Goodreads 에서 2019 choice award에 선정된 책들의 커버 이미지와 장르를 scraping하는 연습을 했다.
초기설정
BeautifulSoup과 requests를 사용하므로, 가상환경에 설치가 필요하다. 전자는 HTML을 파이썬이 이해할 수 있도록 parsing 하는 기능을 제공하며, 후자는 HTTP통신을 가능하게 하는 동시에 응답내용을 text로 변환해 주는 기능도 제공한다.
다음의 명령어로 설치를 실시한다.
$ pip install bs4 requests스크래핑 순서
-
가상환경에 접속하고 해당 디렉토리에 새로운 파이썬 파일을 만든다.
-
앞서 설치한 modules를 import 해준다.

-
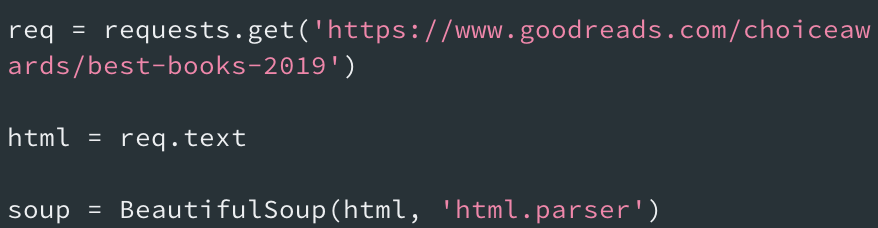
requests의 GET 메소드를 사용하여 해당 URL을 읽어온다.
읽어온 파일을 사용할수 있도록 text파일로 변환한다.
이 상태에서는 아직 파이썬이 사용할 수 없는 상태이므로, parsing이 필요하다.BeautifulSoup클래스를 사용하여 다음과 같이 설정해 준다.
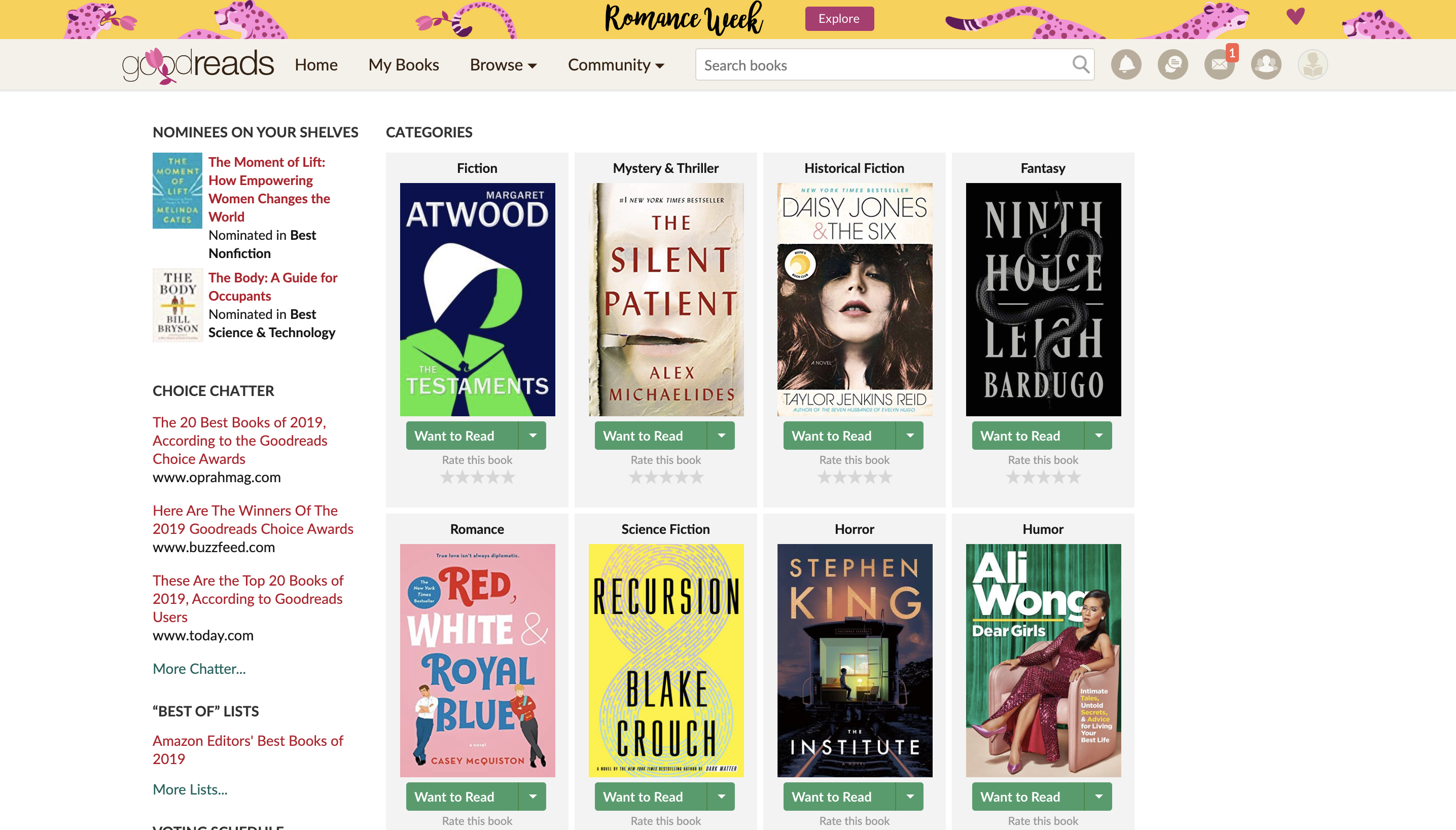
- 이제 본격적으로 scraping할 요소를 가져와 보자.
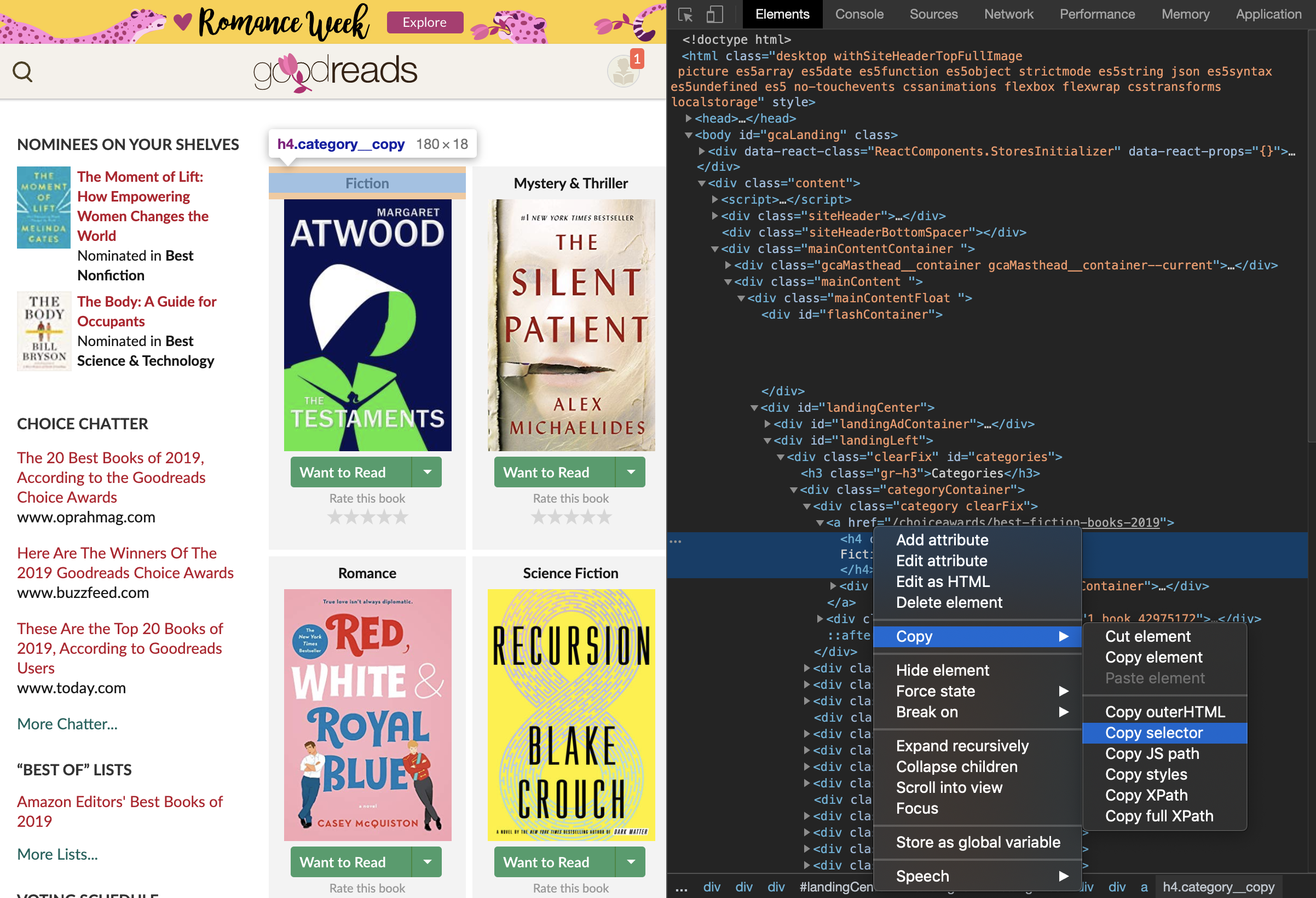
해당 사이트의 개발자 툴을 열고 Element를 선택한다. 왼쪽 최상단의 마우스 포인터를 클릭하고 사이트에서 원하는 요소에 마우스를 대면, html안에서 해당 요소의 tag가 있는 부분을 하이라이트 해준다. 여기서 Copy selecor를 하면 CSS 셀렉터가 복사되며 다음과 같은 결과가 복사된다
#categories > div > div:nth-child(1) > a > h4이 코드를 그대로 쓰면, div의 1번째 child만 불러오게 된다. 나는 모든 카테고리를 불러올 것이므로, 코드를 다음과 같이 수정했다.

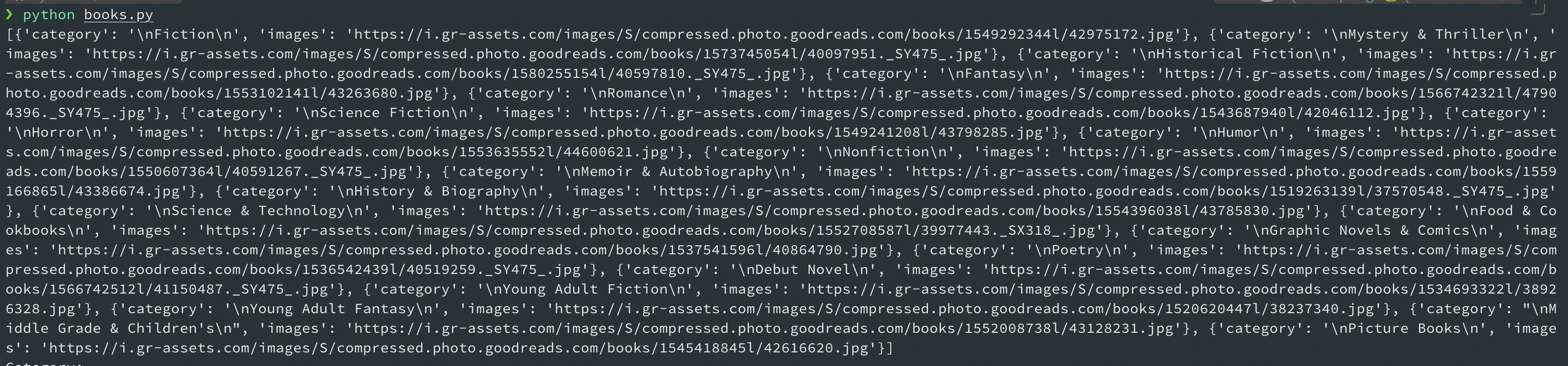
pring를해서 확인해 본 결과, 카테고리가 성공적으로 나타났다.
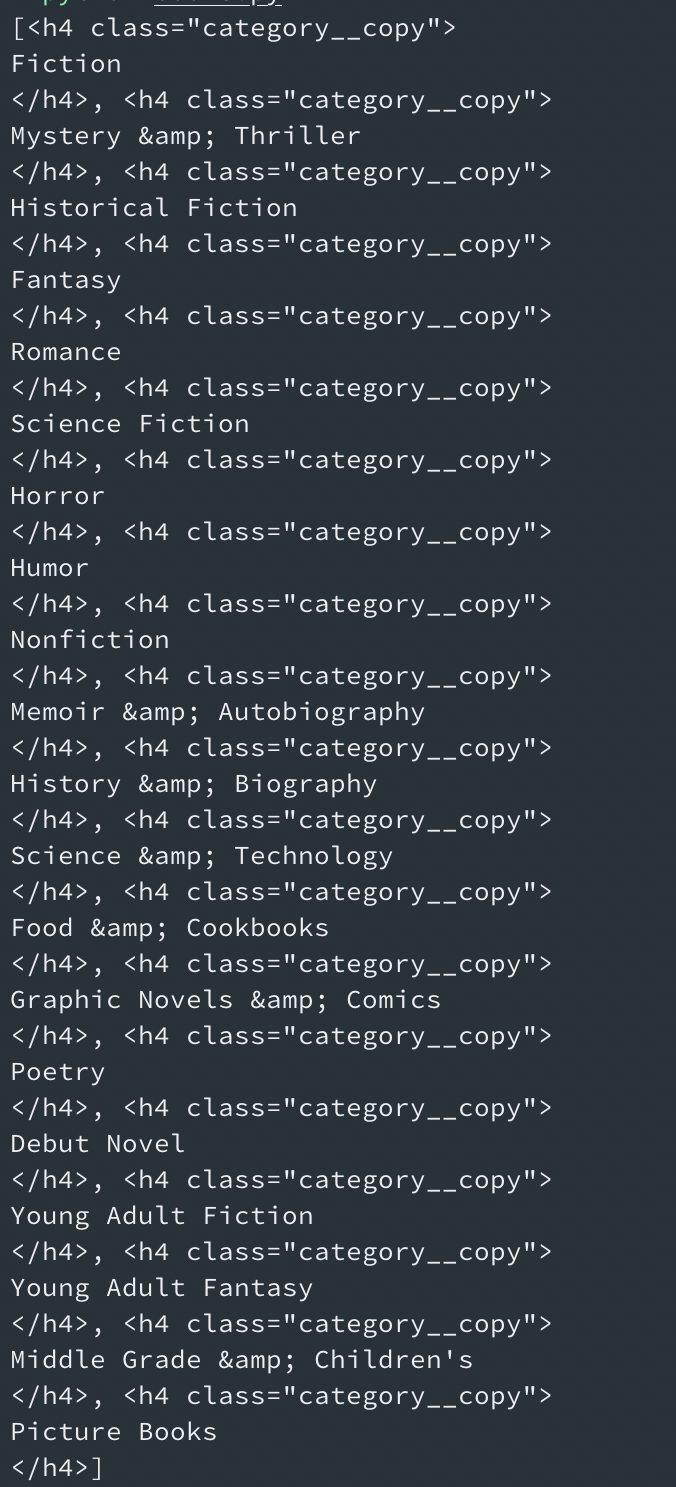
이처럼 간단하게 수정이 끝나는 경우도 있지만, html의 구성에 따라 꽤 많은 시행착오가 생길 때가 있다. 따라서 print()를 사용하여 원하는 요소가 나오는지를 체크하며 진행한다.
soup.select()는 모든 매치되는 CSS selector의 요소들을 리스트로 리턴한다.
다음은 img 태그의 src를 불러온다.
태그안의 속성을 불러올 경우, 단순히 > tag를 더하는 것으로는 안된다. 따라서 다음과 같이 빈 리스트를 만들고, for문을 돌리면서 각 요소안의 'src'만 불러와여 append하는 코드를 작성하였다.

print로 확인한 결과는 다음과 같다.

- 다음은 4에서 불러온 정보들을 dictionary 형태로 만들어서 하나의 리스트에 넣어주는, "조립" 단계가 필요하다.
빈 리스트를 만들고, category와 images를 key로 가지는 딕셔너리를 만든다. zip()을 사용하여 다음과 같이 작성하였다.

print(book_nominees)로 확인한 결과는 다음과 같다.