유튜브에서 diff-svc 영상을 보고 흥미로워서 자료를 찾게되었다.
그전에 diff-svc에 대해 간략하게 소개하자면 diff-svc는 이미지 생성모델인 Difussion model을 그대로 음원에 적용하여 음성보이스를 생성하는 모델인데 diff-svc는 음원을 파형의 형태로 이미지화 시켜서 이를 학습 시키는거라 difussion model과 기술적 근간은같다.
여러가지 레퍼런스를 찾아보니 보통 GCP(google cloud platform)내의 Colab을 이용한다고 해 다양한 코랩 리포지토리를 찾다 적당한 레포지토리를 발견하게되었다.
GCP에 접속한 후 로그인 을 한 뒤 주어진 절차대로 실행해 주자.
하라는대로 GPU cuda 확인 , google drive 마운트하고 다음으로 넘어가자.

사전 모델 레포지토리를 포크해야하는데 두가지 버전이 있다.
Official Diff-SVC Repo / UtaUtaUtau's Repo
두개의 사전모델을 모두 사용해보았는데 경험상 UtaUtaUtau's repo 버전이 더 결과가 잘 나오기에 저걸로 고르고 포크를 해주자.
그리고 하게되면 런타임 오류가 뜨고 notebook을 다시 시작해야된다는 알림이뜨는데 무시해도됨. 드라이브에는 정상적으로 diff-svc 폴더가 생성되었다면 성공한거니 그냥 넘어가도 좋다.

sample rate 설정, 44.1 khz로 두고 순차적으로 쭉쭉 실행해주자.
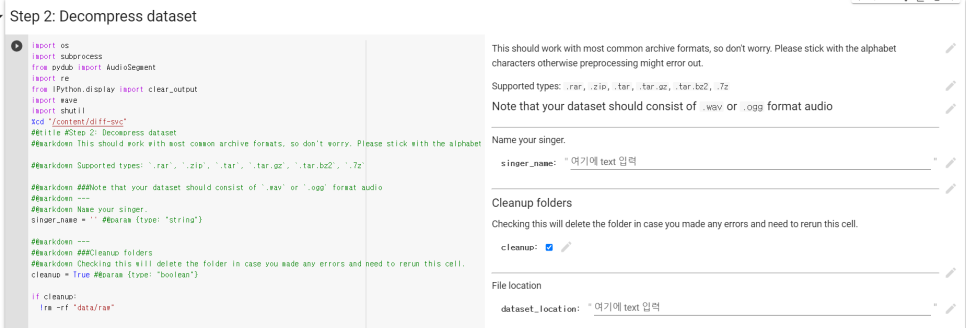
이제부터 중요한데 singer_name에 적당한 이름 적어주고 dataset_location에 내가 학습 시킬 음원을 담아줘야한다. 데이터셋의 형식은모노, 44100hz, .wav파일, 10~15초 분량의 공백이 거의 없는 음성, 배경음이 최소며 목소리만 선명하게 들리는 음성, 이 기준을 모두 만족하는 음성파일을 하나의 파일로 압축을 해 제공해야한다.
우선 데이터셋을 만들기위해 녹음을 진행하고 선명한 목소리를 따기위해 Adobe Podcast Ai를 활용해 데이터 전처리를 하였다.
이후 파이썬의 ffmpeg 라이브러리를 활용해 나는 따로 파이썬 코드를 작성해서 전체 음성을 규격에 맞게 포매팅해서 데이터셋으로 압축해주었다.
그리고 10~15초 짜리 .wav 파일을 800개를 만들어 총 2시간 정도의 분량의 일반적으로 말할때 목소리랑 노래할때의 음성 데이터셋을 준비했다.
중요한점이 무엇보다도 말하는 영상과 노래하는 음성도 음질의 퀄리티와 음역대가 중요한데, 추 후에 노래에 자신의 목소리를 입히는과정에서 고음 데이터가 많이 없으면 소리가 깨지는 현상이 발생하기에 자신이 낼 수 있는 최대한 높은 노래로 많이 불러 데이터를 만들어두자.(힘들다)
이후 step 2 코드를 실행하고
이 부분은 나중에 자신이 만든 모델을 추가적으로 학습시키거나 데이터셋을 추가하였을때 이어서 하는부분이기 때문에 넘어가도 좋다.

적당히 구글드라이브에 경로를 하나 생성하고 save_dir 을 작성해주고 ckpt_directory부분은 현재 건드릴 필요가없다.
저 영역이 특정 step에서 학습을 종료한 모델을 가지고 다시 추가 학습을 하고싶을때 resume_training_from_ckpt 버튼을 체크하고 ckpt파일을 업로드하여 실행하면되는데 지금으로는 필요하지않으니 그냥 넘어가면댄다.
만약 자기가 생성한 데이터셋 분량이 30분 미만이면 endless_ds 체크해주자.
체크하면 빨리된다. 대신 분량이 많으면 체크 풀고 하면된다

save_binary_to_gd 체크해주자, 체크하면 binary_data.7z 파일이 저장될건데 중요한 파일이니 잘 보관해두자.
이 구간에서 조금 시간이 걸리긴한다.

이건 그냥 학습과정 통계볼거냐는건데 난 그냥 안했음 넘어가도 무방

그리고 실제로 학습을 하는 대망의 코드.
이코드를 실행하고 실행로그에 얼마지나지않아 steps가 1부터 점차 오르기 시작한다면 학습이 시작되는것이다.
2000 단위로 자동으로 학습한 체크포인트 파일을 생성해 추후에 해당 체크포인트부터 이어서 학습하는것이 가능하다.
이 구간에서 가장 GCP를 무료로 사용하면 일어나는 문제점이 발생하는데,
-
사용시간이 초과되었거나
-
GPU 사용량이 너무 급증하였거나
-
10~15분 이상 잠수를 타거나
-
다른사람들이 리소스를 더 많이 사용하게되어 부족하다면
연결이 끊기게된다...
필자는 학습시키는 과정에서 자기전에 컴퓨터를 틀어놓고 다음 자바스크립트 코드를 개발자 콘솔에 입력시켜놓고 나뒀다.
function ClickConnect(){
console.log("colab disconnect shield");
document.querySelector("colab-toolbar-button#connect").click()
}
setInterval(ClickConnect, 60 * 1000)나름 꼼수긴한데 이렇게 해도 타임아웃이 나서 종료는안되지만 오래학습하게 냅두면 GPU 사용량 초과라고 뜬다..
무료로 학습을 시킨다면 구글 계정 2개를 돌리면 편하다. 필자는 계정 2개를 돌려가면서 학습 시켰다.
아마 학습 시간에만 2~3일 정도가 경과한 것 같다. 실제로 걸린 시간은 20~30시간 정도인 듯
steps는 76000정도, 6만 넘어가는 시점에서부터 괜찮은 퀄리티로 뽑힌다.
그리고 적당히 학습을 마쳤으면 프로그램을 중지하고 생성된 ckpt파일을 확인하고 노래를 입히면댄다

마지막으로 실제 노래를 뽑는 코드인데
오른쪽에보이는 매개 변수들의 의미는 다음과같다
model_path : 내가학습시킨 모델파일(ckpt 젤 높은걸로 하면됨)
config_path : pre-train할때 나온 config_nsf.yaml 나 config.yaml 파일 경로 적으면댐
wav_in : 내가 입히고싶은 노래 wav 파일 ( .wav 파일 형식도 동일하게 모노, 44100 맞춰주는게 좋음 )
그리고 내가 원하는 노래의 mr제거 파일을 얻기 힘들다면 다음 주소를 이용하자.
여기 써봤는데 무료에 결과도 되게 괜찮은품질으로 나온다.
Key : Key 는 wav_in 음원 키를 정하는거임 만약 결과가 나왔는데 고음부분에서 깨지거나 쇳소리가 들린다면 키를 단계적으로 내려보는걸 추천
pndm_speedup : 학습 품질 낮아지는대신 결과 빨리 보여주는옵션
add_noise_step : 이 값 올리면 올릴수록 원본 wav_in 의 음성을 따라가는걸로 알고있다.
thre : 약자만봐서는 스레드인거같은데 잘모르겠음 이건 그냥 안건들여도된다.
use_crepe : 건들지 말것
use_pe : 건들지 말것
학습시킬때 pndm_speedup, add_noise_step 0으로 맞추고 나머지는 다 기본값으로 맞추고 음이 깨진다 싶으면 키를 조절하는게 제일 나은것같다.
낮춰도 음질이 이상하면 학습을 더해야되거나 데이터셋의 퀄리티를 늘려야한다.
다 끝나면 diff-svc 폴더내에 result에 sample.flac이라고 파일이 생기는데 그 파일이 내 목소리를 학습한 ai가 대신불러주는 노래 음원이다.
대충 mr이랑 합치고 손본 결과는 다음과같다..!
