저번 블로그에 이어 이번에는 scraping 해온 데이터를 db에 저장하는 방법을 살펴본다.
sqlalchemy는 파이썬에서 사용가능한 ORM이다. 다음의 명령어로 설치를 한다.
pip install sqlalchemydb는 sqlite3를 사용했다.
1. 필요한 modules import.

2. create_engine 을 사용하여, file기반 db를 생성.
engine = create_engine('sqlite:///book.db', echo = True)echo = True를 설정하면 코드실행시, 진행사항을 프린트 해준다.
3. declarative_base() 를 통해, declarative 기반 클래스를 불러오기.
이 클래스는 모든 테이블 객체들을 metadata로 정의해 둔다.
테이블을 생성하고, 생성한 class의 argument로 Base를 넘겨주어 mapping 준비를 한다. __tablename__을 선언하여 테이블 명을 정해주었을때 mapping이 이루어진다.
<클래스이름>.__table__.create() 명령어를 통해 mapping한 테이블이 실제로 생성되므로, 빼먹지 않도록 주의한다.

4. sessionmaker를 사용하여 db에 데이터 처리 준비.
sessionmaker는 sqlalchemy에서 제공하는 class이며, session을 만들어 준다. bind=engine을 통해, db와 연결한후 생성한다.
Session = sessionmaker(bind=engine)
session = Session()
세션(session)이란?
일정 시간동안 같은 사용자(브라우저)로 부터 들어오는 일련의 요구를 하나의 상태로 보고 그 상태를 일정하게 유지시키는 기술. 또한 여기서 일정 시간이란 방문자가 웹 브라우저를 통해 웹 서버에 접속한 시점으로부터 웹 브라우저를 종료함으로써 연결을 끝내는 시점을 말하며 즉, 방문자가 웹서버에 접속해 있는 상태를 하나의 단위로 보고 세션이라고 칭한다는 것.
(Quote: https://88240.tistory.com/190 [shaking blog])
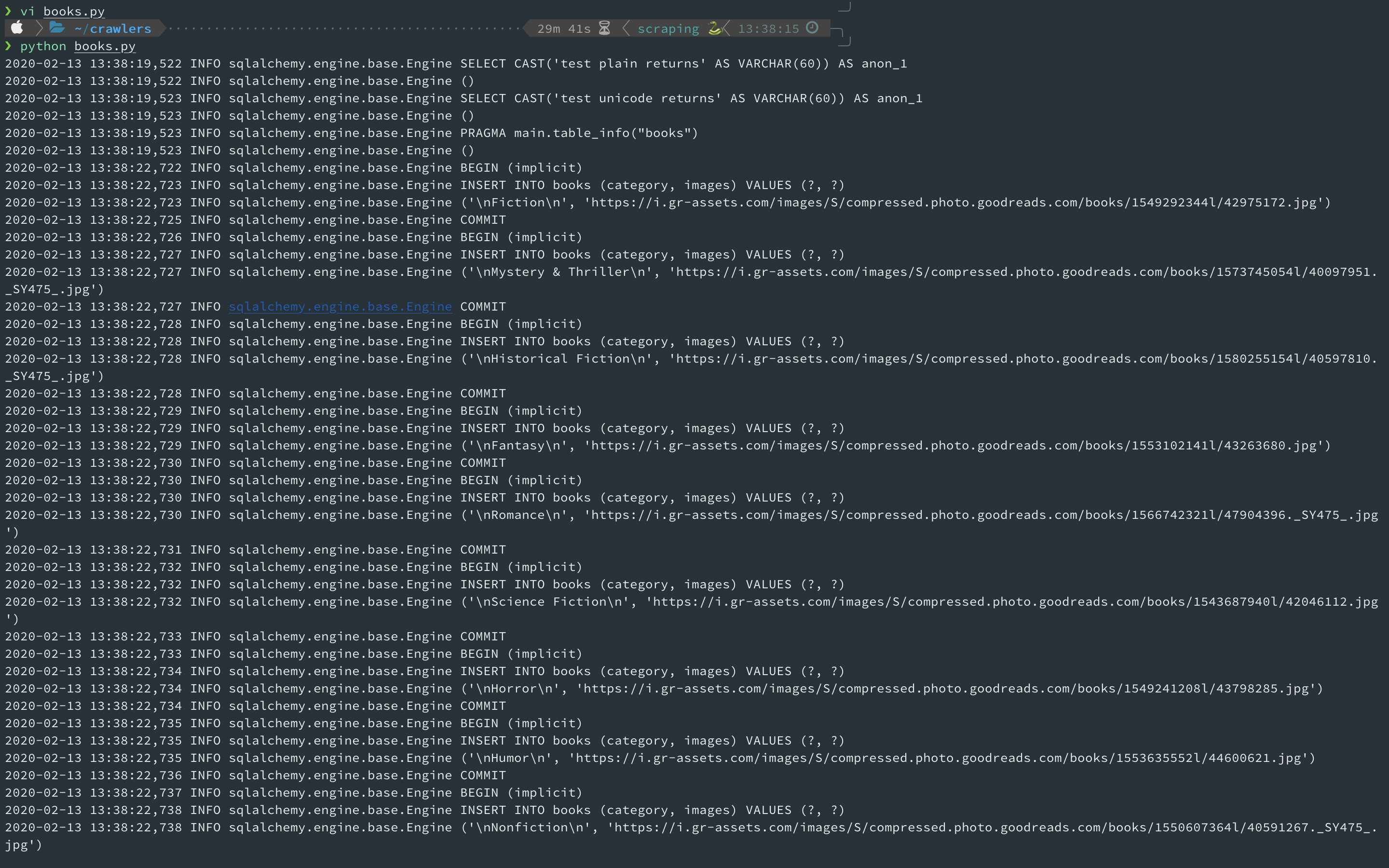
5. db에 데이터 저장하기.
장고의 view에서 sign-up 기능 구현시, .save()를 사용하여 POST데이터를 db에 저장했다. 같은 처리를 sqlalchemy에서는 session.add()와 session.commit을 사용하여 진행한다.

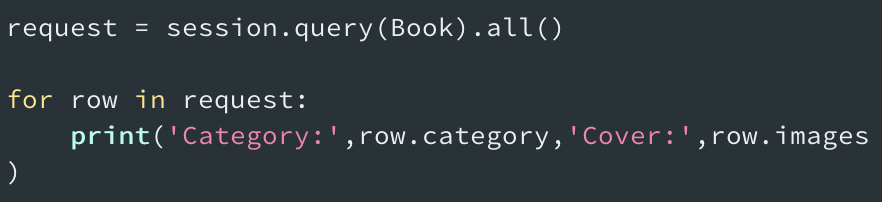
다음의 코드로 db의 저장내용을 확인한다.
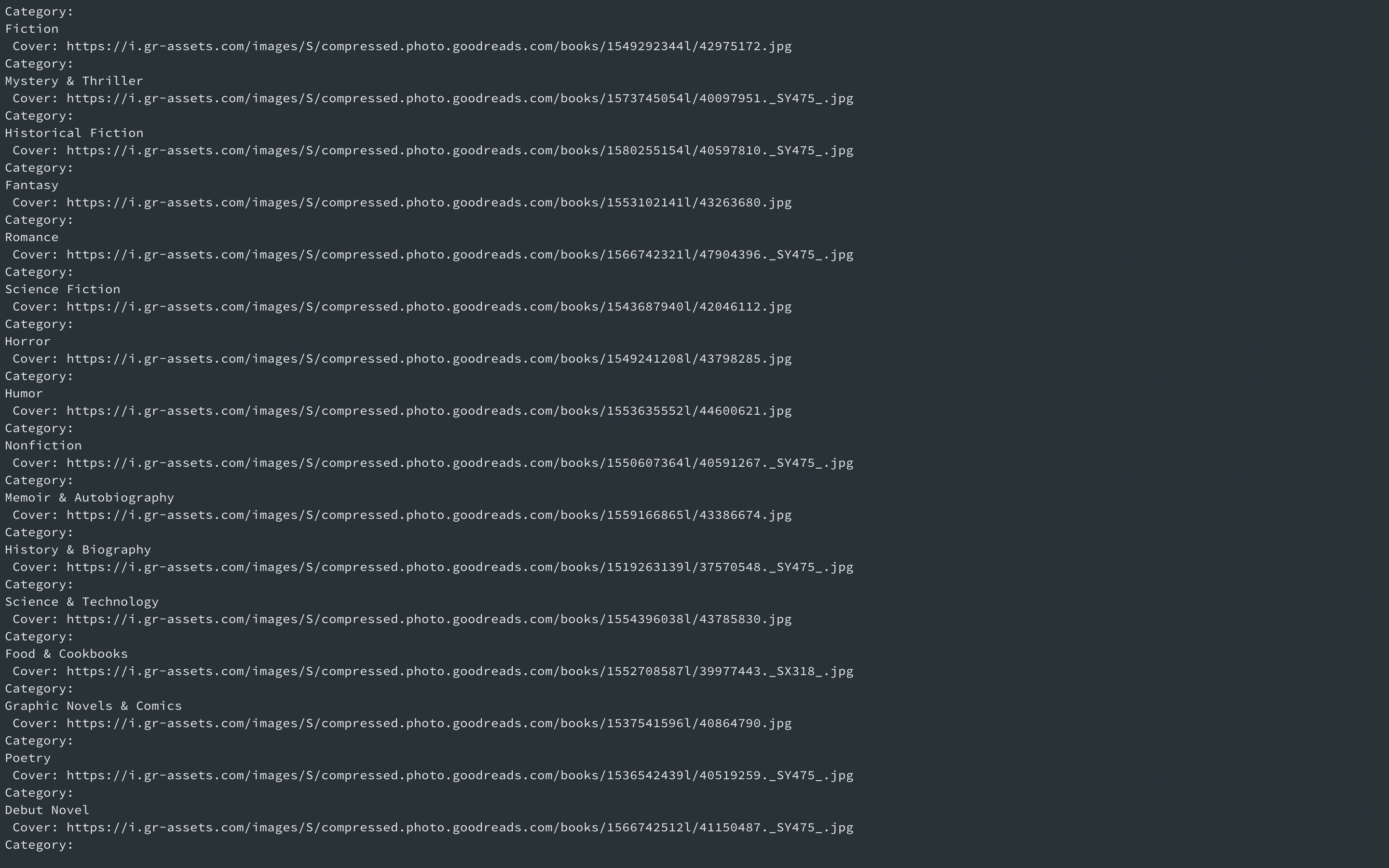
저장된 내용은 다음과 같다.
참고링크:
https://ulfrid.github.io/python/python-sqlalchemy/
https://edykim.com/ko/post/getting-started-with-sqlalchemy-part-1/
https://yujuwon.tistory.com/entry/SQLALCHEMY-session-%EA%B4%80%EB%A6%AC
