[논문 요약] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks

1. Introduction

Image-to-Image translation은 paired training data를 이용해 input image와 output image 간의 상관관계를 학습한다.
ex) Pix2Pix
그런데 만약 Paired Training data를 구할 수 없다면?

Q. Unpaired Training data의 상관관계는 어떻게 찾아낼까?
A. GAN 기법을 이용해 해결할 수 있는데, 적대적 훈련 (Adversarial Train)된 모델이 과 를 구분할 수 없을 정도로 학습한다. ()
하지만, 와 는 일대일 대응이 아니고 상관관계가 무한하기 때문에 가 와 구분 불가능하다고 하더라도 의미 있는 매핑이 이루어지지 않았을 수 있다.
연구진은 이를 해결하기 위해 Cycle Consistent 개념을 도입했다.

: 매핑 함수
: 매핑 함수
: 와 를 구분하는 판별기
: 와 를 구분하는 판별기
Generator G를 이용해 X에서 Y로 변환하고, 그것을 다시 Generator F를 이용해 Y에서 X로 변환하면 원본이 복구되어야 한다. 즉, G와 F가 서로 역함수의 관계를 가진다면 이를 의미 있는 매핑이라고 유추할 수 있다.
2. Formulation
Adversarial Loss
: 실제 이미지일 때 1, 가짜 이미지일 때 0을 반환하도록 학습
: 실제 샘플과 유사한 가짜 이미지를 생성하도록 학습
는 을 최소화하도록, 는 을 최대화하도록 학습하기 때문에 이를 Adversarial Loss(적대적 학습)이라고 부른다.
Cycle Consistency Loss
와 생성기를 차례대로 지난 원본 가 그대로 복구될 때 가 0이 된다. 도 와 를 지났을 떄 스스로 복구되면 가 0이 된다.
와 간에 무수히 많은 매핑이 존재하는 상황에서 일대일 대응을 만족하는 생성기(의미 있는 translation)을 찾기 위한 Loss이다.
Full Objective
: 과 의 상대적 중요성을 조절한다
3. Implementation
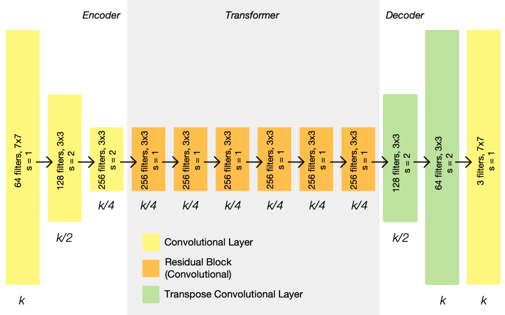
Generator Architecture
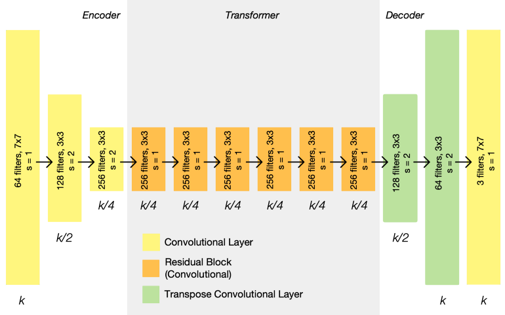
- 3개의 Convolution block을 통해 Input의 크기를 줄임
- 6개의 residual block을 통해 목표한 특성으로 변환
- 3개의 Transposed Convolution block을 지나 크기를 키운 뒤 출력
- 마지막 block은 R,G,B 칼라 이미지를 나타내기 위해 3개의 채널을 가짐
Discriminator Architecture
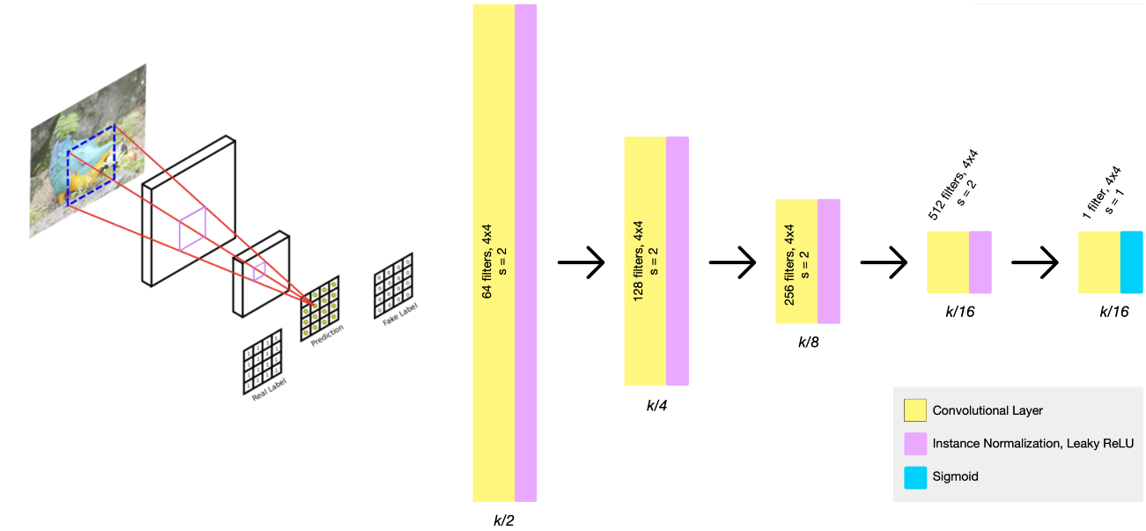
- PatchGAN 모델의 Discriminator 차용
- Classification을 할 떄 이미지 전체를 한꺼번에 보는 것보다 부분적으로 판별하는 것이 더욱 성능이 좋아 사용하게 됨
Training Details
1. Least-square Loss
:
:
앞서 소개한 Adversarial Loss는 Log 함수를 이용했는데, 실제 훈련에서는 Least-square 함수를 사용했다. 이 방식이 더욱 안정적이고 높은 퀄리티를 보여주었다고 한다.
2. Reduce mode oscillation
최신 버전의 Generator로만 다음 학습을 진행하지 않고, 이전에 생성했던 이미지들도 저장해두고 학습에 이용했다. 이는 GAN의 본질적인 문제인 mode oscillation을 방지하기 위한 것으로, Generator와 Discriminator가 서로를 동일한 세기로 속이면 학습이 상쇄되어 진동하는 현상을 말한다.
4. Result
Baselines
1. CoGAN
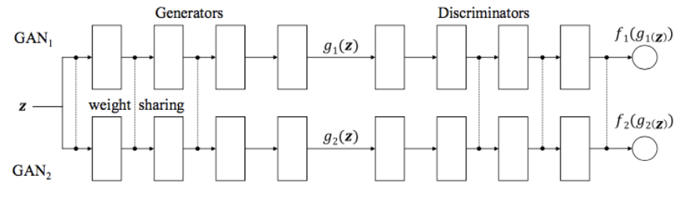
- Weight sharing을 통해 같은 특징 (ex : 얼굴) 을 학습하고, 서로 다른 layer에서는 다른 특징 (ex: 머리 색)을 학습한다
- 특징 A가 드러나도록 하는 가중치들을 찾아 특징 B가 드러나도록 바꾸면 translate 할 수 있다.
2. SimGAN
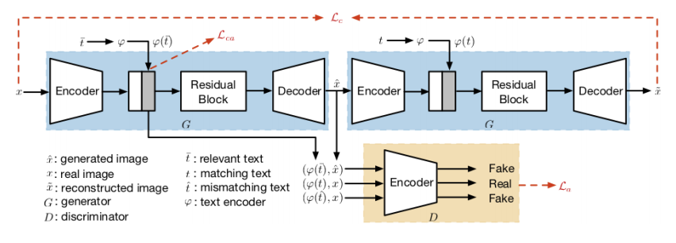
- Generator로 서로 다른 특징 (ex: 검은 날개, 붉은 머리)을 기준으로 image를 생성
- 이것을 같은 generator에 한 번 더 투입해 공통 특징 (ex: 작은 부리)을 기준으로 재생성해 처음의 input image와 동일해지도록 학습
- Adversarial loss와 Cycle loss를 통해 입력한 특징으로 변환하되 공통 특징은 유지해서 실제 같은 image를 생성할 수 있음
3. Feature loss + GAN
Sim – GAN의 변형으로, L1 loss가 단순히 RGB 값 뿐만 아니라 pretrained된 VGG-16 모델을 사용해서 계산된다. Feature loss를 이용하면 image에서 눈, 날개, 깃털 등의 특징 (feature)을 인식해 더욱 자세한 loss를 구할 수 있다.
4. pix2pix
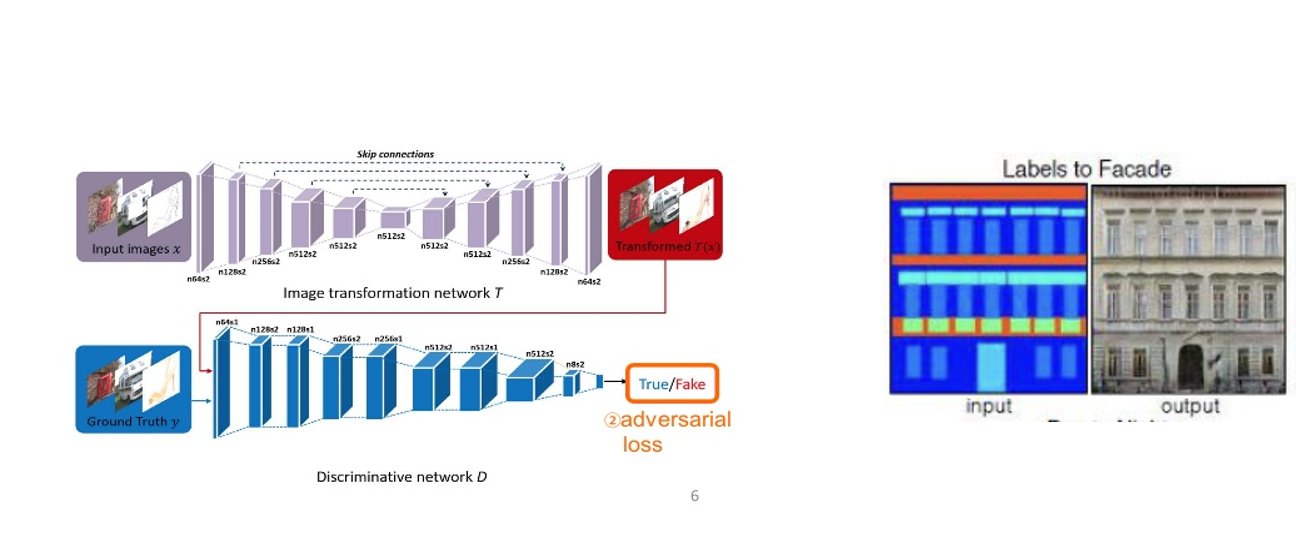
- Paired data를 이용해 Image transformation network를 학습하는 모델
- Unpaired data를 이용하는 Cycle-GAN 성능이 paired data를 이용하는 것에 얼마나 가까운지 알아보기 위해 도입
Evaluation
1. AMT perceptual studies
- 참가자들에게 Real image와 Fake image를 함께 보여주고 더욱 진짜 같은 것을 고르게 하는 실험
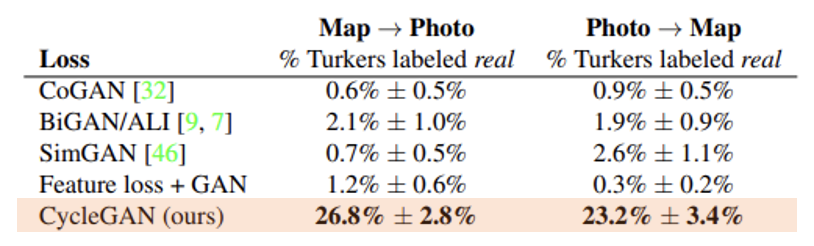
2. FCN scores
- 생성된 image로부터 label을 추측하는 Fully-convolutional network를 이용한 정확성 검증
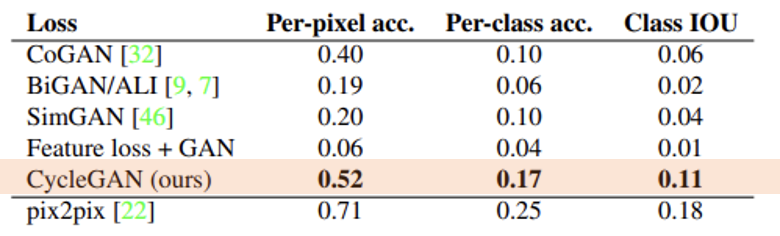
Loss의 부분집합들에 대한 FCN scores
- Cycle GAN에 쓰이는 Adversarial loss, Cycle consistency loss가 모두 있어야 하는 근거를 제시하기 위해 시행
- 라벨을 실제 사진처럼 변환했을 때와 그 반대 경우에 대해 실험

- 왼쪽 케이스에서 Adversarial Loss와 Forward cycle Loss만을 적용했을 때가 가장 진짜 같았지만, Backward 방향의 cycle loss가 학습되지 않기 때문에 오른쪽 케이스에서는 3순위를 차지함
- 오른쪽 케이스에서 Adversarial Loss만 적용했을 때 2순위로 나쁘지 않은 정확도가 나왔지만 왼쪽 케이스에서는 3순위에 머무름
이처럼 어느 하나의 loss라도 적용하지 않았을 때 특정 mode에서 성능이 나빠지는 mode collapse가 일어났고, 결국 두 케이스를 함께 보았을 때 가장 정확한 결과가 나온 것은 모든 Loss를 적용한 경우이다.
5. Application
Collection style transfer
- 화가의 예술 작품들로 데이터셋을 구축해 화풍을 학습하면 마치 화가가 그린 것 같은 image로 변환할 수 있다

모네, 반 고흐 등등 화가들의 과거 작품들을 학습해 그들의 화풍을 따서 마치 그들이 그린 것 같은 이미지를 만들어 낼 수 있다. 반대로 그들의 그림을 실제 이미지처럼 만들어낼 수도 있다.
Object transfiguration
- 유사한 두 object의 특징을 학습해 image 속 하나의 object를 다른 object로 변환할 수 있다

6. Limitation

- Input image에 대해 최소한의 변화만 만들 수 있다 (geometric change는 대부분 실패)
- 2종류의 데이터셋으로만 학습할 수 있다 (ex: 흑발, 금발, 백발 간의 학습은 불가능)
