
1. Introduction
최근 GAN의 동향
- 생성 이미지의 quality가 좋아짐
- 학습 과정이 안정됨
- 여러 이미지 처리 작업이 가능해짐
(ex : 얼굴 특징 변환, 고해상도 변환, 이미지 상호 변환)
한가지 문제점은, 이미지 처리 작업의 종류에 따라 특별한 네트워크 구조와 비용 함수를 쓰기 때문에 일반화하기 어렵다는 것이다.
Large-scale GAN models
- 수백만개의 이미지로 학습한 뒤 실제 같은 이미지를 생성할 수 있다
- 신경망이 데이터의 다양한 의미론적 특징들을 학습한다
- 대표적인 예시로 StyleGAN, BigGAN이 있다
연구진은 Large-scale GAN을 재사용해 이 문제를 해결하고자 했지만, GAN은 랜덤 노이즈로부터 이미지를 생성하기 때문에 이미지를 인풋으로 넣어 조작하는 것에 적합하지 않다.
이미지를 latent code로 invert하면 이 문제를 해결할 수 있지만 현존하는 방법들은 이미지를 복구했을 때 quality가 낮으며 single latent code로는 이미지의 세부적인 특징을 학습하기 어렵다는 한계가 있다.
따라서 연구진은 여러개의 latent code를 사용하고, feature composition이라는 개념을 도입해 모든 생성과정을 invert해 퀄리티를 높이는 연구를 진행했다.
Key Point
- multiple latent code와 Adaptive channel importance를 이용한 효과적인 GAN inversion
- 다양한 이미지 처리 분야에 적용 가능한 mGANprior
ex) 이미지 채색, 고해상도 변환, 이미지 복구, 얼굴 특징 변환 - GAN generator의 layer마다 feature composition을 해보면서 어떤 특징을 표현하는지 분석
Related Work
GAN Inversion
- Gradient Descent로 를 만족하는 latent code를 찾는다.
- 새로운 Encoder를 만들어 를 만족하도록 학습시킨다.
하지만 기존의 방법은 단일 latent code를 사용했을 경우만을 고려한다는 단점이 있다.
반면 본 논문은 더 나아가 여러 개의 latent code의 상황에서 inversion하는 방법을 소개한다.
Image processing with GANs

- 많은 발전을 이루어 더욱 진짜 같은 이미지를 생성해낼 수 있게 되었다.
- 노이즈 제거, 이미지 복구, Style 합성 등등 다양한 이미지 처리 작업에 사용된다.
하지만 현재는 이미지 처리 작업의 종류마다 특화된 네트워크 구조와 비용 함수를 쓰며, 학습할 때도 의도한 목적과 관련된 이미지셋을 이용한다는 단점이 있다.
반면 본 논문은 이미 학습이 완료된 GAN모델을 재사용하고 다양한 이미지 처리 작업에 적용할 수 있다.
Deep Model Prior
- 대규모의 데이터로부터 통계적 정보를 얻어낼 수 있는 능력을 갖추었다.
- Deep model들을 invert하여 semantic image transformation, 이미지 복구 등에 활용할 수 있다.
기존의 기술은 중간층의 feature space까지만을 invert했기 때문에 이미지 채색, 고해상도 변환과 같이 이미지에 전체적인 변화를 가하는 것에 실패했다.
반면 본 논문은 모든 Generation과정 (Image space ~ latent space)을 invert할 수 있어 더욱 유연한 이미지 처리가 가능하게 되었다.
3. Implementation
Feature Composition
다음은 연구진이 가진 궁금증과 그에 대해 마련한 해답이다.
Q. 여러개의 latent code를 Generation과정에 어떻게 통합시킬까?
- Image space 𝒳는 linear하지 않기 때문에 단순히 각각의 에서 생성된 이미지를 융합하는 것은 낮은 성능을 보인다
- 이전 연구에서 Image space부터 feature space까지가 Image space부터 latent space까지보다 invert하기 쉽다는 것이 밝혀졌다.
A. Latent code 각각의 intermediate feature map들을 결합한다.
- feature map을 결합할 Generator의 layer index ℓ을 선택한다.
- 이미 학습된 Generator 를 와 로 분리한다.
- 결합에 사용될 feature map들을 로 얻을 수 있다.
Adaptive Channel Importance
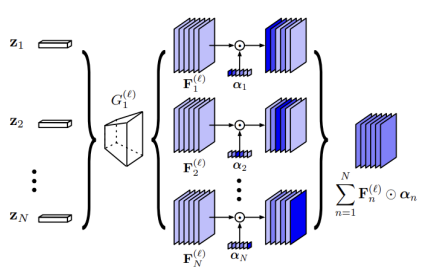
Goal : 각각의 이 이미지의 특정 부분을 복구할 수 있다.
: feature map 의 각 channel이 갖는 중요도
Optimize Objective
- 인풋 이미지 와 invert시킨 뒤 재구성한 이미지 간의 Loss를 최소화하는 파라미터들을 찾는다.
- pixel-wise error와 함께 perceptual feature간의 distance도 사용하여이미지 재구성의 Quality를 높인다.
Task-specific Loss Function
Image Colorization Task

- 재구성한 이미지의 gray channel을 뽑아낸 이미지가 인풋으로 받은 grayscale 이미지와 동일해야 한다.
Image Super-resolution Task

- 재구성한 이미지를 downsampling해서 해상도를 낮춘 이미지가 인풋으로 받은 저해상도 이미지와 동일해야 한다.
Image Inpainting Task

- 재구성한 이미지를 masking한 것과 인풋으로 받은 손상된 이미지가 동일해야 한다. (이때, 둘은 같은 binary mask를 사용한다.)
4. Experiments
비교 모델
PGGAN
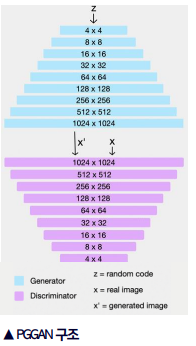
- Generator와 Discriminator를 점진적으로 키워 나가며 학습한다.
- 처음에는 저해상도에서 학습을 진행하지만 점차 고해상도의 이미지를 생성할 수 있게 된다.
- 저해상도에서만 알 수 있는 특징(ex: 얼굴 형태)과 고해상도에서만 알 수 있는 특징(ex: 머리카락, 눈, 코, 입)을 모두 학습할 수 있다.
- 비교적 안정적인 학습이 가능하다.
StyleGAN
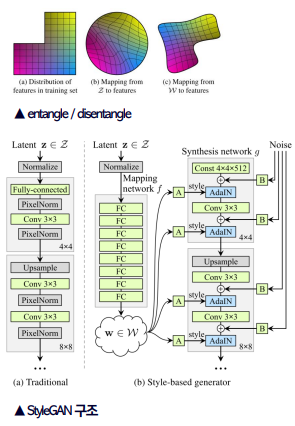
- PGGAN을 Base model로 사용한다.
- latent vector 를 Mapping network에 통과시킨 non-linear vector 를 이용하기 때문에 disentangle하게 되어 이미지 생성시 특징을 더 용이하게 조정할 수 있다.
- 합성 네트워크의 매 layer마다 AdaIN기법으로 정규화된 style을 입힌다.
다른 Inversion Method와의 비교 실험
실험 대상
- 단일 latent code를 최적화하는 방법
- 새로운 encoder를 학습하는 방법
- 이 둘을 합쳐 encoder에서 나온 값을 최적화의 초기값으로 설정하는 방법
- mGANprior (본 논문의 기법)
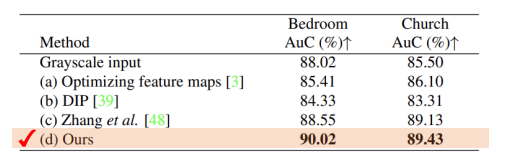
Quantitative comparison
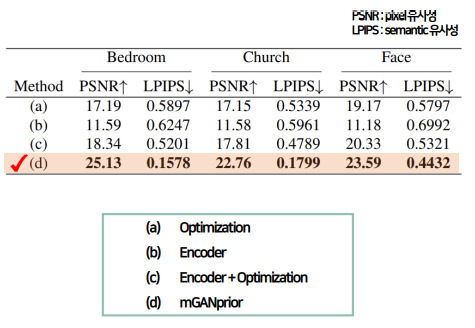
Bedroom, Church, Face 사진을 재생성한 모든 지표에서 mGANprior가 가장 우수하다.
Qualitative comparison
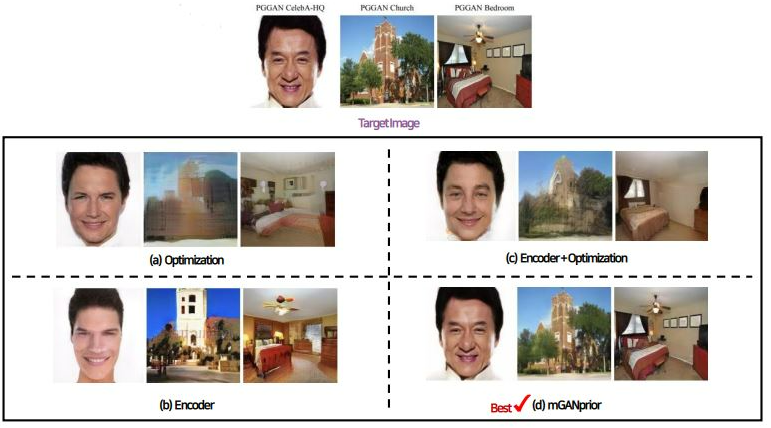
기존의 방법들은 타겟 이미지를 잘 복구해내지 못했으며 특히 사람 얼굴의 경우에는 완전히 다른 사람의 얼굴로 복구된다.
반면 mGANprior는 원본과 이질감이 느껴지지 않을 정도로 높은 퀄리티로 복구된다.
Analysis on Inverted Codes
(1) Latent Code의 개수
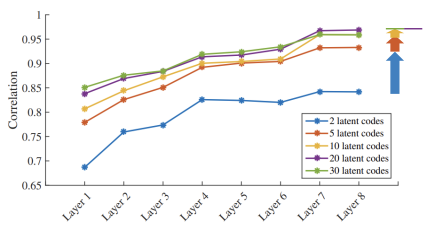
Latent Code의 개수가 늘어날 수록 성능이 높아지지만 점점 그 상승폭이 줄어드는 것을 확인할 수 있다.
(2) Composition을 시행하는 layer
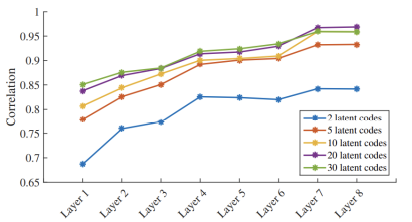
더 높은 layer에서 feature composition을 시행할 수록 성능이 좋아지는 것을 확인할 수 있다.
(3) 각 Latent Code의 역할
실험 방법
- 의 element 중 0.2보다 큰 값을 0으로 초기화하여 을 만든다.
- 과 의 difference map을 계산한다.
(∴ 의 element 중 0.2보다 큰 값들만 남게 된다.)- Segmentation model의 도움으로 Target Image를 세그멘테이션한다.
- Difference map과 Segmentation이 겹치는 정도를 측정하는 IoUmetric으로 어떤 semantic을 학습하는지 도출한다.
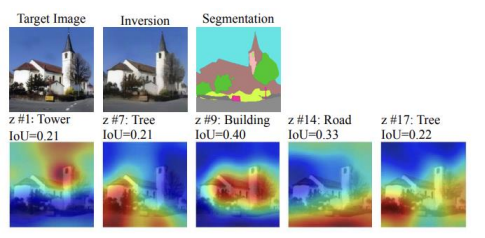
각 latent code마다 서로 다른 semantic을 표현한다는 것을 확인할 수 있다.
Image Processing Applications
(1) Image Colorization

- Discriminative 모델을 prior로 이용하는 (b) DIP는 High-level semantic (ex : 얼굴 형태)에 특화되어 있기 때문에 Low-level semantic (ex : 가장자리선, 색깔)을 이용해야 하는 상황에 취약하다.
- Image Colorization을 목적으로 만들어진 (c)모델보다 특별한 목적이 없는 (d)mGANprior모델이 더 좋은 성능을 보이는 것을 확인할 수 있다.
(2) Image Super-Resolution
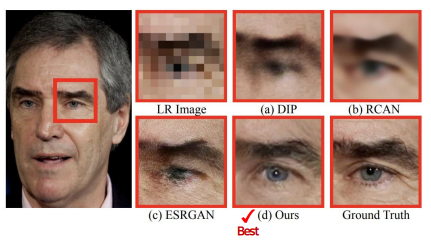
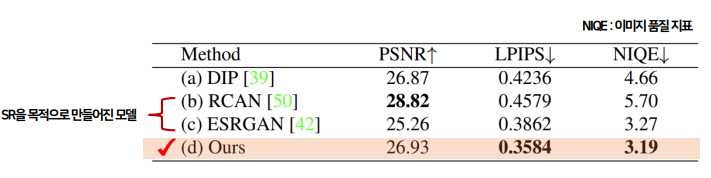
Super-Resolution을 목적으로 만들어진 모델 (b),(c)보다 특별한 목적이 없는 mGANprior 모델 (d)가 전체적으로 보았을 때 더 좋은 성능을 보이는 것을 확인할 수 있다.
Single vs Multiple latent code
Single latent code로 학습

- 이미지의 semantic을 표현할 수 있는 능력이 제한되어 있어서 test 이미지와 train 이미지가 다른 domain을 나타낼 때 잘 복구하지 못했다.
- 타겟 이미지는 침실인데 사람얼굴, 성당, 회의실 데이터로 학습한 모델들은 침실에 대한 semantic을 몰라 자신이 학습한 semantic으로 표현한 것을 볼 수 있다.
- 침실로 학습한 모델도 침실처럼 보이기는 하지만 타겟 이미지와는 완전히 다른 이미지를 생성했습니다.
Multiple latent code로 학습

- 같은 데이터셋으로 학습한 모델은 4번째 layer만으로도 거의 완벽하게 타겟 이미지를 복구한다.
- 이것은 Generator의 낮은 layer에서 high-level의 추상적 의미를 학습하기 때문으로 볼 수 있다.
- 학습된 침실 semantic을 재사용해 타겟 이미지를 복구하는 것에 이용할 수 있어 4번째의 다소 낮은 layer만으로도 충분했기 때문이다.
- Image inpainting처럼 이미지의 semantic을 알아야 해결할 수 있는 작업에는 이처럼 낮은 층의 layer가 사용된다.

- 다른 데이터셋으로 학습한 모델은 8번째 layer까지 들어가야 완벽히 타겟 이미지를 복구한다.
- 이것은 Generator의 높은 layer에서 low-level의 픽셀 단위 semantic을 학습하기 때문으로 볼 수 있다.
- 이 모델들이 학습에 이용한 데이터에는 침실에 대한 정보가 없기 때문에 낮은 layer에 있는 high-level semantic을 재사용할 수 없고 따라서 타겟 이미지의 semantic을 알아내기보다는 테두리 선을 따라그리고 똑같은 색깔을 칠하는 것에 집중하기 위해 높은 layer를 사용해야 한다.
- Image colorization처럼 이미지의 semantic보다는 픽셀 단위의 정보가 중요한 작업에는 이처럼 높은 층의 layer가 사용된다.
5. Conclusion
성능적 측면
- 여러 개의 latent code를 이용해서 더 많은 semantic을 학습할 수 있다.
일반화적 측면
- pretrained GAN model 사용에 특별한 제약이 없다.
- 다양한 이미지 처리 분야에 적용 가능하다.
(ex : inpainting, colorization)
발전 가능성
- 학습된 GAN을 재사용하므로 GAN이 발전할 수록 더 좋은 성능의 mGANprior를 만들 수 있다.
