재 데이터 읽기
- trasnaction 2 시작
- transaction 2에서 id = 1 name을 적길동으로 변경 후 커밋
- trasnaction 1에서 현재 데이터 읽기 : 홍길동 출력
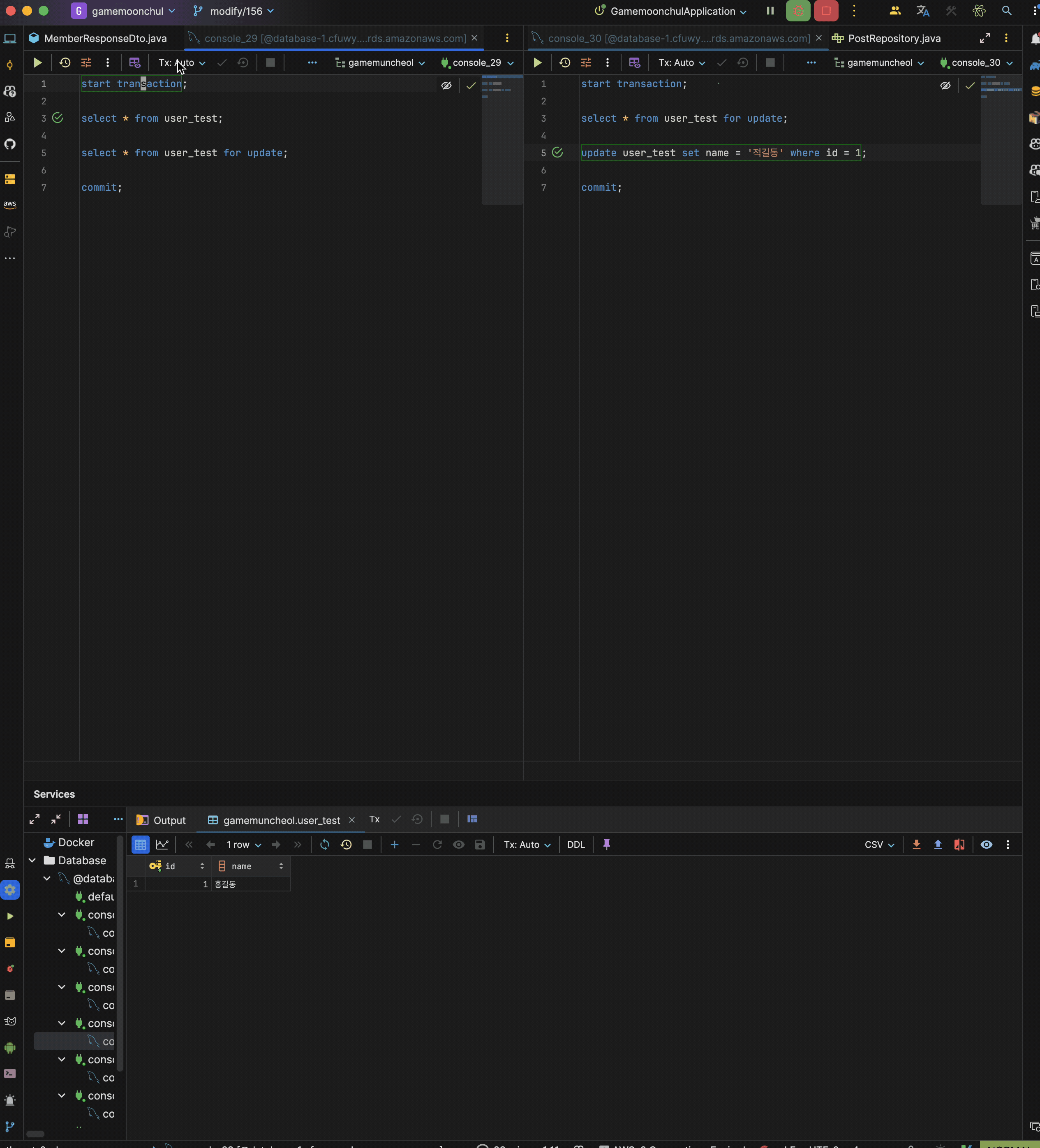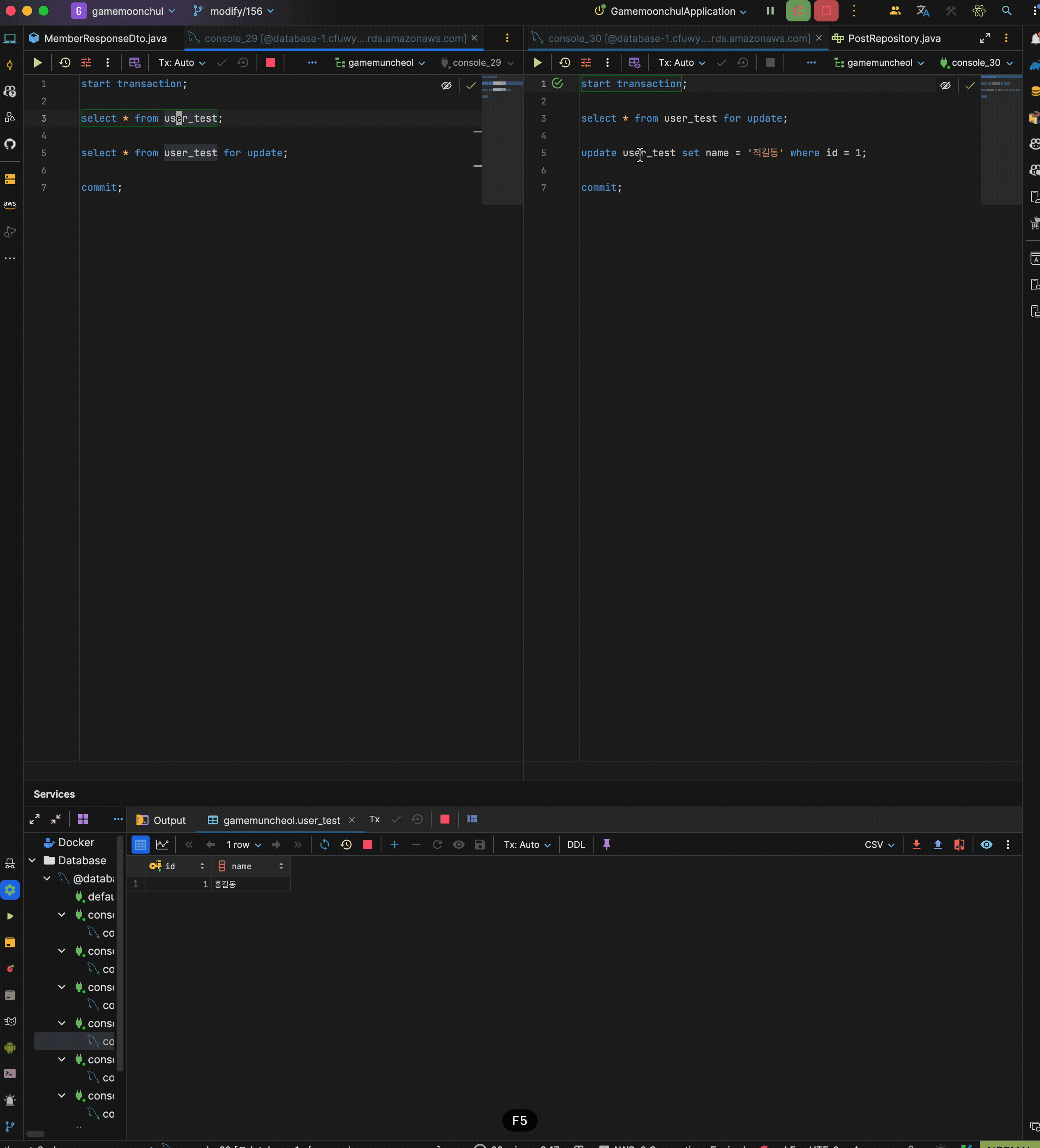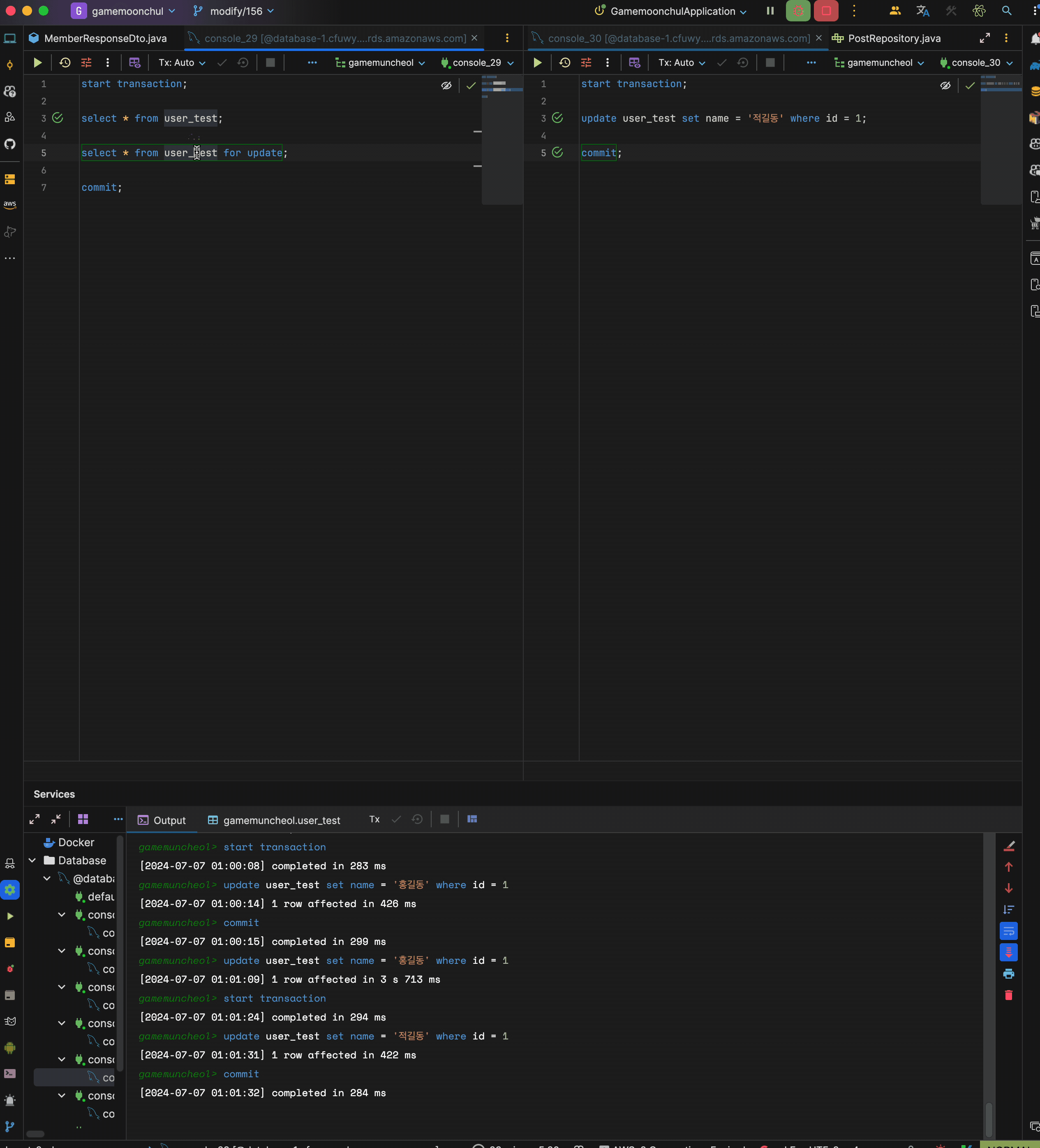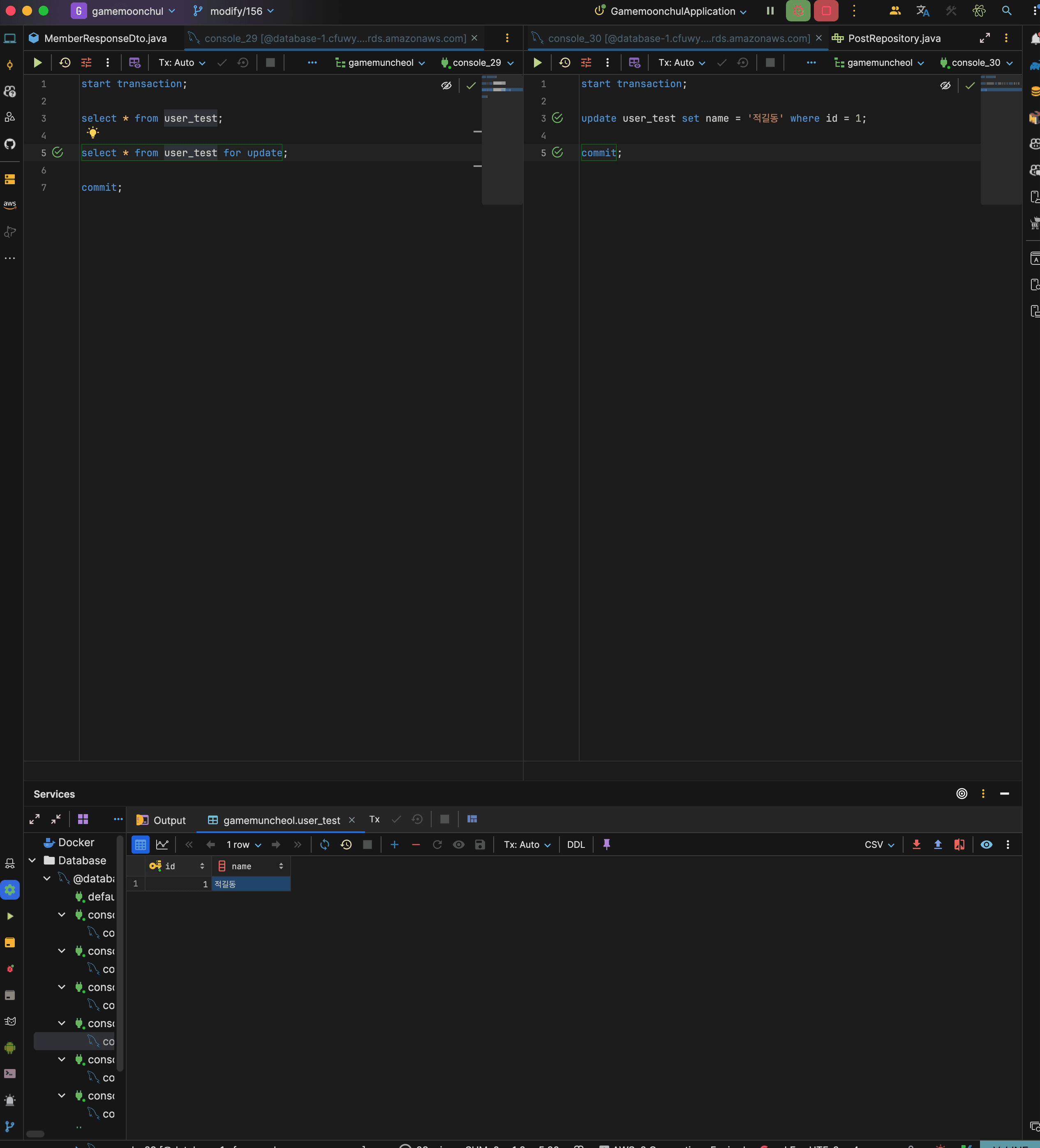
락을 사용하는 경우 실험
테스트 조건과 시나리오는 위와 동일하지만 단 transaction 1의 2번째 셀렉트 쿼리는 for update를 적용
시나리오
- transaction 1 시작
- trasnaction 1에서 현재 데이터 읽기 : 홍길동 출력
- trasnaction 2 시작
- transaction 2에서 id = 1 name을 적길동으로 변경 후 커밋
- trasnaction 1에서 현재 데이터 읽기(for update) : 적길동 출력
MySQL의 REPEATABLE READ와 Phantom Read
MySQL도 Postgres처럼 REPEATABLE READ에서 Phantom Read가 발생하지 않는데 이는 Next Level Lock + Gap Lock 때문이라고 한다.
- Gap Lock
- 인덱스 레코드 사이의 간격(gap)에 대해 잠금을 걸어 새로운 행의 삽입을 방지하는 잠금 방식
- 예를 들어서 마지막 인덱스가 39라고 하면 39와 "무한대" 사이의 간격에 대해서도 잠금이 걸림 (이후 데이터 삽입이 방지됨)
- Next Key Lock
- 인덱스 레코드와 그 앞의 간격을 함께 잠그는 방식
- 레코드락 + 갭락을 결합한 형태
- 출처 : MySQL 공식문서

흥미롭네요. 잘보고갑니다.