
🎈Introduction
SGD는 각 훈련 step마다 mini-batch 를 이용해 Gradient를 계산하는데, 이는 다음과 같은 장점을 가짐으로써 Deep Neural Network 학습에 효과적인 방법을 제시했다.
- mini-batch의 gradient는 전체 데이터셋의 gradient에 근사한다.
(batch size가 커질수록 더욱 근사한다) - 요즘에는 병렬화 연산이 잘 구현되어 있기 때문에 각 샘플에 대해 m번 연산을 진행하는 것보다 mini-batch 전체에 대한 연산이 훨씬 빠르다.
이처럼 SGD는 간단하고 효과적이지만 다음과 같은 단점을 지닌다.
- Hyper parameter(학습률, 모델의 파라미터 초기값) 튜닝에 신중을 가해야 한다.
- 학습 도중에 layer 파라미터들이 변하면서 다음 layer 인풋의 분포가 바뀌어 학습을 어렵게 한다.
(파라미터에 작은 변화가 있더라도 네트워크가 깊어지면서 증폭된다)
특히, 두번째 단점을 Internal Covariate Shift라고 부르는데, layer 인풋의 분포가 바뀌면 layer는 또다시 새로운 분포에 적응해야 하기 때문에 학습에 좋지 않은 영향을 미친다.
연구진은 이러한 현상을 제거해 학습의 속도를 향상시키기 위해 Batch Normalization이라는 정규화 기법을 제안한다.
Batch Normalization은 다음과 같은 특징을 갖는다.
- 레이어 인풋의 평균과 분산을 고정한다.
- 기울기가 파라미터의 크기나 초기값에 받는 영향을 줄여 높은 학습률이 적용 가능하다.
- Regularization 효과가 있어 Dropout을 사용하지 않아도 된다.
- 더 많은 비선형 인풋들을 유지할 수 있게 되어 네트워크가 포화 상태에 빠지지 않게 된다.
🧵Towards Reducing Internal Covariate Shift
정규화 과정이 모델의 최적화와 결합되면 gradient descent의 효과가 상쇄되는 문제가 발생할 수 있다.
다음 예시는 이를 보여준다.
Gradient descent가 에 대한 의 의존도를 고려하지 않은 채 로 업데이트를 진행하면 다음과 같아진다.
결국, 출력값에 어떠한 변화도 없이 파라미터 만 무한히 커지게 된다.
이러한 문제는 모델 파라미터의 Gradient가 정규화를 설명할 수 있게 함으로써 해결할 수 있다.
정규화는 이제 현재 샘플 뿐만 아니라 모든 샘플 를 참고해 시행된다.
역전파 단계에서는 다음의 두 Jacobian을 모두 고려해야 한다.
하지만 레이어에 Whitening을 진행하기 위해서는 전체 인풋의 공분산 행렬과 그 역행렬 제곱근, 그리고 이들의 미분값을 계산해야 하기 때문에 굉장히 많은 비용이 든다.
( Whitening은 공분산 행렬을 이용해 입력 데이터의 각 feature가 서로 독립적이도록 변환한다 )
따라서 연구진은 이에 대한 대안을 찾아보게 되었다.
🎨Normalization via Mini-batch Statistics
각 layer의 인풋들을 모두 whitening하는 것에는 너무 많은 비용이 들며 미분 가능하지 않을 수 있기 때문에 연구진은 다음과 같은 단순화를 적용했다.
◼ Layer의 입력, 출력 feature를 동시에 whitening하는 대신 각각을 독립적으로 정규화한다.
단순히 레이어를 정규화하는 것은 레이어의 표현력을 감소시킬 수 있다.
예를 들어, 시그모이드 함수를 정규화하면 중앙의 선형 함수 부분만 남아 비선형성이 제거된다.
이를 해결하기 위해 연구진은 , 파라미터를 도입해 필요한 경우 정규화된 값이 원래대로 복원될 수 있도록 했다.
◼ 전체 데이터셋을 이용하는 대신 mini-batch의 평균과 분산을 이용해 정규화한다.
Whitening은 전체 데이터셋을 이용하고, 전체 Feature의 평균과 공분산을 구해 비용이 많이 들지만,
Batch Normalization은 mini-batch의 평균과 분산을 구하고 각 feature마다 정규화를 진행하므로 비용이 적게 든다.
다음은 배치 정규화 변환 알고리즘이다.

위 식에서 은 분모가 0이 되는 것을 방지하기 위한 것이다.
정규화된 값 는 을 무시했을때 평균 0, 분산 1의 분포를 갖는다.
모든 하위 네트워크들이 고정된 평균과 분산의 분포를 가지면 전체 네트워크의 학습이 가속된다.
훈련 시에는 역전파를 실시해야 하므로 BN 변환은 미분 가능해야 한다.
위의 수식은 BN 변환은 미분 가능한 변환임을 증명한다.
🧨Training and Inference with Batch-Normalized Networks
다음은 정규화 공식이다.
을 제외하면, 정규화된 입력값들은 평균 0, 분산 1의 분포를 갖게 된다.
이때, unbiased variance를 도출하기 위해 를 사용한다.
추론 시에는 평균과 분산이 고정되기 때문에 정규화는 각 활성화함수 이후에 적용되는 선형 변환이다.
추후 배치 정규화 대신 단순 선형 변환이 적용될 수 있도록 파라미터가 이용된다.
다음은 배치 정규화 알고리즘이다.

🧩Batch-Normalized Convolutional Network
다음과 같은 transform을 가정해보자.
연구진은 비선형 함수에 입력되는 를 배치 정규화시킨다.
를 정규화하지 않는 이유는, 가 이전의 비선형 함수의 출력값일 것이기 때문에 학습 도중 분포의 모양이 바뀔 수 있기 때문이다.
배치 정규화를 컨볼루션 신경망에 적용할 때, 연구진은 컨볼루션의 성질이 여전히 지켜져 Feature map의 서로 다른 위치에 놓여 있는 요소들이 같은 방향으로 정규화되기를 바랐다.
따라서 Feature map의 모든 위치에 놓여 있는 값들을 함께 정규화하는 방법을 택했다.
🧶Batch Normalization enables higher learning rate
이전의 깊은 네트워크에서는 학습률이 크면 Grdaient가 너무 커지거나 없어지고 local minima에 빠지는 문제가 있었다.
하지만 Batch Normalization은 활성화 값들을 정규화해 파라미터의 작은 변화가 활성화 함수 Gradient 값의 큰 변화로 이어지는 것을 방지함으로써 이러한 문제를 방지한다.
배치 정규화를 시행하면 역전파시에 파라미터의 크기에 영향을 받지 않아 모델의 학습 안정성을 증가시킨다.
이를 수식으로 보이면 다음과 같다.
추가로, Weight가 커지면 Gradient가 작아지는 효과가 있어 파라미터 학습을 안정화시킨다.
연구진은 배치 정규화는 layer Jacobian이 1에 근접한 Singular value를 갖게 해 학습이 잘되게 하는 효과를 가진다고 추론하는데, 그 근거는 다음과 같다.
- 두 연속된 layer가 각각 Gaussian 분포를 가지고 uncorrelated되어 있으며, 이들 간의 관계가 선형 변환이라고 가정하자.
- 그럼, 두 layer의 입력값은 단위 공분산을 가지기 때문에 다음과 같은 공식이 성립한다.
- 따라서 Jacobian의 모든 singular value가 1이 되고 이는 역전파 시에 Gradient의 크기를 보존하므로 학습에 도움이 된다.
🎐Batch Normalization regularizes the model
연구진은 배치 정규화를 적용해 학습한 훈련 예제들에서 모델이 결정론적이지 않고 다양한 값을 출력하는 것을 보았다.
이에 배치 정규화가 모델을 일반화시키는 효과가 있으며, 다른 Regularization 기법인 Dropout을 사용하지 않거나 강도를 줄여도 된다고 추론했다.
🥽Experiments
⚾ Activations over time
이 실험에서는 MNIST 데이터셋을 이용하여, Batch Normalization이 내부 공변량 변화(Internal Covariate Shift)에 미치는 영향과 학습 성능에 대해 검증하였다.
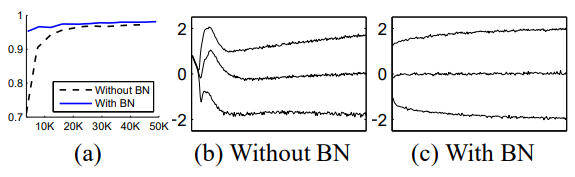
(a) 그래프
Batch Normalization을 사용했을 때와 사용하지 않았을 때의 테스트 정확도(Test Accuracy)를 학습 단계(step)별로 나타낸 것이다.
그래프를 보면 Batch Normalization을 사용할 때 더 높은 정확도를 얻을 수 있고, 더 빠르게 학습됨을 확인할 수 있다.
(b, c) 그래프
시그모이드 함수의 입력 분포를 나타낸 것으로, 학습 단계(step)별로 15번째, 50번째, 85번째 백분위수(percentile)에서의 입력 분포를 그래프로 그렸다.
Batch Normalization을 사용하지 않을 때는 학습이 진행됨에 따라 입력 분포가 매우 큰 폭으로 변화하는 것을 볼 수 있다. 이러한 변화가 내부 공변량 변화(Internal Covariate Shift)를 발생시키고, 학습을 어렵게 만드는 요인이다.
하지만 Batch Normalization을 사용하면 입력 분포가 안정적으로 유지되면서, 학습이 원활하게 진행되는 것을 볼 수 있다.
🥎 ImageNet classification
이 실험에서는 Batch Normalization이 Inception network에 적용될 때의 성능을 평가하였다.
ImageNet classification task로 학습된 Inception 모델을 사용했으며, 비선형 함수의 입력값들에 대해 Convolution 방법의 배치 정규화를 진행했다.
연구진은 여러 가지 Inception 모델의 변형에 대해 배치 정규화를 적용하였고,
학습 중에 Validation accuracy @1을 계산하여 성능을 평가하였다.
연구진은 배치 정규화를 적용한 모델의 성능을 높이기 위해 특정 모델들에 다음과 같은 수정사항을 적용시켰다.
- 더 높은 학습률 사용
- Dropout 제거
- 더 작은 L2 Weight Regularization 상수 사용
- Learning rate decay 가속화
- LRN 정규화 제거
- 더 철저히 훈련 예제 뒤섞기
- 광학 왜곡 정규화 제거
Single-Network Classification
본 실험에서는 LSVRC2012 학습 데이터로 학습된 다음의 네 가지 네트워크를 평가하였다.
- Inception: 초기 학습률 0.0015로 학습된 Baseline 모델
- BN-Baseline: 모든 비선형 함수 이전에 배치 정규화가 추가된 인셉션 모델
- BN-x5: 초기 학습률이 0.0075로 5배 증가되었고 위의 수정사항이 적용된 Modified 인셉션 모델
- BN-x30: 초기 학습률이 0.045 (Inception의 30배)인 Modified 인셉션 모델
- BN-x5-Sigmoid:비선형성 함수로 ReLU 대신 시그모이드 함수를 사용한 Modified 인셉션 모델
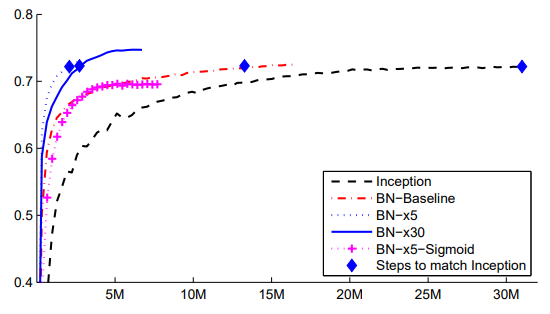
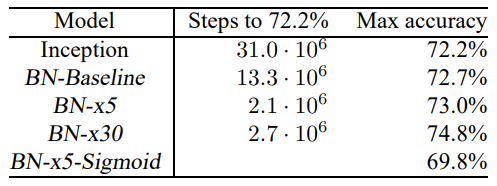
Inception은 30M step의 학습으로 72.2%의 정확도를 달성했는데, BN-Baseline은 절반 가량의 step만으로 같은 정확도를 달성했다.
Modify된 모델들은 훨씬 빠른 학습 속도를 보여주었는데, BN-x5는 Inception보다 14배 적은 step으로 72.2%의 정확도를 달성했으며 BN-x30은 Inception보다 5배 적은 단계로 72.2%의 정확도에 도달했다.
주목할 점은 학습률을 더 높이면 (BN-x30), 모델이 처음에는 조금 더 느리게 학습되지만 최종적으로 더 높은 정확도에 도달했다는 것이다.
Ensemble Classification
현재 ImageNet-LSVRC에서 가장 최고 성능을 달성한 것은 전통적인 모델의 Deep Image 앙상블(Wu et al., 2015)과 (He et al., 2015)의 앙상블 모델이다.
특히 후자는 4.94%의 top-5 error를 보였는데, 연구진이 제안한 모델은 4.9%의 validation error, 4.82%의 test error를 가짐으로써 기존의 최고 성능을 뛰어넘는 결과를 보여주었다.
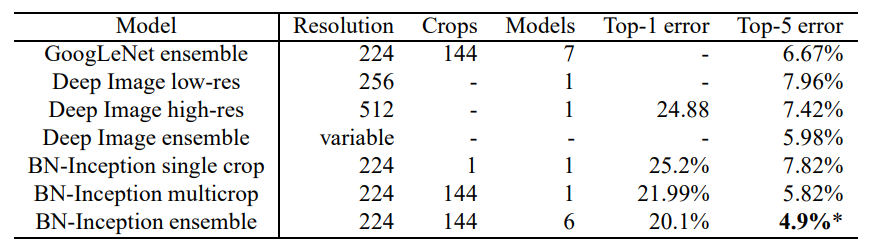
연구진은 위의 표를 근거로 배치 정규화로 ImageNet 분류 task들에서 새로운 SOTA를 달성할 수 있음을 주장한다.
📘 Conclusion
- 깊은 신경망의 학습을 크게 가속화할 수 있는 혁신적인 메커니즘
- 배치 정규화를 적용하면 이미지 분류 task에서 기존의 최고 성능을 능가하는 SOTA 달성 가능
- Standardization layer(Gülçehre & Bengio, 2013)와 유사하지만, 적용되는 위치와 기타 세부적인 기술(Scale/Shift 파라미터, 컨볼루션 층에 적용 가능, Regularization 효과)에 차이가 있음
- Invariate Covariate Shift와 Gradient Vanishing이 특히 심각한 RNN에의 적용 가능성과 같이 응용 분야 탐색 및 더 깊은 이론적 연구의 필요성이 있음
