Adsp 준비 (4)
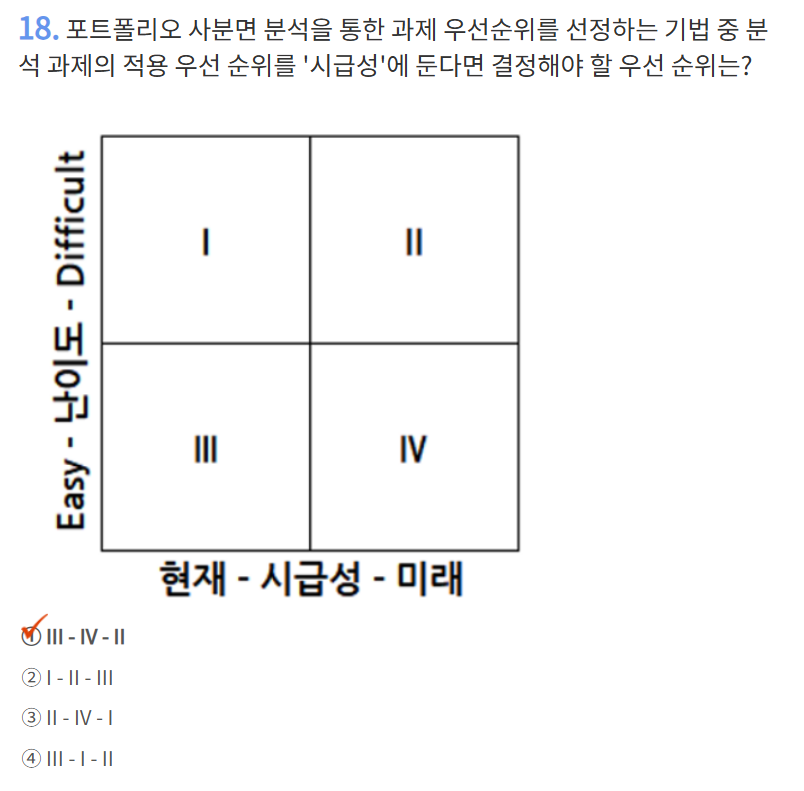
시급성 : 3→4→2
난이도 : 3→1→2
연관규칙 학습 -> 장바구니 분석, 상품추천
유형분석 -> 그룹, 분류
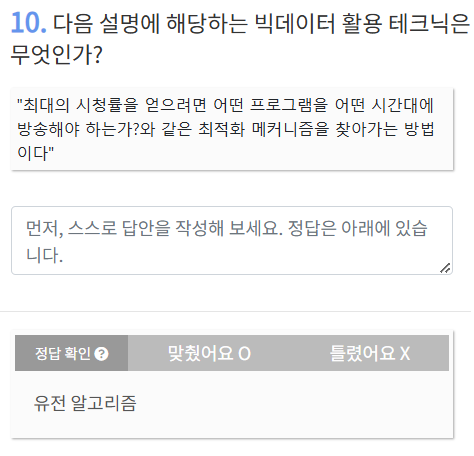
유전알고리즘 -> 최적화, 최선의 배치
기계학습==머신러닝 -> 스팸메일 필터링, 넷플 추천 시스템
회귀분석 -> 인과관계로 설명하려 듬
감정분석 -> 텍스트에서 분노가 느껴짐
소셜 네트워크분석 -> 인스타 관종 찾기, SNS 미디어 활용해서 원하는 정보찾기

준비형 : 낮은 준비도, 낮은 성숙도
정착형 : 낮은 준비도, 높은 성숙도
도입형 : 높은 준비도, 낮은 성숙도
확산형 : 높은 준비도, 높은 성숙도


이상치를 제거해야지 상관계수를 제거하면 안됨

지지도 : A,B 동시 거래된 수 / 전체 거래수
신뢰도 : A,B 동시 거래된 수 / A 전체 거래수
향상도 : A,B 동시 거래된 수 X 전체 거래수 / A 전체 거래 수 X B 전체 거래 수

설명변수 = 독립변수
영향을 받는건 반응변수 = (종속변수)

원시 데이터 요약 -> 주성분 분석
거리 구조 -> 다차원 척도법

ARMA model - 자기회귀이동평균
ARMA(2.0)은 d=0이므로 AR(2)와 같다
AR(2)는 PACF는 3차 항부터 절단형태, ACF는 지수적 감소
MA(2)였다면 PACF는 지수적으로 감소, ACF는 3차 항부터 절단 형태를 보일 것이다
ARMA(2,0)은 정상 시계열이어서 분석용도로 사용할 수 있다
ARMA ARIMA 총정리
ARMA는 단순히 AR + MR이다.
ARIMA는 AR+MR에 차분요소인 D가 포함된 모델이다.
ARMA(2)라는 것은 ARMA(p,q)중 p = 2 인자만 있다는 것이고 그러면 AR(2)와 마찬가지이므로
PACF는 p+1(3) 항에서 절단형태고 ACF는 지수적으로 감소한다.
반대로 ARMA(0,3)일 경우를 가정해보자
이는 MA(3)과 같고 MA는 AR과 반대로 PACF가 지수적으로 감소하고 ACF가 q+1(4)항에서 절단형태를 띈다.
ARIMA의 경우 인자 순서가 (p,d,q)와 같다.
여기서 d는 차분 값을 말하는데 이를 간단한 예로 들자면
어떤 사람이 몸무게가 매일마다 1키로씩 는다고 해보자
60 61 62 63 으로 늘어날 때 여기서 차분을 하게 되면 현재 - 과거를 하면서 각 차이인
1 1 1 이 남게되는데 이렇게 하면 들쭉날쭉한 수치들을 평평하게 정리할 수 있게 된다. 이것이 차분이고 마치 잔디를 깎는 느낌으로 이해하면 된다. 이것은 정상성을 확보하게 해준다. (d차분 후) 그래서 ARMA와 달리 비정상 시계열인 ARIMA를 분석할 수 있게 해준다.


문자형 > 숫자형 > 논리형

잡음: 무작위한 변동, 원인 알려지지 않음

✅ Scree Plot(스크리 플롯)이란?
주성분 분석(PCA)에서 각 주성분이 얼마나 많은 정보를 설명하는지(=고유값)를
차례대로 선 그래프로 그려놓은 것입니다.
📌 쉽게 말해:
1번 주성분: 정보 많이 담고 있음
2번 주성분: 그 다음
… 점점 정보량이 줄어듦
→ 이 흐름을 그래프로 표현한 것이 Scree Plot입니다.
✅ 팔꿈치 지점(Elbow Point)이란?
그래프가 급격히 꺾이는 지점
→ 마치 팔꿈치처럼 툭 꺾여서 구부러지는 부분이에요.
📌 의미:
그 지점까지는 정보량이 많고 의미 있는 주성분
그 이후는 거의 쓸모 없는 잡음 수준
→ 그래서 그 꺾인 지점까지의 주성분만 사용합니다.

F통계량이 높을수록 내 모델이 그냥 평균으로 값 예측하는거 보다 낫다라는 의미
P값은 낮을수록 유의미한 데이터라는 소리 (우연이 아님)
Multiple R-squared가 높을수록 데이터를 잘 설명한다는 의미이며 이건 퍼센테이지로 매길 수 있음 0.9588이면 약 96%인게 맞음
그리고 Intercept 부분은 time이 0일때 무게의 시작값이다.그 뒤에 n*time이 계속 더해지면서 weight가 도출되는 것 그래서 1번은 맞고 시간이 늘어나면 weight은 7.9879만큼 늘어나는 거임.

최단 연결법 그림

회귀나무 vs 분류나무
회귀 나무: 연속형 변수(숫자)를 예측 (키,무게 등) 이때 분산,F통계량 사용
분류 나무: 범주형을 예측(합격/불합격, 음료/알콜 등) 이때 지니 지수, 카이 제곱, 엔트로피 사용

분석 기획(비즈니스, 프로젝트 계획) ->
데이터 준비(데이터) ->
데이터 분석(분석, 모델) ->
시스템 구현(시스템, 구현) ->
*평가 및 전개(평가, 발전)

크기(Volume), 다양성(Variety), 속도(Velocity)의 3V는 투자 비용(Investment) 측면의 요소
가치(Value)는 비지니스 효과(return) 요소

데이터 확보가 중요하긴 하나, 시나리오는 분석의 목적, 방법, 활용 방안을 다루는 것으로, 데이터 확보는 분석을 수행하는 과정에서 해결해야 함.
