
🕰️ MongoDB 시계열
⏳ MongoDB 시계열 데이터
시간의 흐름에 따라 발생하는 데이터 (주로 센서 데이터, 금융 데이터, 로그 데이터 등 다양한 형태로 존재)
이를 효율적으로 분석할 수 있도록 제공함 → 시간이 들어간 개념!
- 시간데이터 포인트가 기록된 구조
- 메타데이터는 시리즈를 고유하게 식별하는 레이블 또는 태그이며 거의 변경되지 않음
- 측정값시간 단위로 추적되는 데이터 요소
⌛️ MongoDB 시계열 컬렉션 (Time Series Collection)
시계열 데이터를 효율적으로 저장하고 쿼리하기 위해 설계된 특수한 컬렉션 유형
✔ 시계열 데이터를 효율적으로 저장하고 컨트롤하는 기능
✔ 동일한 출처의 데이터가 비슷한 시점의 다른 데이터 포인트와 함께 저장되도록 쓰기가 구성된다.
-
자동으로 생성된 클러스터형 인덱스를 사용 → 데이터를 time-series 순서로 저장
-
일반 컬렉션처럼 동작
-
MongoDB는 시계열 컬렉션을 내부 컬렉션에 의해 뒷받침되는 쓰기 가능한 비물질화 뷰로 취급
-
time-series 컬렉션에 대한 쿼리는 최적화된 내부 저장 형식 활용 → 속도가 아주 개선됨
특징
- 자동 인덱싱
- 스키마 : 타임 필드와 메타데이터 필드를 정의 → 구조화된 데이터 저장
- 데이터 압축 : 시간에 따라 유사한 데이터를 효율적으로 압축 → 저장 공간 절약
- 성능 최적화
⏰ 시계열 컬렉션 데이터 다루기
timeField와 metaField 필수 지정 → 데이터 삽입할 때에도 타임필드와 메타데이터를 포함하여 작성
조회 시 일반 컬렉션과 동일한 쿼리 사용, 집계 쿼리 사용해 분석 가능
-- 시계열 컬렉션 생성
db.createCollection("sensorData", {
timeseries: {
timeField: "timestamp",
metaField: "metadata",
granularity: "minutes"
}
});
-- 데이터 삽입
db.sensorData.insertMany([
{
timestamp: ISODate("~"),
metadata: { sensorId: 1, location: "Room1" },
temperature: 22.5,
...
},...
]);timeField- 시간 정보 저장metaField- 메타데이터 저장 (데이터 설명)granularity- 데이터의 시간 간격(optional)
⏱️ MongoDB 시계열 컬렉션 활용 기법
1. 적절한 데이터 모델링
-
timeField와 metaField를 효과적으로 사용하기 → 각각 타임스탬프와 데이터 출처를 식별하는 메타데이터로 정의하여 구조화하면 유사한 시계열 데이터가 함께 그룹화되어 저장된다
-
적절한 Granularity 설정 (seconds, minutes, hours) → 저장 공간과 쿼리 성능 최적화
2. 최적화된 인덱싱
- timeField와 metaField에 대한 자동 인덱싱 → 더 빠른 쿼리 지원, 쿼리 작성 시 이 인덱스가 적용된 필드를 활용
- 추가 인덱스 생성 가능, 하지만 인덱스는 성능에 영향을 주므로 신중하게 고려해서 사용
3. 효율적인 데이터 삽입
- Bulk Insert →
insertMany()로 일괄 삽입하며 오버헤드가 줄고 데이터가 최적화된 형태로 그룹화 되어 저장 - 타임스탬프 순으로 데이터를 정렬하여 삽입 → MongoDB 내부 스토리지 엔진이 순차적인 타임스탬프 정렬로 성능 이점
4. 쿼리 최적화
- 시간 범위 쿼리 → timeField에 대한 인덱스로 시간 기반 범위를 효율적으로 처리 가능
- 메타데이터 필터링 → 시간 범위 쿼리와 함께 메타데이터 필드를 결합하여 더 정밀한 결과, 인덱스된 metaField 성능 활용
5. 집계 분석
-
MongoDB의 집계 프레임워크는 시계열 데이터를 분석하는데 적합
-
.$group→ 특정 시간 창에 대한 평균, 합계 또는 개수 계산 -
버킷팅(Bucketing) →
$bucket또는$bucketAuto를 통해 데이터를 특정 간격으로 그룹화
6. 데이터 보존 및 아카이빙
- TTL 인덱스(Time-To-Live Indexes) → 특정 시간이 지난 시계열 데이터를 자동으로 삭제 후 공간 확보
db.temperatureReadings.createIndex({ timestamp: 1}, { expireAfterSeconds: 60 * 60 * 24 * 30 });- 데이터 아카이빙 전략 → 장기 보존이 필요한 경우, 오래된 데이터를 다른 컬렉션이나 외부 스토리지로 이동하는 전략 구현
🕰️ 실습
🤓 시계열 데이터 생성 및 조회
- 데이터베이스 만들기
use timeSeriesTestDB
- 시계열 컬렉션 생성하기
db.createCollection("environmentSensors", {
timeSeriese: {
timeField: "timestamp",
metaField: "sensorInfo",
granularity: "minutes"
}
});- nvironmentSensors`라는 이름으로 시계열 컬렉션을 생성한다.
- timeField 필수 선언 → "timestamp"
- metaField 필수 선언 → "sensorInfo"
- granularity: "minutes" → 분 단위 세분성 설정
* metaField 필드에 대해 동일한 고유 값을 가진 연속 수신 측정값 사이의 시간 범위와 가장 가까운 값으로 세분성을 설정합니다.
* 연속적으로 들어오는 타임스탬프 사이의 시간과 가장 근접하게 일치하는 값으로 granularity 를 설정합니다. 이렇게 하면 MongoDB가 컬렉션에 데이터를 저장하는 방법을 최적화하여 성능이 향상됩니다.
👉 이걸 왜 쓰는지 약간 이해가 잘... 안 갔는데 granularity를 설정하면 데이터를 저장하는 방식에서 최적화가 되는 것 같음 내부적으로 어떻게 작동하는지는 모르겠으나 ... 참고
- 데이터 삽입
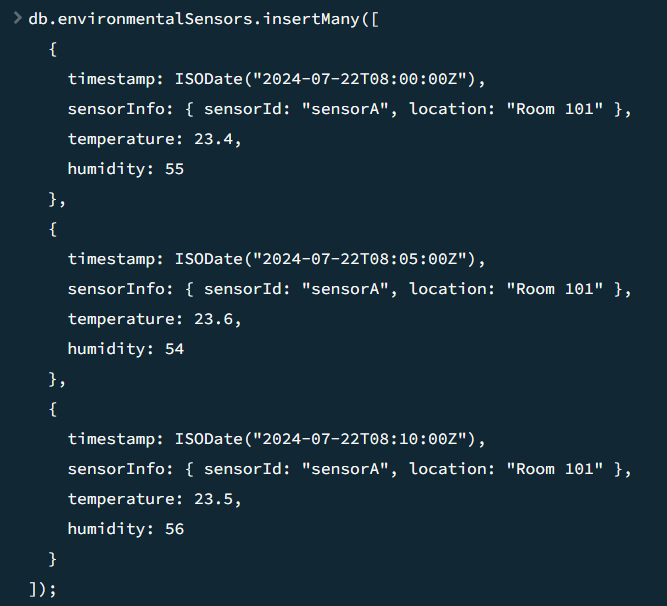
- timestamp → ISODate 데이터 타입으로 시간 정보 저장
- sensorInfo → 메타 데이터 정보
sensorId,location정보 저장 (자동 인덱싱) - 그 밖의 정보 →
temperature,humidity
- 데이터 조회
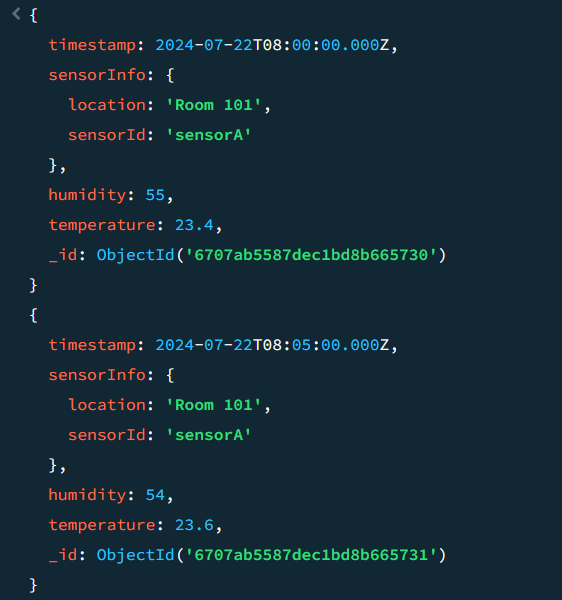
db.environmentSensors.find({
timestamp: {
$gte: ISODate("2024-07-22T08:00:00Z"),
$lt: ISODate("2024-07-22T08:10:00Z")
}
});timestamp 데이터가 2024-07-22T08:00:00Z 이상, 2024-07-22T08:10:00Z 미만인 정보를 조회한다
결과 화면
🤓 시계열 데이터 집계
- 시계열 컬렉션 생성
db.createCollection("stockPrices", {
timeseries: {
timeField: "timestamp",
metaField: "stockInfo",
granularity: "hours"
}
})- stockPrices 시계열 컬렉션 생성
- metaField : "stockInfo"
- granularity : "hours"
- 데이터 삽입
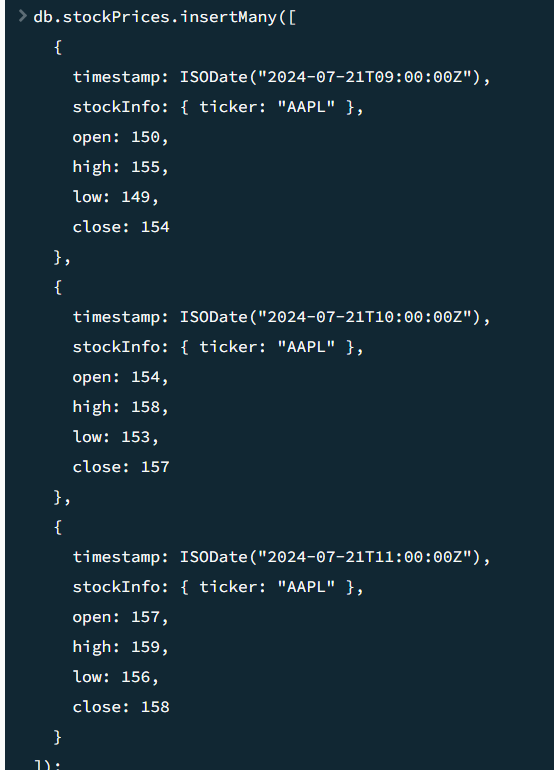
- metadata →
ticker
- 집계함수 사용
db.stockPrices.aggregate([
{
$match: {
timestamp: {
$gte: ISODate("2024-07-21T09:00:00Z"),
$lt: ISODate("2024-07-21T12:00:00Z")
}
}
},
{
$group: {
_id: "$stockInfo.ticker",
avgOpen: {$avg: "$open"},
avgClose: {$avg: "$close"}
}
}
])-
#1.
$match→ 지정된 쿼리 조건자를 기준으로 문서를 필터링
timestamp 기준으로 2024-07-21T09:00:00Z 이상, 2024-07-21T12:00:00Z 미만의 데이터를 필터링 해 다음 파이프라인으로 넘긴다 -
#2.
$group→ '그룹 키'에 따라 문서를 그룹으로 분리
그룹키 : stockInfo의 ticker를 기준으로 그룹을 분리한다
avgOpen :$avg함수로 그룹 내의$open데이터의 평균을 구한다
avgClose :$avg함수로 그룹 내의$close데이터의 평균을 구한다
결과 화면
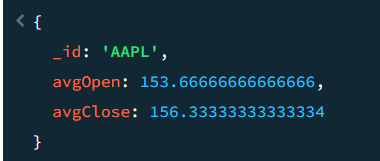
우리가 가진 데이터에서 stockInfo.ticker는 'AAPL' 값 밖에 없었기 때문에 AAPL 데이터 그룹 한 개만 출력된다. 아래는 평균값들!
🤓 시계열 데이터 조회 및 정렬, 제한
- 시계열 컬렉션 생성
db.createCollection("iotDeviceEvents", {
timeseries: {
timeField: "eventTime",
metaField: "deviceInfo",
granularity: "seconds"
}
})- iotDeviceEvents 라는 이름의 시계열 컬렉션 생성
- timeField는
eventTime이 되었다! - metaField에는
deviceInfo가 저장된다 - granularity는 seconds(초) 단위로 세분화
- 데이터 삽입
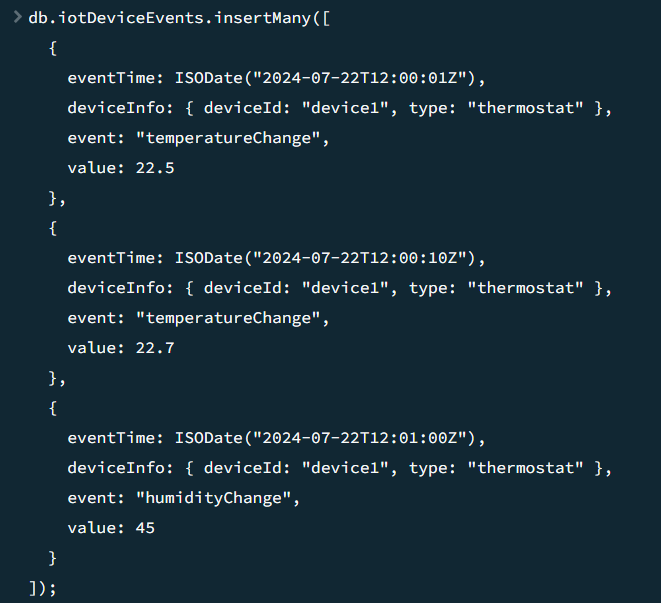
- 메타데이터(deviceInfo)는
deviceId와type으로 구성 - 그 밖의
event와value값으로 구성
- 데이터 조회
db.iotDeviceEvents.find({
"deviceInfo.deviceId": "device1"
}).sort({eventTime: -1}).limit(1)-
find()→ 문서를 선택하고 선택한 문서로 커서를 반환
deviceInfo의 deviceId가 "device1"인 문서를 선택하여 커서를 반환 -
sort()→ 정렬
eventTime 기준으로 내림차순 정렬 -
limit()→ 출력되는 데이터 수 제한 (1개)
결과 화면
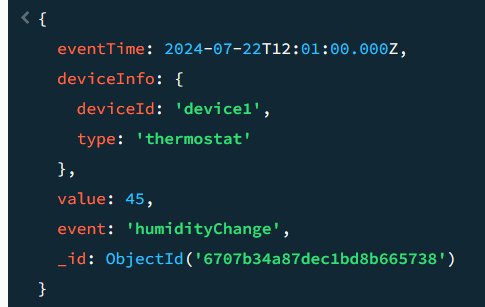
우리가 데이터 출력 개수를 하나로 제한했기 때문에 위와 같은 데이터가 출력된다
만약 limit() 함수를 제외한다면
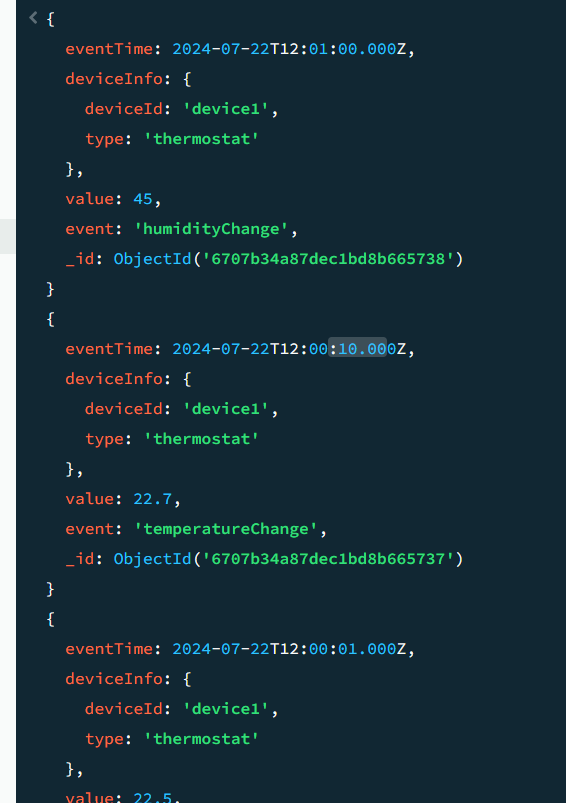
위와 같이 데이터가 정렬된다. 우리가 선택한 문서들 중 eventTime 기준 내림차순으로 정렬이 되었음을 알 수 있다.
느낀점
실습 문제를 다시 한 번씩 작성해보고 정리하다보니까... 뭔가 알 것 같기도...? 하지만 아직은... 혼자서 함 써봐! 하면 너무 어려울 것 같다... 흑흑 몽고디비 이상해 ㅠㅠ
본 포스팅은 글로벌소프트웨어캠퍼스와 교보DTS가 함께 진행하는 챌린지입니다
