
인구 소멸위기지역 분석
1) 목표
- 인구소멸 위기 지역 파악
- 인구소멸 위기 지경의 지도 표현
- 지도 표현에 대한 카르토그램 표현
fillna()
시작하기 앞서 fillna()에 대해 알아보자.
- 랜덤 데이터 생성
datas = { "A":np.random.randint(1,45,8), "B":np.random.randint(1,45,8), "C":np.random.randint(1,45,8) } datas{'A': array([ 6, 20, 14, 5, 31, 38, 14, 21]), 'B': array([34, 36, 42, 11, 18, 28, 29, 24]), 'C': array([18, 26, 37, 26, 33, 25, 40, 14])}
- 데이터프레임으로 만들기
fillna_df = pd.DataFrame(datas) fillna_df
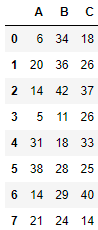
- NaN값 loc이용해서 넣기
fillna_df.loc[2:4, ["A"]] = np.nan fillna_df.loc[3:5, ["B"]] = np.nan fillna_df.loc[4:7, ["C"]] = np.nan fillna_df
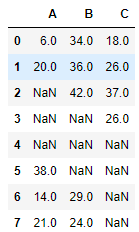
- fillna()
- method ="pad", method ="ffill"
NaN값이 있다면 위의 내용을 복사해와라- method = "backfill", method = "bfill"
NaN값이 있다면 밑의 값을 복사해 와라fillna_df.fillna(method="ffill")
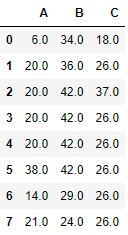
2) 데이터 읽고 인구소멸지역 계산

- 모듈 import
import numpy as np import pandas as pd import matplotlib.pyplot as plt from matplotlib import rc import seaborn as sns import warnings warnings.filterwarnings(action="ignore") #한글 꺠짐 방지 rc("font", family="Malgun Gothic") #마이너스 기호 깨짐 방지 rc("axes",unicode_minus=False) #주피터 노트북 안에 그래프를 그리겠다. # %matplotlib inline get_ipython().run_line_magic("matplotlib", "inline")
- 액셀 파일 불러오기
- header=1을 사용하는 이유는 1행에 년도수가 작성되있는 것을 없애기 위해
population = pd.read_excel("../data/07_population_raw_data.xlsx", header = 1) population.fillna(method="pad", inplace=True) population
- 가져온 데이터 정보 확인
population.info()
- 846개씩 잘 가져왔다.

- 컬럼명 변경
# 컬럼 이름 변경 population.rename( columns={ "행정구역(동읍면)별(1)": "광역시도", "행정구역(동읍면)별(2)": "시도", "계" : "인구수" }, inplace = True ) population.head()
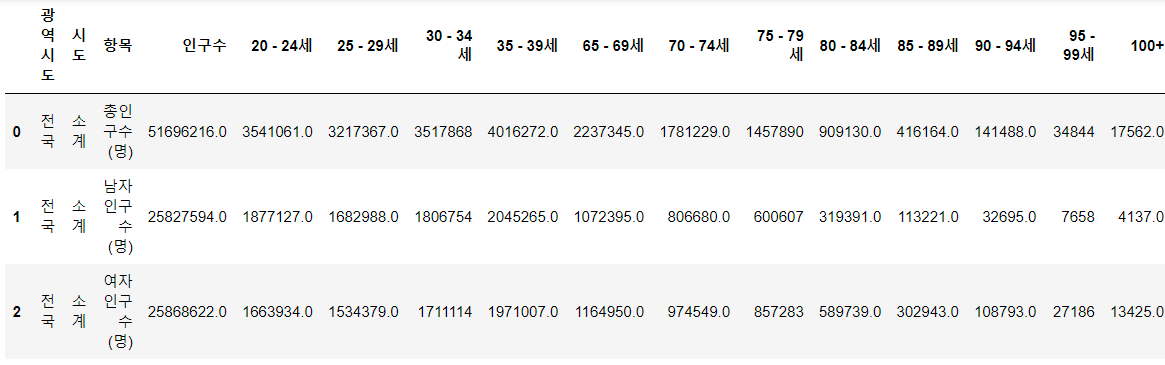
- "시도"컬럼에 소계 라는 쓸데없는 데이터 지워주기
population = population[population["시도"] != "소계"] population.head()
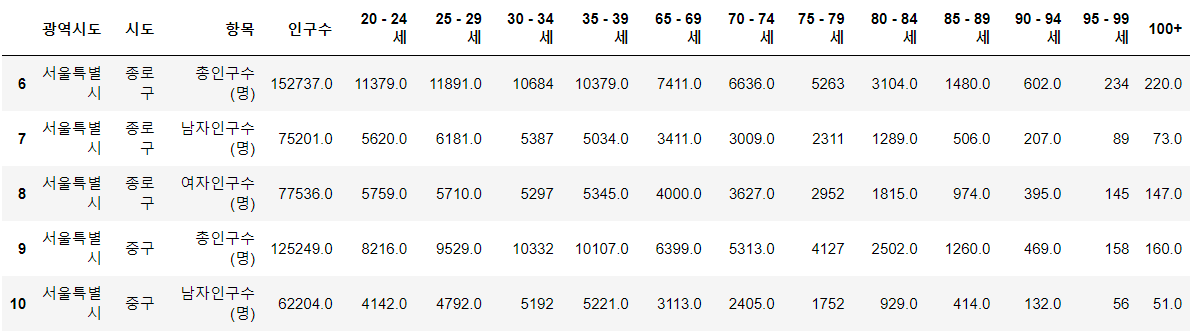
- "항목"컬럼 "구분"으로 컬럼명 변경
population.rename( columns = {"항목":"구분"},inplace=True )

- "구분"행의 "총 인구수","남자인구수","여자인구수"를 "합계","남자","여자" 로 변경
population.loc[population["구분"] == "총인구수 (명)", "구분"] = "합계" population.loc[population["구분"] == "남자인구수 (명)", "구분"] = "남자" population.loc[population["구분"] == "여자인구수 (명)", "구분"] = "여자"

- 소멸위험지수는 65세 고령 인구 대비 20~39세 여성인구 비중이 0.5이하이면 소멸위험으로 간주
- 소멸위험지수를 구하도록 컬럼을 추가 시킨다.
# 소멸지역을 조사하기 위한 데이터 #나이 컬럼 하나로 정리 population["20 - 39세"] = ( population["20 - 24세"]+ population["25 - 29세"]+ population["30 - 34세"]+ population["35 - 39세"] ) population["65세 이상"] = ( population["65 - 69세"]+ population["70 - 74세"]+ population["75 - 79세"]+ population["80 - 84세"]+ population["85 - 89세"]+ population["90 - 94세"]+ population["95 - 99세"]+ population["100+"] )

- 좀 더 보기 편하게 pivot_table을 이용해 정리하자.
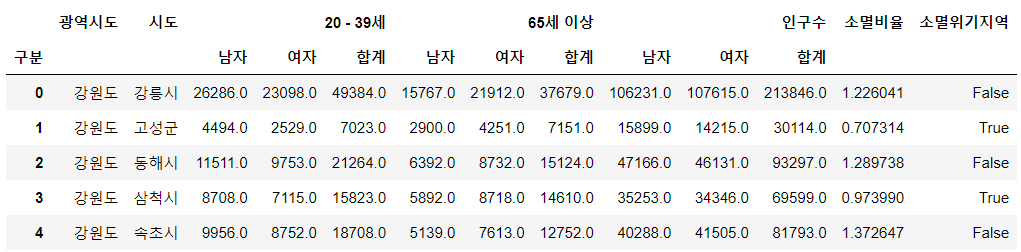
# Pivot_table pop = pd.pivot_table( data = population, index = ["광역시도","시도"], columns = ["구분"], values = ["인구수","20 - 39세","65세 이상"] ) pop
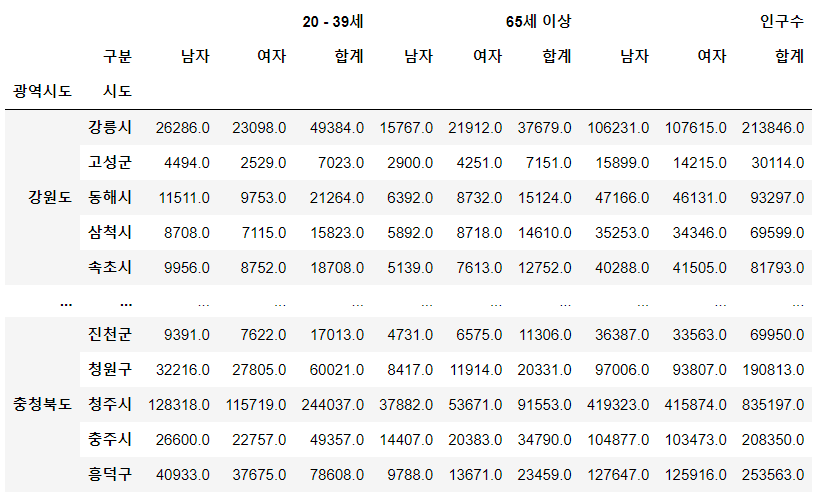
- 소멸 비율 컬럼 추가 (계산식)
pop["소멸비율"] = pop["20 - 39세", "여자"] / (pop["65세 이상","합계"] / 2) pop
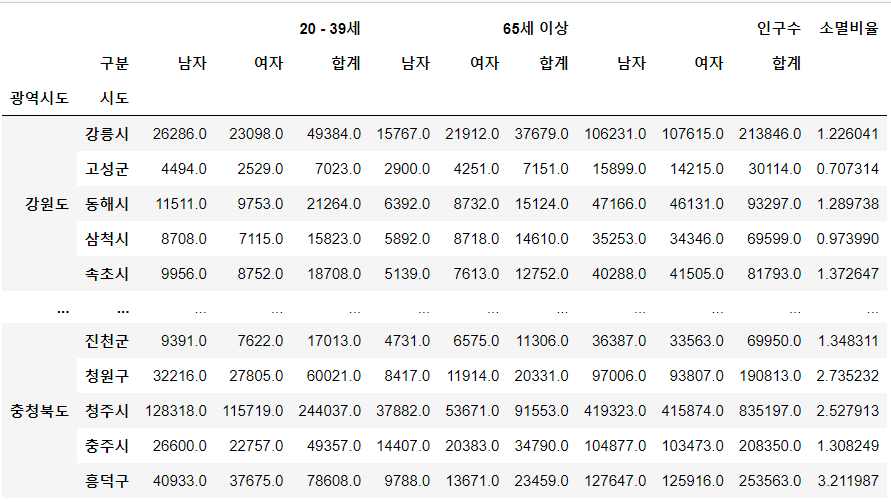
- "소멸위기지역" 컬럼 추가(bool)
pop["소멸위기지역"] = pop["소멸비율"]<1.0 pop
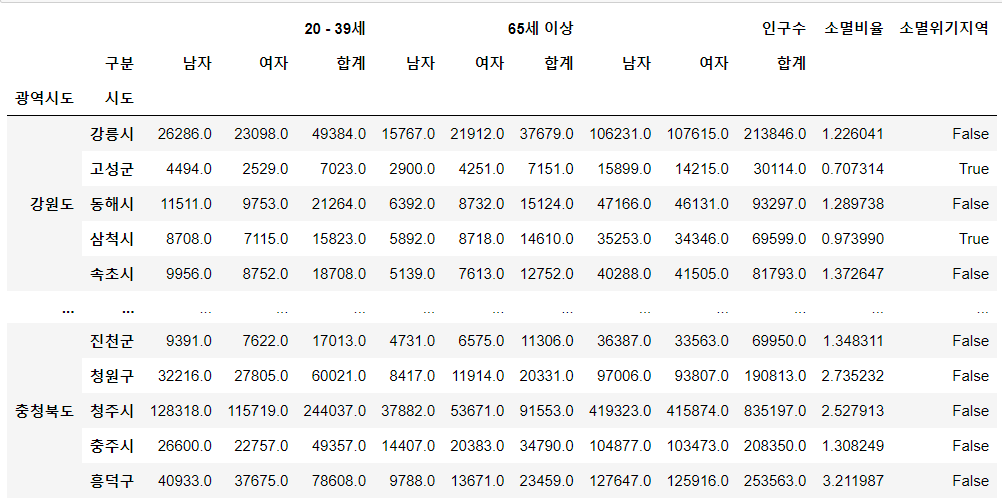
- 소멸위기지역 조회
index.get_level_values(1) : 인덱스의 2번째 데이터pop[pop["소멸위기지역"] == True].index.get_level_values(1)

- index 재정렬
pop.reset_index(inplace = True) pop.head()
3) 지도 시각화를 위한 지역별 ID 만들기
전국 구역을 ID로 만들때 고민할 점
- 광역시는 시, 구 로 끝난다.
- 광역시가 아닌데 시, 구로 끝나는 지역도 있다.(용인시 수지구)
- 중구 같은 경우는 여러곳에 있다.
- ID형태
- 서울 중구- 서울 서초
- 통영
- 포항 북구
- "시도" 컬럼 unique값 읽어보기
pop['시도'].unique()

이 모든 시.도 가 유일한 ID가 있어야 시각화 가능
- 만든 ID를 넣어 줄 리스트 만들어 놓기
si_name = [None] * len(pop) si_name
- 행정구 지역만 따로 딕셔너리를 만들어 준다.
- 우리가 만들어야 하는 ID 형태는 "서울 중구" 이런 식인데
광역시 같은 경우는 상관 없지만 일반 시의 경우 "경기도 안양시 만안구" 으로 가져 올 수가 없다. 따라서 행정구만 따로 키값을 조회해 값들을 하나씩 가져오기 위해 딕셔너리 형태로 만들어 놓은 것- 하나씩 다 쳐줄 수 밖에..

3-1 일반 시 이름과 세종시, 광역시도 일반 구 정리
작성된 코드를 말로 풀어 써보자
- "광역시도"컬럼의 값에서 뒤에서3자리 부터 끝까지 "광역시","특별시","자치시"라는 단어가 없다면 si_name에 인덱스에 "시도"컬럼의 뒤의 한자리를 빼고 넣어라
- 그게 아니고 "광역시도"컬럼이 "세종특별자치시"라면 si_name에 "세종"이라고 넣어라
- 이것들 말고는
만약
"시도"컬럼의 길이가 2인 경우 si_name에 "광역시도"컬럼의
앞2자리+공백+"시도"컬럼 을 넣어주고
아니라면
si_name에 "광역시도"컬럼의 앞2자리 + 공백 + "시도"컬럼의 뒤의 한자리 빼고 모두를 넣어라

si_name을 확인해 보면 쭉 코드를 통해 들어온 값들을 확인 할 수 있다.
3-2 행정구
이제 행정구들을 ID로 저장해야 한다.
- pop에서
만약
"광역시도"컬럼의 값에서 뒤에서3자리 부터 끝까지 "광역시","특별시","자치시"라는 단어가 없다면
tmp_gu_dict의 값들 키들중
만약
value에 "시도"컬럼이 있고
"시도"컬럼의 길이가 2이면 si_name에 해당 keys값 + 공백 + "시도"컬럼value
또 그게 아니면
"마산합포구",와 "마산회원구"가 "시도"컬럼에 있으면 si_name에
keys값 + 공백 + 해당"시도"컬럼 3번째글부터 뒤에서 한자리 까지 넣어주고
그것도 아니면
si_name에 keys값 + 공백 + "시도"컬럼의 뒤의 한자리 빼고 넣어라
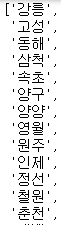
si_name확인하면 행정구 추가되었다.
3-3 고성군
고성군이 강원도에도 있고 경상남도에도 있어서 별도로 구별지어 넣어줘야 한다.
- pop에서
만약
"광역시도"컬럼의 값에서 뒤에서3자리 부터 끝까지 "광역시","특별시","자치시"라는 단어가 없다면
또 만약
"시도"컬럼의 뒤에 한자리 뺀 글이 "고성" 이고 "광역시도"컬럼이 "강원도" 이면 si_name에 "고성(강원)을 넣고
이게 아니고
"시도"컬럼의 뒤에 한자리 뺀 글이 "고성"이고 "광역시도"컬럼이 경상남도 라면 si_name에 "고성(경남)"을 넣어줘라

si_name을 확인하면 행정구도 추가된 것을 확인 할 수 있다.
- 지금껏 만든 si_name으로 "ID"컬럼을 추가
pop["ID"] = si_name
잘 들어왔다..

- 이제 필요없는 컬럼들은 지워주자.
del pop["20 - 39세남자"] del pop["65세 이상남자"] del pop["65세 이상여자"]

4) 지도 그리기(카르토그램)
카르토그램이란게 뭘까?
지역별 결과를 한눈에 보기 좋다.
제공받은 액셀 파일 : 한국지도 구역별 간략화
draw_koera_raw = pd.read_excel("../data/07_draw_korea_raw.xlsx") draw_koera_raw
그냥보면 이게 뭔가 싶을지 모른다.
가장 끝만 선으로 그려보자.
진짜 대단하시다..
보통 사람이라면 못 할거다.
나는 보통사람이 안되도록 노력해야겠다.

stack() : 컬럼을 인덱스로
- 액셀에서의 열 번호를 Y축이라 보고, 행번호를 X축이라 보자
- stack을 사용해 좌표를 받아오자
draw_koera_raw.stack()

- 데이터 프레임형식으로 만들어 주자
draw_koera_raw_stacked = pd.DataFrame(draw_koera_raw.stack()) draw_koera_raw_stacked

- 인덱스 재정렬 해주자
draw_koera_raw_stacked.reset_index(inplace=True) draw_koera_raw_stacked
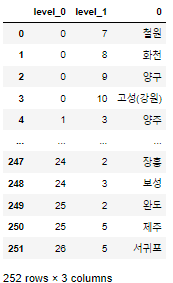
- 컬럼명을 맞게 변경
draw_koera_raw_stacked.rename( columns = { "level_0":"Y", "level_1":"X", 0:"ID" }, inplace=True ) draw_koera_raw_stacked

- draw_korea로 데이터프레임 이름 변경
- 너무 기니까 보기 좋게 바꾸신듯
draw_korea = draw_koera_raw_stacked
- 액셀내에 광역시, 특별시, 지자체 경계선 긋기
- 액셀표현은 잘 몰라서 강의내용을 따라갔다.
- 구글링을 좀 더 해봐야 겠다.
#경계선 그리기 BORDER_LINES = [ [(5, 1), (5, 2), (7, 2), (7, 3), (11, 3), (11, 0)], # 인천 [(5, 4), (5, 5), (2, 5), (2, 7), (4, 7), (4, 9), (7, 9), (7, 7), (9, 7), (9, 5), (10, 5), (10, 4), (5, 4)], # 서울 [(1, 7), (1, 8), (3, 8), (3, 10), (10, 10), (10, 7), (12, 7), (12, 6), (11, 6), (11, 5), (12, 5), (12, 4), (11, 4), (11, 3)], # 경기도 [(8, 10), (8, 11), (6, 11), (6, 12)], # 강원도 [(12, 5), (13, 5), (13, 4), (14, 4), (14, 5), (15, 5), (15, 4), (16, 4), (16, 2)], # 충청북도 [(16, 4), (17, 4), (17, 5), (16, 5), (16, 6), (19, 6), (19, 5), (20, 5), (20, 4), (21, 4), (21, 3), (19, 3), (19, 1)], # 전라북도 [(13, 5), (13, 6), (16, 6)], [(13, 5), (14, 5)], # 대전시 # 세종시 [(21, 2), (21, 3), (22, 3), (22, 4), (24, 4), (24, 2), (21, 2)], # 광주 [(20, 5), (21, 5), (21, 6), (23, 6)], # 전라남도 [(10, 8), (12, 8), (12, 9), (14, 9), (14, 8), (16, 8), (16, 6)], # 충청북도 [(14, 9), (14, 11), (14, 12), (13, 12), (13, 13)], # 경상북도 [(15, 8), (17, 8), (17, 10), (16, 10), (16, 11), (14, 11)], # 대구 [(17, 9), (18, 9), (18, 8), (19, 8), (19, 9), (20, 9), (20, 10), (21, 10)], # 부산 [(16, 11), (16, 13)], [(27, 5), (27, 6), (25, 6)] ]
4-1) 검증 작업
pop데이터와 draw_korea데이더의 공통된 컬럼인 ID로 병합이 가능한지 검증을 해보자
set()는 검증할때 사용 가능하다. 집합함수이다.
- 먼저, draw_korea의 unique값에서 pop의 unique값을 빼보자
set(draw_korea["ID"].unique()) - set(pop["ID"].unique())set()오.. draw_korea의 ID컬럼에 있는 값들은 pop의ID컬럼에 모두 있다는 말이다.
- 그럼 반대로 했을때도 아무런 값이 없다면 정확히 일치한다는 말이다.
set(pop["ID"].unique()) - set(draw_korea["ID"].unique()){'고양', '부천', '성남', '수원', '안산', '안양', '용인', '전주', '창원', '천안', '청주', '포항'}하..가만보니 si_name을 만들 때 행정구들이다.
병합(merge)를 하기 위해서는 정확히 일치 해야 하기 때문에 위 결과들을 pop에서 지우자.
- pop에서 행정구들 지우기
- 위에 나온 값들을 pop의 "ID"컬럼에서 발견하면 해당 index를 지운것이다.
tmp_list = list(set(pop["ID"].unique()) - set(draw_korea["ID"].unique())) for tmp in tmp_list: pop = pop.drop(pop[pop["ID"] == tmp].index) print(set(pop["ID"].unique()) - set(draw_korea["ID"].unique()))set()
이제 병합이 가능하다.
- pop과 draw_korea를 pop에다가 ID컬럼으 기준으로 병합
pop = pd.merge(pop, draw_korea, how = "left", on = "ID") pop.head()

이제 키토그램을 표현해 줄 여러 함수를 만들어 보자.
이해를 돕기 위해 이번 강의의 결과물을 먼저 보면서 작성해 보겠다.

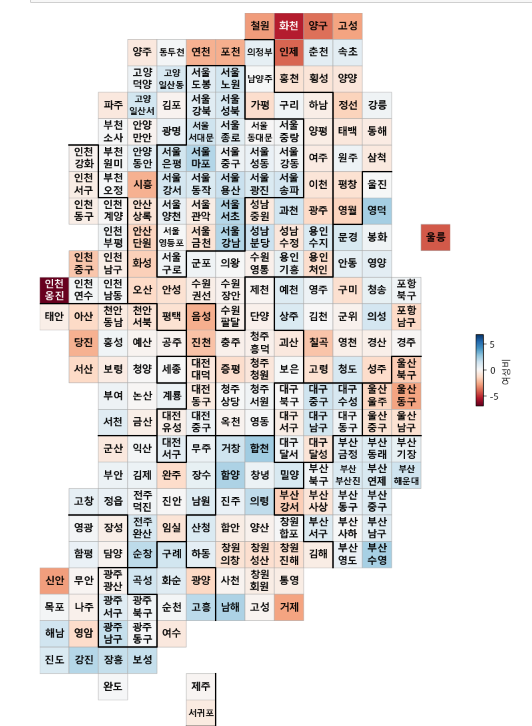
- 위 첫번째 결과물에서 오른쪽 인구수가 적어질 수록 하얗고 많을수록 파랗게 표현을 하게 해주는 형식의 함수를 만들어 보자.
def get_data_info(targetData, blockedMap): whitelabelmin = ( max(blockedMap[targetData]) - min(blockedMap[targetData]) ) * 0.25 + min(blockedMap[targetData]) vmin = min(blockedMap[targetData]) vmax = max(blockedMap[targetData]) mapdata = blockedMap.pivot_table(index ="Y", columns ="X", values = targetData) return mapdata, vmax, vmin, whitelabelmin
- 위 두번째 결과물에서 오른쪽에 0을 기준으로 멀어질 수록 원색을 나타내게 해주는 형식의 함수 만들어 보자.
def get_data_info_for_zero_center(targetData, blockedMap): whitelabelmin = 5 tmp_max = max( np.abs(min(blockedMap[targetData])), np.abs(max(blockedMap[targetData])) ) vmin, vmax = -tmp_max, tmp_max mapdata = blockedMap.pivot_table(index ="Y", columns ="X", values = targetData) return mapdata, vmax, vmin, whitelabelmin
- targetData는 우리가 결과로 보고싶은 컬럼이다.
- blockedMap은 우리가 데이터를 가져올 데이터프레임이다.
- 함수 안의 whitelabelmin은 액셀 지도상에 하얀바탕이 들어간다면 글씨는 까만게 잘보일 것이고 진한 색이 들어가면 연한색의 글이 잘보일테니 그것의 경계선을 구해주는 계산식이다.
- mapdata는 blockedMap에서 표현하고 싶은 값들을 액셀지도상의 좌표에 넣을 수 있도록 다시 액셀의 x,y축 값들을 정리시킨 것.
- 액셀 지도에 지역 이름을 표현해주는 함수
def plot_text(targetData, blockedMap, whitelabelmin): for idx, row in blockedMap.iterrows(): if len(row["ID"].split()) ==2: dispname="{}\n{}".format(row["ID"].split()[0], row["ID"].split()[1]) elif row["ID"][:2] == "고성": dispname = "고성" else: dispname = row["ID"] # 액셀지도상 3글자 이상이면 글자크기 작게 if len(dispname.splitlines()[-1]) >=3: fontsize, linespacing = 9.5, 1.5 else: fontsize, linespacing = 11, 1.2 annocolor = "white" if np.abs(row[targetData]) > whitelabelmin else "black" #액셀에 주석을 다는 기능 plt.annotate( dispname, (row["X"]+ 0.5, row["Y"]+0.5), weight = "bold", color = annocolor, fontsize = fontsize, linespacing = linespacing, ha = "center", #수평 정렬 va = "center" #수직 정렬 )
- 마지막으로 카르토그램 결과를 반환해주는 함수
def drawKorea(targetData, blockedMap, cmapname, zeroCenter=False): #zeroCenter가 True일때, False일때 if zeroCenter: masked_mapdata, vmax, vmin, whitelabelmin = get_data_info_for_zero_center(targetData, blockedMap) if not zeroCenter: masked_mapdata, vmax, vmin, whitelabelmin = get_data_info(targetData, blockedMap) plt.figure(figsize=(8,11)) plt.pcolor(masked_mapdata, vmin = vmin, vmax=vmax, cmap=cmapname, edgecolor="#aaaaaa", linewidth=0.5) plot_text(targetData,blockedMap, whitelabelmin) #경계선 그리기 for path in BORDER_LINES: #BORDER_LINES에서 x,y좌표끼리 모아준 것 ys, xs = zip(*path) plt.plot(xs, ys, c="black", lw =1.5) #액셀상에서는 열이 내려갈 수록 수가 오르지만 보통의 Y축 증가는 수직으로 올라간다. #따라서, 상하를 뒤집어 줘야 액셀상에 우리가 아는 지도모양이 나온다. plt.gca().invert_yaxis() #지도상 글들을 정렬 plt.axis("off") plt.tight_layout() cb = plt.colorbar(shrink = 0.1, aspect=10) cb.set_label(targetData) plt.show()
- pop에 "인구수합계"컬럼을 기준으로 파랑색으로 결과물 보기
drawKorea("인구수합계", pop, "Blues")
- 소멸위기지역 컬럼이 True이면 1, False이면 0을 넣어 소멸위기지역 결과 보기
pop["소멸위기지역"] = [1 if con else 0 for con in pop["소멸위기지역"]]
drawKorea("소멸위기지역", pop, "Reds")
- 여성비 컬럼 추가해서 여성비 확인

이 결과만 보면 여성비는 전국적으로 높다.
하지만..
인구소멸과 밀접한 20~39세 여성비로 봐보자.
pop["2030여성비"] = (pop["20 - 39세여자"] / pop["20 - 39세합계"] - 0.5) *100
drawKorea("2030여성비", pop, "RdBu", zeroCenter=True)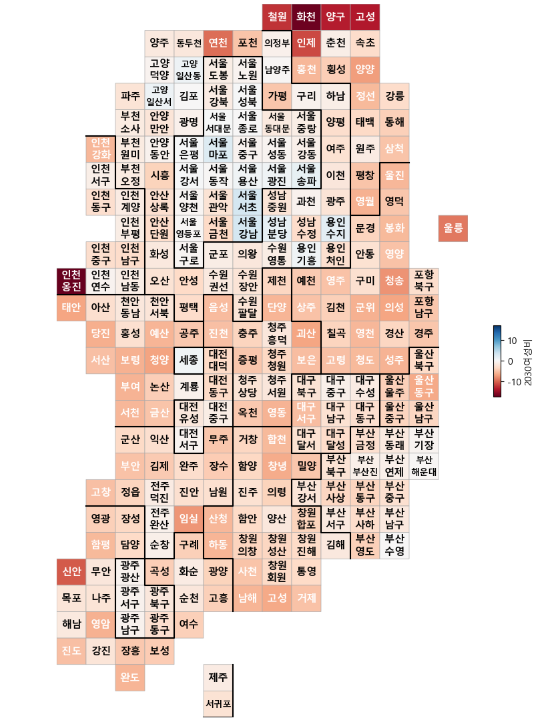
이론 수업에서 강사님이 이 결과를 보시고는
"여자친구 없으신 분들은 강의끄고 얼른 여자친구 찾으러 가세요"
라고 말씀하셨는데 피식했다.
그리고는 물인지 땀인지 눈이 흐릿해졌다..
