Adsp 준비 (5)

SOM은 순전파 방식

연산이 단순하고 빠른 편
(지지도, 신뢰도, 향상도만 계산)
계산이 복잡한 분석 기법으로는
군집분석, 신경망, 의사결정트리+앙상블, SVM, 고차원 시계열 분석(ARIMA, LSTM)

회귀 계수(Estimate)의 부호가 양수면 양의 관계, 음수면 음의 관계
따라서, 등록금과 기숙사비의 경우 높아지면 졸업률도 오르고
개인비지출의 경우 높아지면 졸업률이 낮아짐
그리고 모든 변수의 P-Value가 0.05보다 작기 때문에 통계적으로 유의미한것

여기서 mu는 그리스 문자 "μ" (뮤)의 알파벳 표현
통계에서 μ (뮤)는 모집단의 평균값을 나타냄
그래서 t.test(Wage$wage, mu = 100) 이건
Wage데이터셋의 wage열을 가지고, 평균이 100이라는 주장을 검정하겠다는 의미임
그리고 여기서 보면 df는 2999가 맞고
유의수준이 0.05일 때 귀무가설이 기각되지 않는 다는 말은 아예 틀린말인데 애초에 P-value가 0.05 보다 작거나 같으면 귀무가설은 기각이 맞음 커야 귀무가설이 채택되는 것
그 다음 3번 대립 가설은- 부분을 보면 true mean이 의미하는 것이 wage의 mu이므로 wage의 평균은 100과 같지 않다가 해석한 내용과 동일함
마지막 95%신뢰구간에 점추정 값이 포함되어 있다는 부분의 경우 95 percent confidence interval이라고 되어있고 이 신뢰구간이 110.20098 <= x <= 113.1974이므로
점추정값인 mean of x는 111.7036으로 이 사이에 있어 4번이 맞는 설명이 되는 것이다.

Lasso 회귀는 변수가 많고 그 중에서 불필요한 변수가 많을 때 사용함. L1 norm을 사용해서 각 변수 계수의 절댓값의 합을 구하고 불필요한 변수를 0으로 만들어 제거함
Ridge 회귀는 모든 변수가 어느 정도 다 중요할 때 사용. L2 norm을 사용해서 계수들의 제곱합을 구하고 변수는 제거하지 않지만 값을 줄여서 과적합을 방지함.
Elastic Net이라는건 Lasso의 L1과 Ridge의 L2를 동시에 쓰는 건데 변수가 많을 때, 그 변수중에 상관된 변수가 많을 때 사용한다. L1의 변수 선택과 L2의 안정성을 동시에 가지는 것이다. 고차원 데이터에 효과적이다.
모형에 포함된 회귀계수의 절댓값이 클수록 Penalty가 부여된다? 이건 맞음 L1과 L2가 모두 그러한 방식을 취함. 대신, L1은 선형적으로 커지고 L2는 제곱으로 증가함.
공식을 보면 람다값이 계수로 각 페널티앞에 붙어서 정도를 조정하는게 맞고
그렇게 나온 결과로 변수선택을 하는 효과를 볼 수 있음.
L2 norm으로 페널티를 부여하는 방식은 Lasso가 아니라 Ridge방식이므로 4번이 틀렸음

스피어만: 선형, 비선형
피어슨 상관: 등간척도 비율척도 / 서열척도는 스피어만
피어슨 상관계수 0 이면 선형상관관계가 없음
스피어만 상관계수 0이면 단조성(일관된 방향)이 없음
공분산 측정단위에 영향을 받음

카이제곱검정은 모수/비모수 둘 다 존재
Runs Test는 데이터의 랜덤성 검정
Wilcoxon Signed Rank Test는 짝지어진 표본의 차이 비교
Sign Test는 중앙값 비교 (부호만 이용)

SNA 종류 -> 연근매워(위)

부호함수: x가 양수면 +1, 음수면 -1
계단함수: 불연속 함수로, 딥러닝에서 잘 안쓰임
시그모이드: X가 -무한대면 0에 가까워지고 +무한대면 1에 가까워지고 0이면 0.5이므로 0과 1사이에서 왔다갔다하는 시그모이드가 답
소프트맥스: 다중 클래스 분류에서 전체 출력 합을 1로 만듦
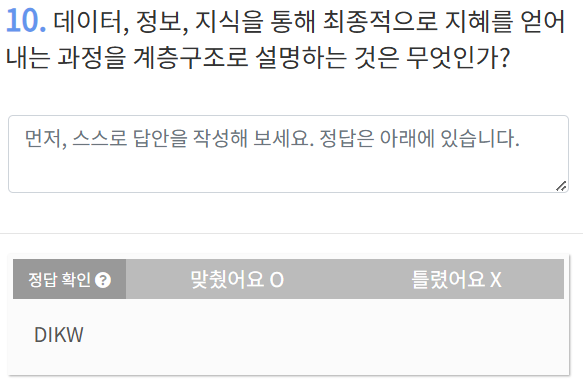
걍 외워둬

분류 -> 분석
식별 -> 정의
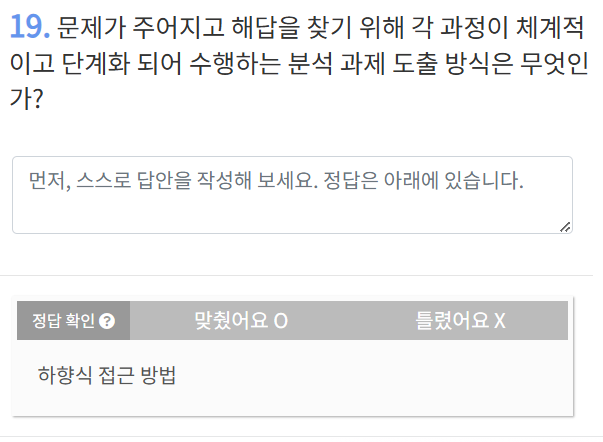
문제가 주어지면 하향식 ex) KPI
데이터가 주어지면 상향식 ex) 데이터 마이닝, 이상 탐지, 인사이트 발굴, EDA
여기서 EDA란? 데이터를 보고 감잡는 거
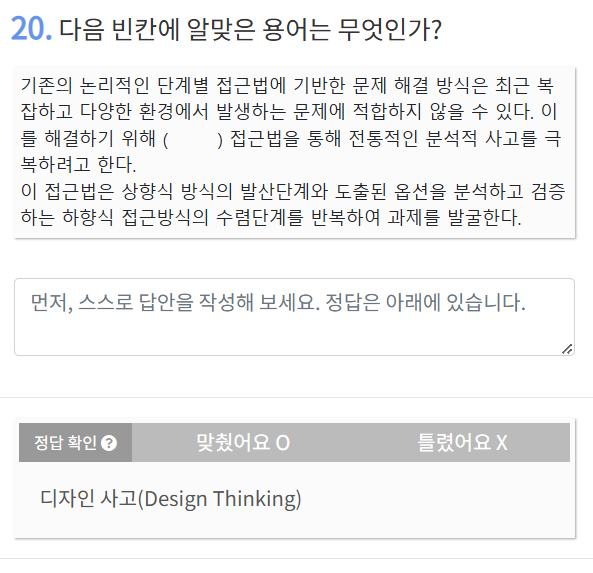
걍 외우셈
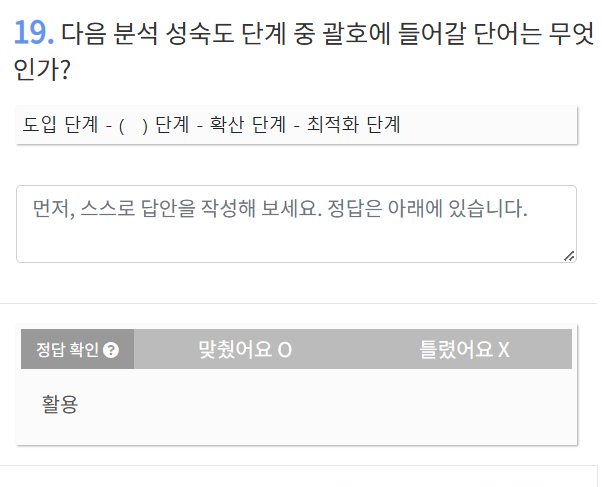
도둑질한 활어회 확 채(최)와

전진 선택법: 변수가 없는 상태에서 하나씩 추가
후진 제거법: 모든 변수를 다 넣고 하나씩 제거
단계별 선택법: 추가/제거를 반복적으로 동시에 수행
전선, 휴(후)제, 단선
Cp, AIC, BIC는 작을수록 좋다는 기준이 맞음
페널티같은 느낌으로 기억해 두셈

군집분석의 안정성검토는 실루엣,Duun INdex를 사용
애초에 비지도임 그리고
난 3번도 좀 이상하다고 생각했는데 DBSCAN같은거에서는 성립하지 않지만
K-means같은 알고리즘의 경우 이상치에 의해 군집의 구조가 왜곡될 가능성이 생겨버림

항등함수는 입력값을 그대로 출력
ReLU는 음수는 0으로 만들고 양수는 그대로 출력해서 단순하지만 속도가 빠르므로 은닉층에서 가장 많이 쓰이는 활성화 함수이다.
렐루 == 렐리루 == 감빡이 == 시청자
부정적인 말하면 블랙해서 0으로 만들고 좋은 말은 그대로 나가게 하는데 이게 방송 분위기를 좋게 만들어서 자금 은닉하는 세력들이 주로 사용하는 인방에서 사용

계통은 일정 간격마다 선택
층화는 층을 나눠서 무작위 선택
군집은 군집으로 나눠서 일부 군집만 모두 선택


은닉층 수와 노드의 수는 직접 설정해야 하면 은닉층이 많으면 역전파 과정에서 기울기 소실문제로 인해 가중치 조정이 되지않아 학습이 제대로 되지 않는다.
