
MongoDB로 실습을 몇 번 해보고 나니... NoSQL은 처음이라 걱정이 많았는데, 전 회사에서 시퀄라이즈로 MySQL 쿼리를 짰던 것과 유사해서 생각보다 수월했다. 그 때만 해도 쿼리문 작성하는 것이 훨씬 익숙해서 코드를 쓰는 것 처럼 sql문을 작성하는 것이 너무 어색하고 신기하면서도 조금 적응이 힘들었는데 그 경험이 여기서 도움이 될 줄이야 ^^... ORM에 익숙해서 이것도 눈에 꽤 익어서 좋았다. 하지만 아직은 정말 익숙하지 않은 문법이 많기 때문에... 공식 문서 Docs 매뉴얼를 보면서 하나씩 모르는 부분을 파헤쳐보기로 한다!
🐒 고급 쿼리
🌿 고급 쿼리 테스트 환경 구성
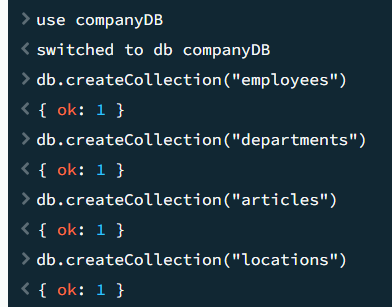
데이터베이스를 선택(없어도 알아서 생성해준다)한 후 (use 명령어)
컬렉션을 만든다 (db.createCollection)
employees, departments, articles, locations 컬렉션을 만들어주었다.
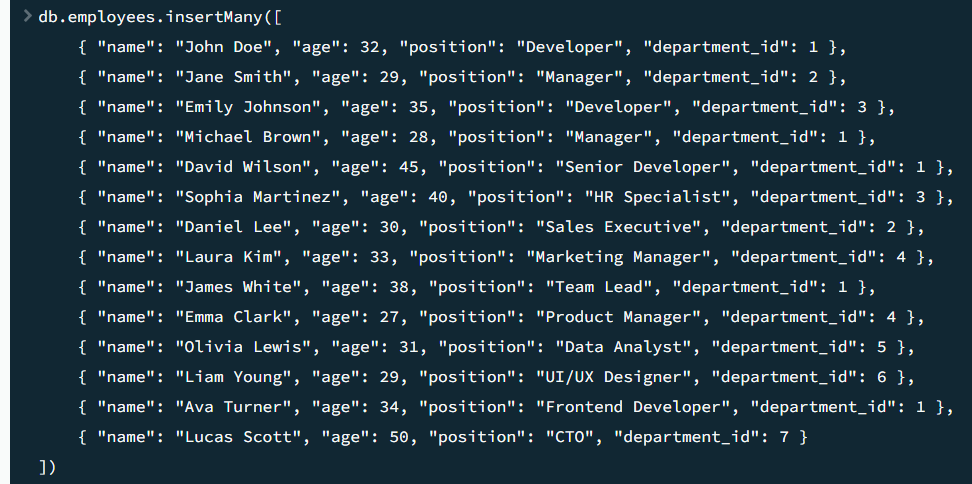
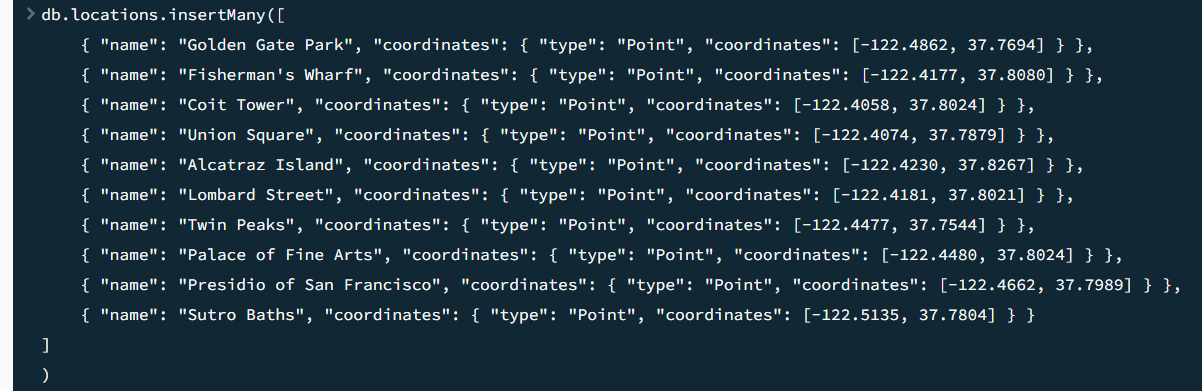
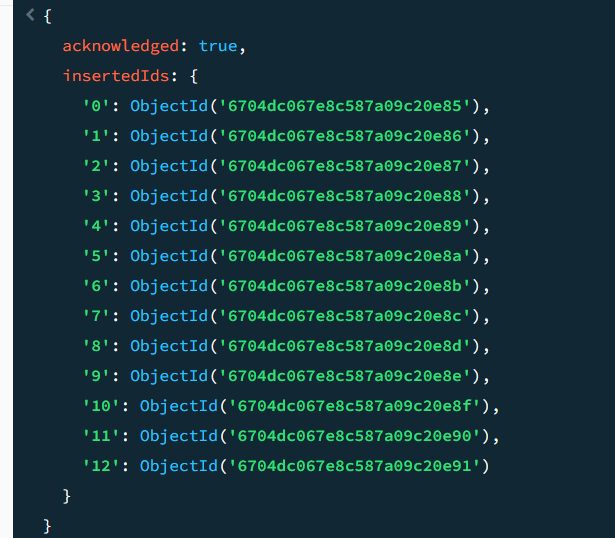
각 컬렉션에 데이터를 삽입한다 (위: 명령문 / 아래: 결과 창)
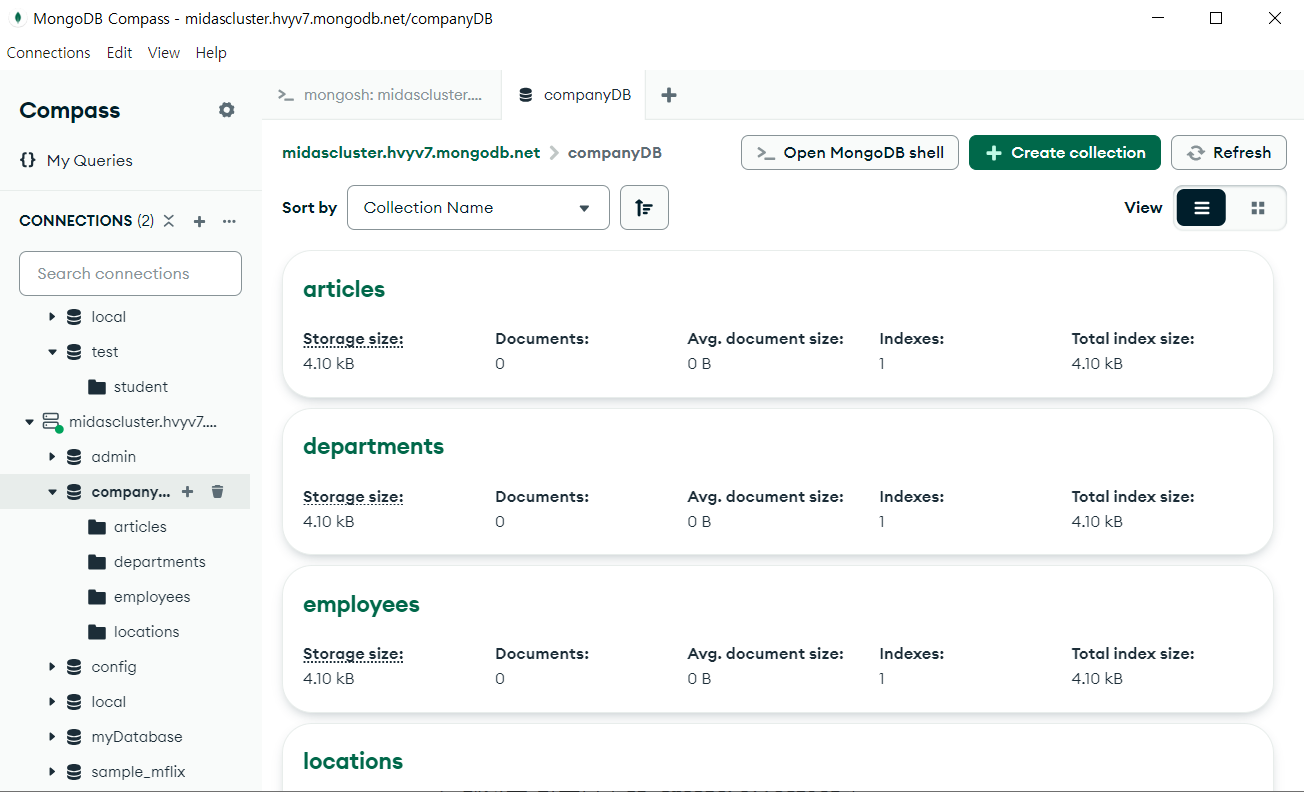
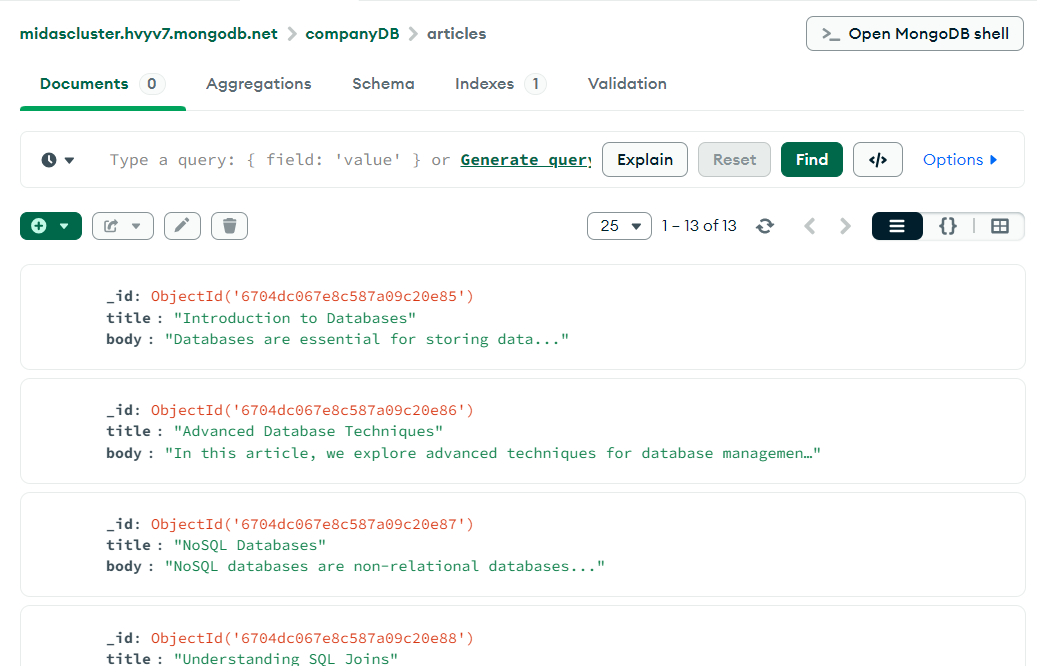
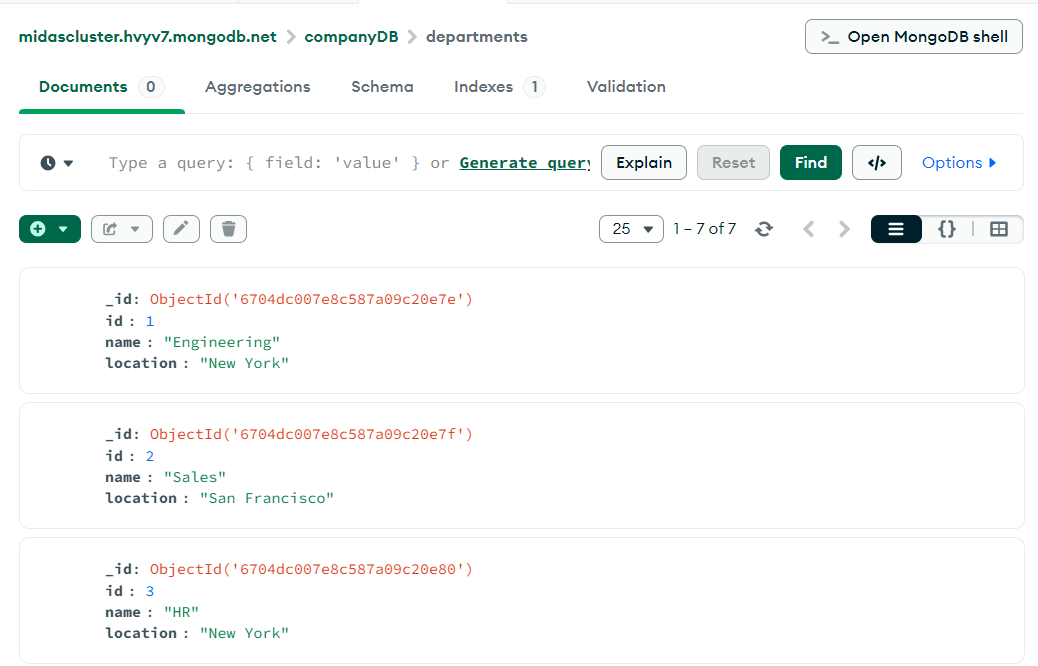
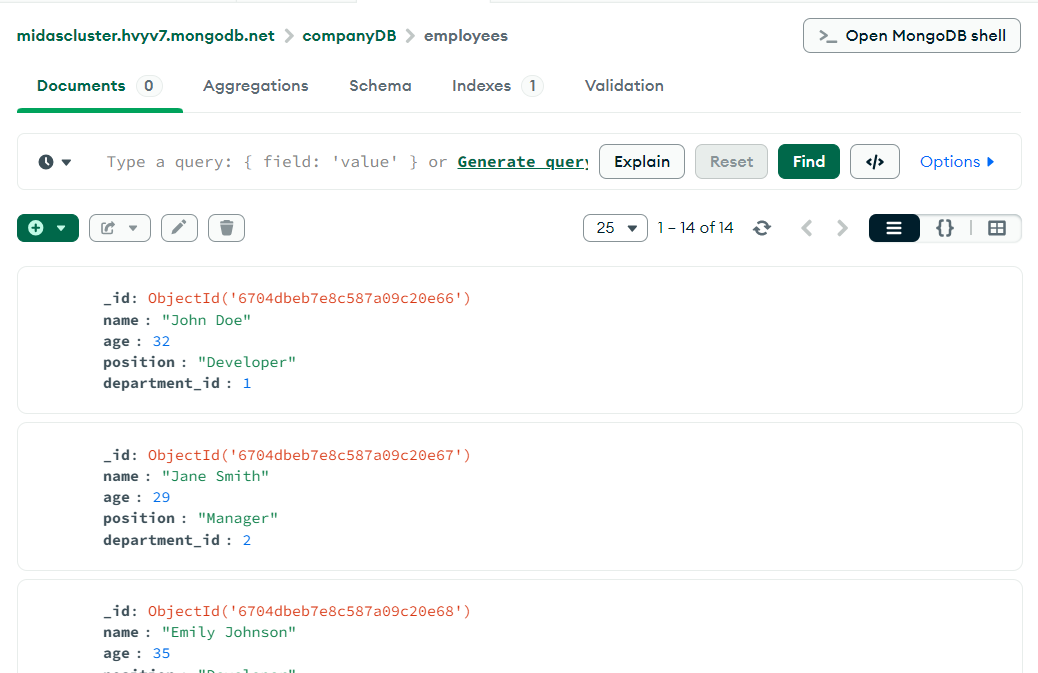
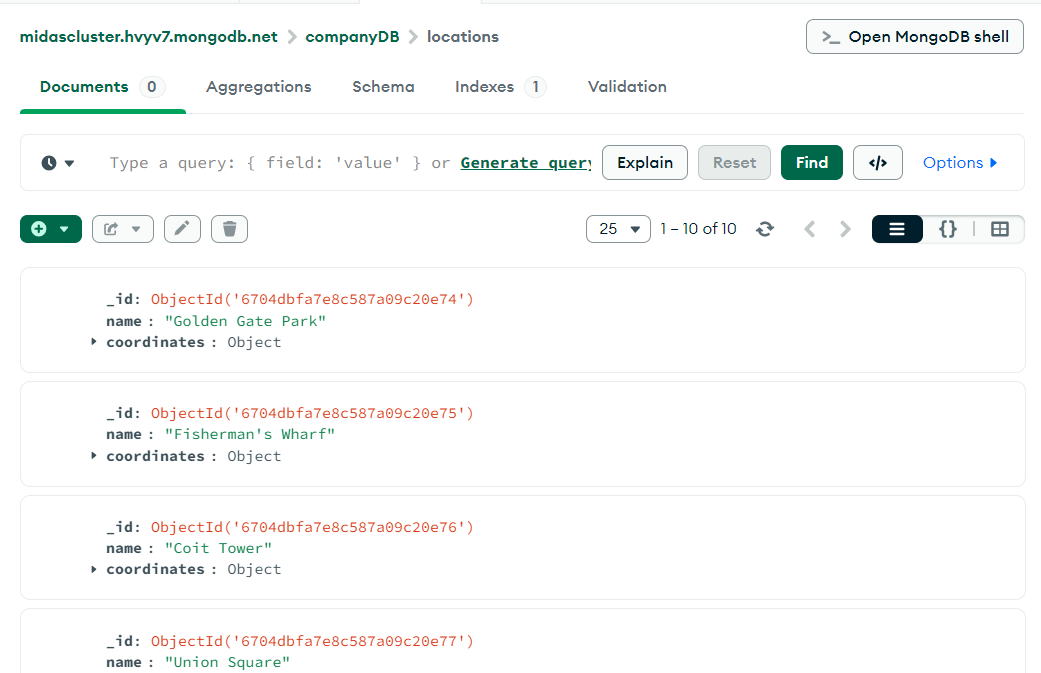
명령어 입력 후 컴파스에 아주 예쁘게 생성된 거 확인 가능!
인덱스 생성
지리 공간 쿼리 성능을 위해서는 필수로 생성해야 한다
db.locations.createIndex({coordinates: "2dsphere"})
🙈 복합 조건 쿼리
db.employees.aggregate([
{
$lookup: {
from: "departments",
localField: "department_id",
foreignField: "id",
as: "department"
}
},
{$unwind: "$department"},
{
$match: {
$or: [
{$and: [{"age": {$gte: 30}}, {"department.location": "New York"}]},
{"position": "Manager"}
]
}
},
{$project: {name: 1, "department.name": 1, _id: 0}}
])1. $lookup (aggregation)
동일한 데이터베이스 내의 컬렉션에 왼쪽 외부 조인을 수행한다. 조인된 컬렉션의 문서를 필터링해서 처리한다.
$lookup의 필드
-
from: 조인을 수행할 동일한 데이터베이스의 컬렉션을 지정한다 -
localField:$lookup단계로 입력된 문서의 필드를 지정한다.foreignField에 대한localField에 대해 동등성 매치를 수행한다.localField가 포함되어 있지 않은 경우, 매칭을 위해 해당 필드의 값을null로 간주한다. -
foreginField:from컬렉션의 문서에서 필드를 지정한다. 설명은 위와 동일. -
as: 입력 문서에 추가할 새 배열 필드의 이름을 지정한다. 새 배열 필드에는from컬렉션에서 매칭되는 문서가 포함된다. 지정된 이름이 입력 문서에 이미 존재하는 경우 기존 필드를 덮어쓴다.
db.employees.aggregate([
{
$lookup: {
from: "departments",
localField: "department_id",
foreignField: "id",
as: "department"
}
}]);따라서 이 문장은, sql 구문으로 바꾸면 아래와 같다.
SELECT *, (
SELECT ARRAY_AGG(d.*)
FROM departments d
WHERE d.department_id = e.department_id
) AS department
FROM employees e;이 구문은 employees 컬렉션과 departments 컬렉션을 조인하여 부서 정보를 배열 형태로 가져오는 방식이다. 공식 문서와 비슷하게 sql 구문으로 변환해봤다. 이는 PostgreSQL 같은 데이터베이스에서 사용할 수 있다고 한다.
{ $lookup: { from: "departments", localField: "department_id", foreignField: "id", as: "department" } }
- employees 컬렉션의 각 문서에 대해서 departments 컬렉션에서 department_id와 id를 기준으로 조인
➡️ 각 직원 문서에 department라는 배열 필드가 추가되고, 해당 직원이 속한 부서의 정보가 담긴다.
2. $unwind (aggregation)
입력 문서에서 배열 필드를 분해해 각 요소에 대한 문서를 출력한다. 각 출력 문서는 배열 필드의 값이 요소로 대체된 입력 문서이다.
필드 경로 피연산자
{ $sunwind: <field path> }
필드 경로를 지정할 때 필드 이름 앞에 달러 기호 $를 붙이고 따옴표로 묶는다.
{$unwind: "$department"}
- department 배열을 분해하여 각 직원 문서마다 부서 정보가 하나의 문서로 변환
➡️ 만약 직원이 여러 부서에 속한다면, 그 직원에 대한 여러 개의 문서가 생성된다. 각 문서에는 해당 직원과 하나의 부서 정보가 포함된다.
3. $match (aggregation)
지정된 쿼리 조건자를 기준으로 문서를 필터링한다. 일치하는 문서는 다음 파이프라인 단계로 전달된다.
{ $match: { $or: [ {$and: [{"age": {$gte: 30}}, {"department.location": "New York"}]}, {"position": "Manager"} ] } }
- 조건에 맞는 문서만 선택
- 1. 직원의 나이가 30세 이상, 해당 부서의 위치가 'New York' 인 경우
- 2. 직책이 'Manager'인 경우
➡️ 이 조건을 만족하는 직원 문서만 남게 된다
4. $project (aggregation)
요청된 필드가 있는 문서를 파이프라인의 다음 단계로 전달한다. 지정된 필드는 입력 문서의 기존 필드일 수도 있고 새로 계산된 필드일 수도 있다.
$project는 필드 포함, _id 필드 표시 안 함, 새 필드 추가, 기존 필드 값 재설정을 지정할 수 있는 문서를 사용한다. 또는 필드 제외를 지정할 수 있다.
$project 사양의 형식
| 형식 | 설명 |
|---|---|
<field>: <1 or true> | 필드 포함 여부를 지정, 0이 아닌 정수도 true로 처리 |
_id: <0 or false> | _id 필드의 억제를 지정 |
<field>: <expression> | 새 필드를 추가하거나 기존 필드의 값을 재설정한다 |
<field>: <0 or false> | 필드 제외 여부를 지정 |
{$project: {name: 1, "department.name": 1, _id: 0}}
- 결과 문서에서 포함할 필드를 지정
➡️name: 직원의 이름 포함
department.name: 해당 부서의 이름을 포함
_id: MongoDB의 기본 _id 필드는 제외
결과 화면
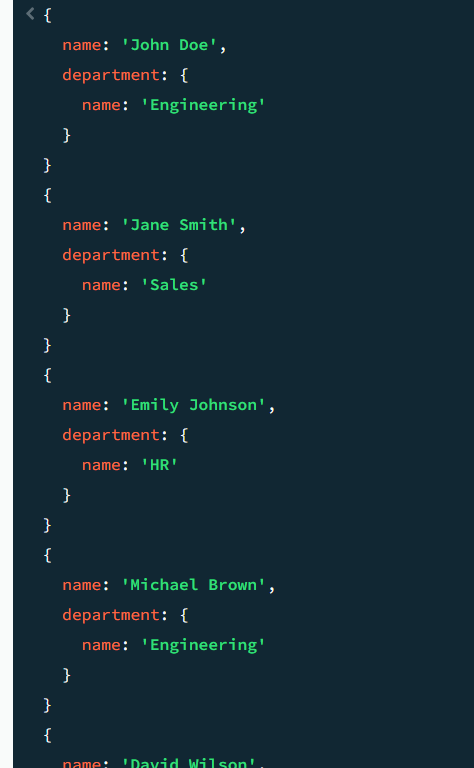
employees 컬렉션에서 각 직원의 부서 정보를 포함하여, 특정 조건을 만족하는 직원의 이름과 부서 이름만을 조회한다. (30세 이상이고 New York에 부서가 있거나 직책이 Manager인 경우)결과는 직원 이름과 부서 이름으로 제한된다.
🙉 집계 쿼리
db.employees.aggregate([
{
$group: {
_id: "$department_id",
employee_count: {$sum: 1}
}
},
{$match: {employee_count: {$gte: 5}}}
])1. $group (aggregation)
'그룹 키'에 따라 문서를 그룹으로 분리한다. 출력은 각 고유 그룹 키당 하나의 문서이다.
$group의 필드
_id: 필수 사항이다._id표현식은 그룹 키를 지정한다.field: 선택사항, 축적자 연산자를 사용해 계산한다.
-$sum: 숫자 값의 합계를 반환한다. 숫자가 아닌 값을 무시한다.
{ $group: { _id: "$department_id", employee_count: {$sum: 1} } }
- eployees 컬렉션의 문서를 그룹화하여, 각 부서(department_id)별로 집계한다
-_id: "$department_id": 그룹화 기준으로, department_id 필드를 사용한다. 각 부서 id가 그룹의 키가 된다.
-employee_count: {$sum: 1}: 각 그룹에 포함된 문서의 수를 카운트한다. 각 문서에 대해 1을 더하여 해당 부서의 직원 수를 계산한다.
➡️ 각 부서 id와 그에 해당하는 직원 수(employee_count)로 구성된 문서들이 생성된다.
{$match: {employee_count: {$gte: 5}}}
- 집계 결과에서 특정 조건을 만족하는 문서만 필터링(employee_count가 5이상)
➡️ 직원 수가 5명 이상인 부서만 선택
결과 화면
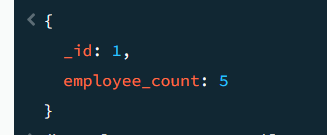
employees 컬렉션에서 각 부서별로 직원 수를 집계한 후, 직원 수가 5명 이상인 부서만을 반환한다. 최종적으로 반환되는 결과는 부서 id와 해당 부서에 속한 직원 수를 포함한 문서들이다.
🙊 텍스트 쿼리
db.articles.find({body: /database/i}, {title:1, _id:0})find 메서드를 사용하여 articles 컬렉션에서 문서를 조회한다.
collection.find()
collection 또는 보기에서 문서를 선택하고 선택한 문서로 커서를 반환한다.
커서(cursor)
쿼리 결과 집합의 포인터이다. 클라이언트는 커서를 통해 반복하여 결과를 조회할 수 있다 사실 잘 이해는 안 감...
첫 번째 인수: 조회 조건
{body: /database/i}정규 표현식: body 필드에서 "database"라는 단어를 찾아야 한다는 조건
/.../→ 정규표현식i→ i 플래그는 대소문자를 구분하지 않도록 설정한다
➡️ body 필드에 "database"라는 단어가 포함된 모든 문서를 찾는다
두 번째 인수: 반환할 필드
{title:1, _id:0}필드를 선택한다!
title: 1: title 필드를 포함하겠다는 의미_id: 0: MongoDB의 기본 _id 필드를 제외하겠다는 의미
결과 화면
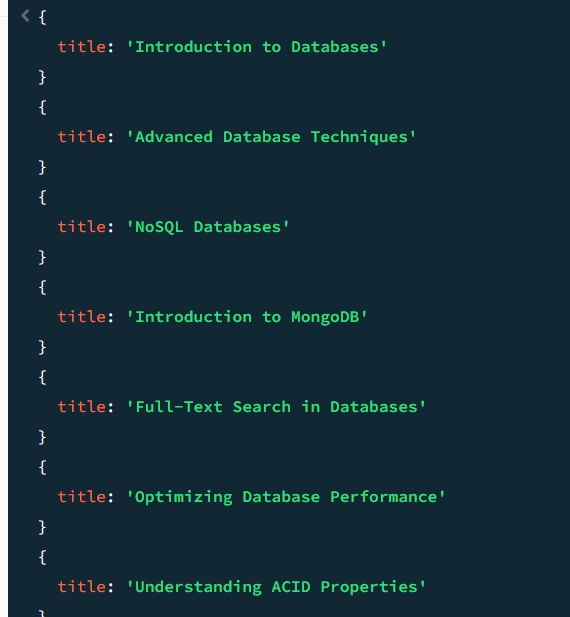
articles 컬렉션에서 body 필드에 "database"라는 단어가 포함된 모든 문서를 조회하고, 그 결과에서 title 필드만을 반환한다. _id 필드는 결과에서 제외한다.
🐵 지리공간 쿼리
db.locations.find({
coordinates: {
$near: {
$geometry: {
type: "Point",
coordinates: [-122.4194, 37.7749]
},
$maxDistance: 10000
}
}
})find 메서드를 사용하여 locations 컬렉션에서 문서를 조회한다.
조회 조건: $near
주어진 지점에 가까운 위치를 찾기 위해 사용되는 연산자
$geometry
검색할 지점을 정의한다
type: "Point": 이 객체가 점(Point) 타입임을 나타낸다coordinates: 해당 지점의 경도와 위도를 나타낸다. (샌프란시스코 좌표임)
$maxDistance
검색할 최대 거리(단위: 미터)를 정의한다. 여기서는 10,000m(10km) 이내의 위치를 검색하겠다는 의미이다.
결과 화면
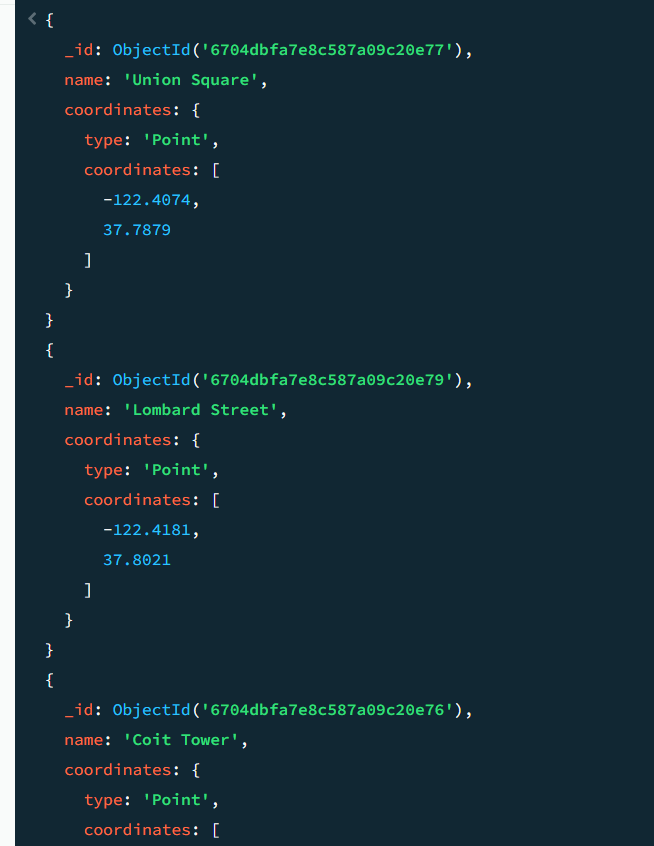
locations 컬렉션에서 주어진 좌표에서 최대 10,000미터 이내에 있는 모든 장소를 찾는다. 샌프란시스코 근처의 위치 정보를 포함하는 문서들이 반환된다.
느낀점
NoSQL도 비슷한듯 다른듯... RDBMS를 주로 배워오던 나에겐 참 와닿지 않는 용어나 개념이 많은 것 같다. 알듯말듯... 어려움. 그나마 시퀄라이즈 ORM을 사용해봐서 익숙하게 느끼는 것 같다. 잘 사용할 수 있게 되면 좋겠다... 열심히 공부해야지...
본 포스팅은 글로벌소프트웨어캠퍼스와 교보DTS가 함께 진행하는 챌린지입니다
