
불과 10전까지만 해도 ARM은 저전력 저성능이라는 딱지를 붙이고 다녔다
고성능이라는 단어와는 도저히 매치가 되지를 않았다
그런데 모바일 기기에 도입된 ARM은 점차 발전을 이루어 고성능이라는 키워드를 위협하기 시작했다
이러한 흐름속에 사람들은 새로운 궁금증을 가지게 되었다
스마트폰 프로세서의 크기를 키우면 PC 만큼의 성능을 낼 수 있지 않을까?
그리고 3년전 이러한 생각을 현실화하는 사건이 등장한다
Apple Silicon의 등장은 개인적으로 너무나 큰 충격이었다
저전력 칩으로 데스크탑의 성능을 낼 수 있다는 사실은 물리 법칙에 부합하지 않는 오류처럼 보였다
이후 출시된 M1 Ultra는 Scaling을 통해 업계 최고 수준의 데스크탑 성능을 선보였다
이보다 더 크고 전력소모가 더 많은 칩은 워크스테이션 시장도 넘볼수 있을것만 같았다
그리고 무엇보다도, 이러한 행보는 반도체 시장의 흐름을 바꾸기에 충분했다
Apple Silicon의 등장으로 많은 이들이 mac을 시도해보고 있다
과거의 맥이라하면 가성비 쓰레기 제품군으로 일종의 사치품처럼 여겨졌다
그런데 이제는 일부 엔트리 라인에 한해서 가성비 제품으로 보일 정도다
실제로 애플의 불모지라 불리던 한국에서조차 이제는 맥북이 꽤 흔하게 보인다
대학교 강의실에서 가장 많이 보이는 노트북 중 하나로 사과 로고는 더이상 힙스터의 전유물이 아니게 되었다
이런 Apple Silicon의 성공은 나에게 있어 한가지 궁금증을 남겼다
과연 ARM은 x86의 부진을 틈타 새로운 왕좌를 차지할만한 아키텍쳐일까
아니면 그저 과대평가된, 그러니까 몇 년뒤 묻힐 그저그런 아키텍쳐인걸까
이 질문에 대한 대답을 찾아본지 벌써 1년이 넘은것 같아 슬슬 정리해보려한다
물론 프로그래머 지망생으로써 computer architecture 관련 지식은 많이 부족하다
그리고 독학한 부분이 많아 잘못 알고있는 부분이 태반일 것이다
어쩌면 굉장히 단순하고 편협한 시각에서 관찰된 결과일 수도 있을것 같다
그럼에도 불구하고 이렇게 정리해놓지 않으면 나중에 또 몇일 동안 찾아볼꺼 같아 정리해보려한다
CISC와 RISC
일반적으로 ARM과 x86의 차이를 CISC와 RISC로 설명한다
해당 논쟁을 찾아본 사람이라면 아마 이 둘의 특징을 수도없이 봤을것이다
그리고 이 특징들을 본다면 소비전력과 성능에서의 차이를 납득할 수 있을 것이다
물론 나도 이러한 특징들을 바탕으로 ARM은 저전력과 저성능의 한계에서 못벗어난다고 믿었다
그러나 서론에서 언급했던 것처럼 Apple Silicon의 등장으로 모든 공식이 깨진것 같았다
이 무렵 나는 computer architecture에 관심이 생겨서 막 공부를 시작했었다
작은 칩들이 뿜어내는 성능은 너무나도 매력적이었고 마치 마법과도 같아보였다
그러던 중 내가 알던 상식과 다른 한 영상을 접하게 되었다
https://youtu.be/2EWejmkKlxs?t=2215&si=CKA25i2sGc8R-SJF
저 영상을 보면 알겠지만 뭔가 이상해보인다
분명 CISC 기계인데, RISC스러운 명령어들이 튀어나온다
그리고 내부적으로는 저 RISC스러운 명령어가 실제로 동작하는거라고 한다
위키피디아에 검색해보아도 동일한 말을 한다
https://en.wikipedia.org/wiki/Intel_Microcode
이것이 무엇을 의미하는지 확인해보기 위해 architecture의 구조를 찾아보았다
원래는 최신 architecture를 기반으로 찾아보려고 하였다
그러나 성능 향상을 위한 다양한 기법들은 이해를 어렵게만 만들 뿐이었다
그래서 대략 2000년대 중반의 자료들에 기반하여 비교하였다
ARM microarchitecture
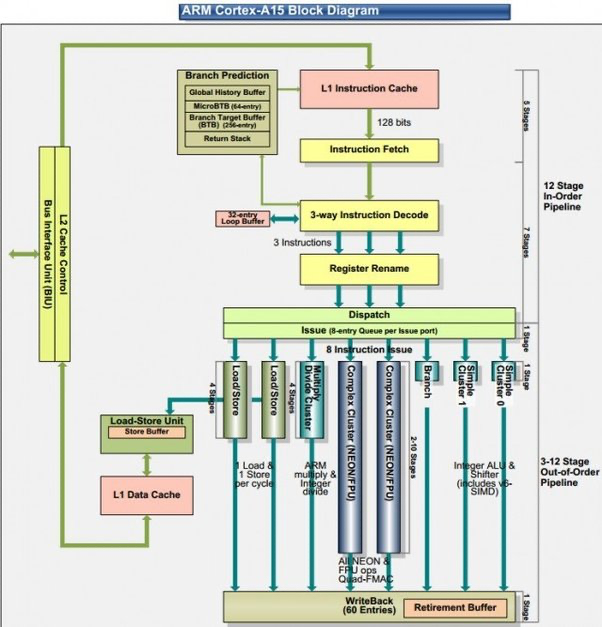
https://www.quora.com/What-is-so-great-about-ARMs-Cortex-A-15
사진 화질이 좀 안좋긴 한데, 그나마 보기편한 다이어그램이 저거뿐이라 그냥 들고왔다
ARM의 경우 전형적인 RISC 기계라 할 수 있다
이런 RISC 기계의 아주 대략적인 실행순서를 확인해보자
- Fetch
- Decode
- Register Rename
- Dispatch, Issue
- Execute
- WriteBack
Pipelining을 공부한 사람이라면 너무나도 당연한 소리다
Pipelining이 더이상 RISC만의 전유물은 아니게 되었지만, RISC와 함께 등장한 개념이다
그렇기에 일부 CISC, RISC의 비교에서 이를 RISC의 특징으로 소개하기도 한다
Intel microarchitecture
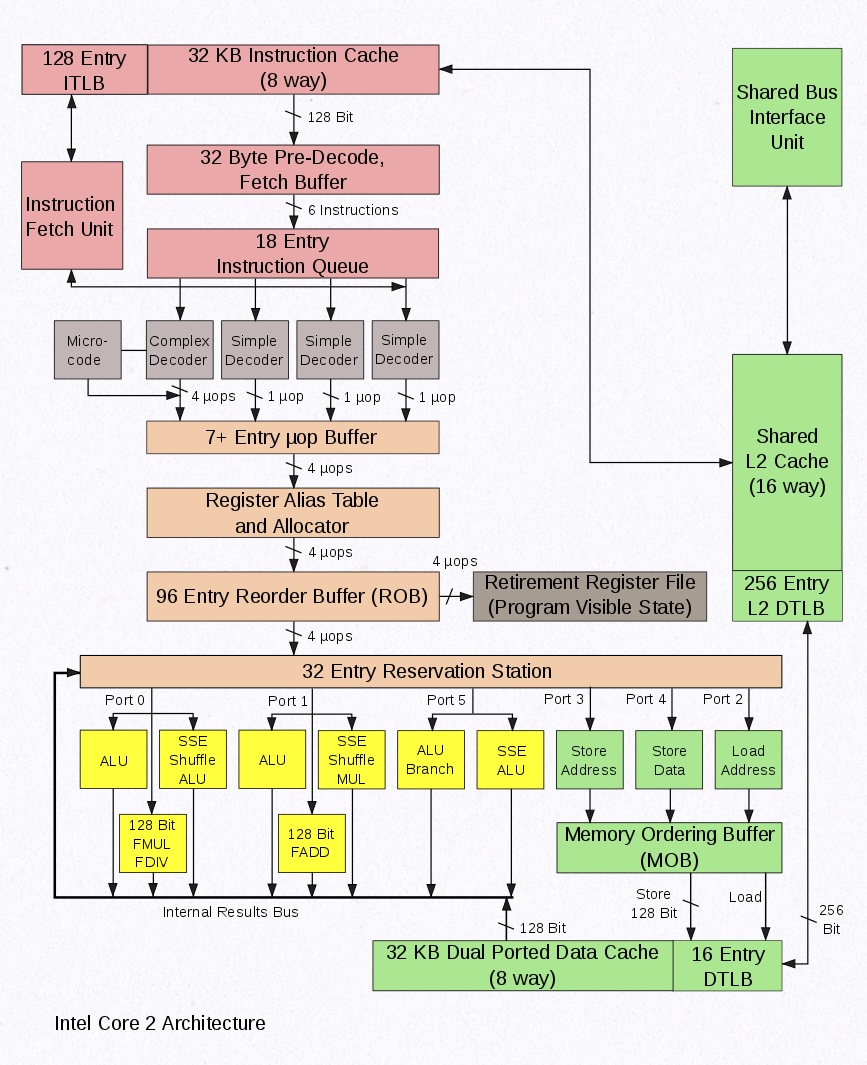
https://en.wikipedia.org/wiki/Intel_Core_(microarchitecture)
그렇다면 인텔은 내부적으로 어떻게 실행하고 있을까
비슷한 시기에 출시되었던 Intel Core microarchitecture을 가져와보았다
위와 동일하게 아주 대략적인 실행순서를 확인해보자
- Pre-Decode, Fetch
- Decode
- Register Alias Table, Allocate
- Reorder Buffer
- Reservation Station
- Internal Results Bus, Memory Ordering Buffer
실행의 명칭을 잘몰라서 그냥 Unit의 이름을 적어놓았는데 어찌되었건 하고자하는 것이 ARM과 비슷하다
1번의 경우 Pre-Decode가 추가되었지만, 동일하게 Fetch한다
3번에서 Register Alias Table에 기록하고 Register Allocate하는 모습은 Register Renaming과 유사하다
5번의 Reservation Station에서 하는일은 크게 두가지로 나뉜다
하나는 Register Renaming이고, 다른 하나는 Instruction Dynamic Scheduling이다
즉, Instruction Issue, Dispatch 단계라 볼 수 있다
마지막으로 6번 또한 결국 Register Renaming과 더불어 WriteBack의 단계라 볼 수 있다
물론 실질적으로 들어가는 알고리즘이나 구현방식은 다를것이다
단지 큰 틀에서 그 방식이 유사하다는 점을 말하고 싶었을 뿐이다
Superscalar
사실 지금까지 말한 내용은 모두 Superscalar에 관한 내용이다
해당 개념은 1980년대에 등장해서 1990년대에 거의 모든 CPU에 적용된 개념이다
물론 개념 자체는 복잡도와 같은 내용보다는 병렬 처리나 dependency와 같은 부분에 초점을 둔다
하지만 이러한 개념을 더 효율적으로 활용하기 위해서는 RISC 방식이 필요하다
Superscalar을 이야기할때 빠지지 않는 것이 바로 pipelining이다
이러한 pipelining을 더 효율적으로 수행하기 위해서는 Single cycle execution이 필요하다
여기서 모든 명령어가 Single Cycle execution이어야하는 것은 아니다
단지 Single Cycle에서 execute되는 명령어가 많을수록 그 효율이 증가한다는 것이다
명령어의 실행시간이 전부 동일해야 마치 블럭을 쌓아나가듯, 빈공간 없이 사용할 수 있기 때문이다
사실 지나치게 직관적이고 부족한 설명이지만, 더 좋은 설명을 하려면 글이 길어질것 같다
그리고 단락과의 연관성 때문에 아주 짧게 언급만 하려고 적은 것이다
그리고 아직도 개념을 완벽하게 이해했다고 보기는 어려워 더 설명했다가는 틀릴것 같다
오늘날 유일하게 살아남은 CISC로 평가받는 x86 또한 이러한 변화를 했기에 살아남았다
이 외에도 대부분의 CPU 제조사들은 micro-op, macro-op와 같은 개념을 사용하기 시작했다
즉, ISA의 복잡도와는 상관없이 CPU 내부적으로는 micro-op와 같이 RISC스러운 명령어를 사용한다
그렇다면 과연 이러한 구조에서 ISA가 복잡하다고 CPU가 성능이 좋아진다고 말할 수 있을까
혹은 ISA가 단순하다고 CPU의 효율이 증가한다고 말할 수 있을까
Misconception
Architecture 관련해서 검색하다보면 아래와 같은 뉘앙스의 표현이 심심잖게 보인다
RISC는 명령어가 단순하니까 성능이 안나오지만, 효율이 좋습니다. CISC는 그 반대라고 할 수 있죠.
마지막에서도 다시 언급하겠지만 x86이 CISC가 아니라는 이야기가 아니다
마찬가지로 ARM이 RISC가 아니라는 이야기도 아니다
이제는 더 이상 RISC와 CISC라는 단어로 성능과 효율성을 이야기할 수 없다는 것을 말하고 싶다
CPU는 몇개의 단어로 구분할 수 없는 굉장히 복잡한 시장이 되어버렸다
다시 처음으로 돌아가 이 글을 시작했던 이유를 상기시켜보자
ARM과 x86의 비교, 그 중에서도 Apple Silicon의 성공 신화에 대한 궁금증이었다
하지만 CISC, RISC의 결론으로는 해결된 궁금증이 한개도 없다
그래서 이번에는 그냥 Apple Silicon 자체에 대한 공부를 시작했다
Magic inside Apple microarchitecture
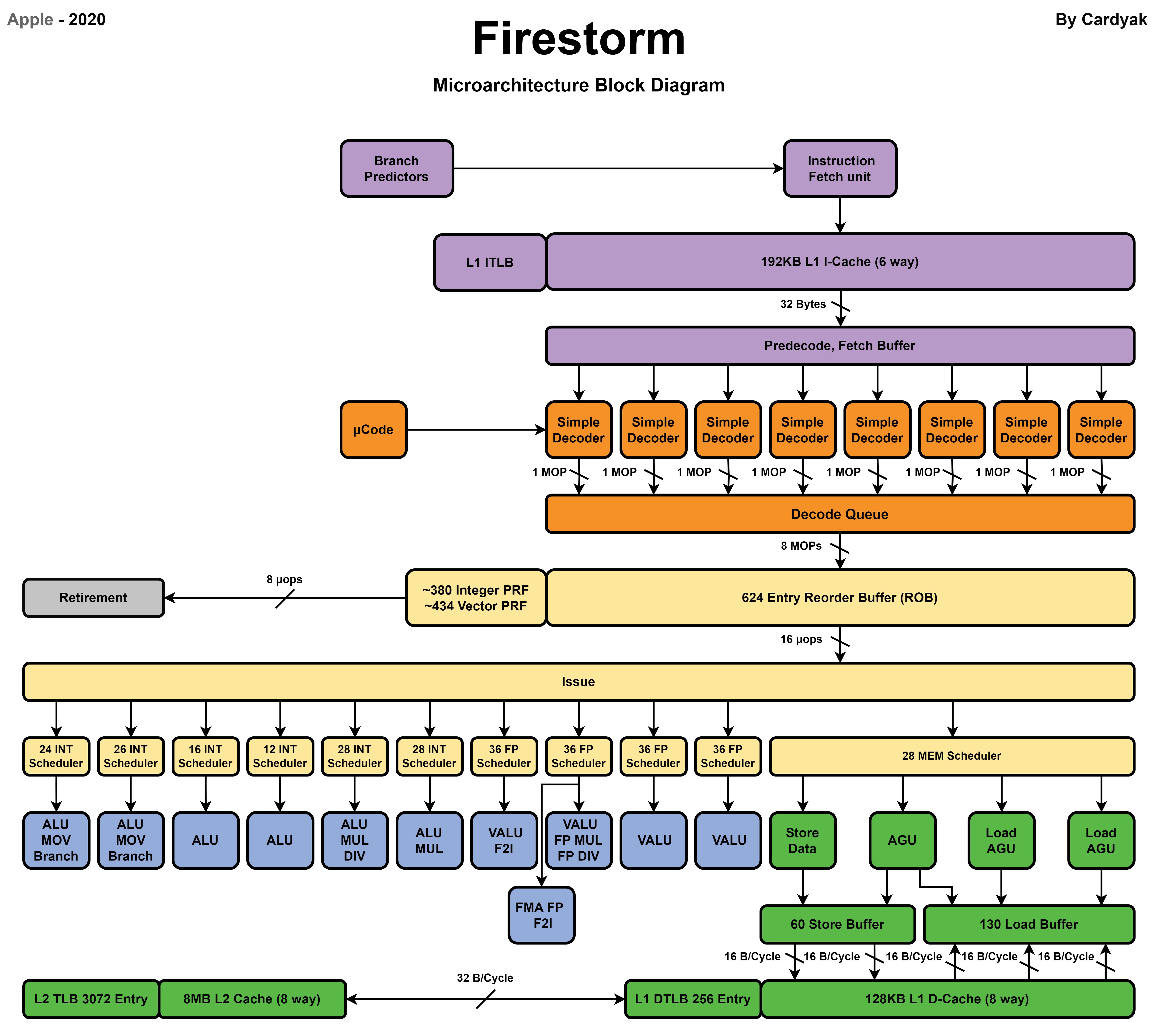
https://drive.google.com/drive/folders/1-Ls0SiqXBCBhMGr87ldA_47GETWfjCzQ
위와 동일하게 Core 자체의 관점에서 확인해볼 필요가 있다고 생각했다
Core 내부적으로 뭔가 개쩌는 신기술이 있어 성공 신화의 열쇠가 될 수 있지않을까
아쉽게도 위 사진을 보면 알 수 있듯, 그런건 없다는것을 알 수 있다
Computer architecture 발전 과정에서 쌓인 노하우(?)들이 모두 동일하게 적용된 모습이다
다만 기존의 architecture에서는 볼 수 없던 인상적인 부분들이 보이는것은 사실이다
Cache
가장 먼저 컴퓨터를 좋아하는 사람이라면 한번쯤 들어봤을 Cache를 봐보자
캐시는 architecture 발전 과정에서 지대한 영향을 미쳤다
특히 최근들어 미세공정에서 힘든 모습을 보이자 AMD는 Cache라는 해답을 제시했다
AMD의 3D V-Cache는 일부 영역에서 큰 폭의 성능향상을 보여주며 찬사를 받았다
이렇듯 Cache는 architecture에 있어 적잖게 영향을 미치는 요소로 평가된다
이러한 관점에서 위 Firestorm을 살펴보자
L1I-Cache에 192KB, L1D-Cache에 128KB를 보유하고 있는 모습이다
이게 도대체 얼마나 되는지 감이 안오는 사람들을 위해 한번 정리해보았다
L2-Cache는 그냥 편하게 코어당 Cache로 계산해보았다
L3-Cache는 코어당으로 계산하기 너무 복잡해서 그냥 따로 적었다
이걸 직접 계산하기에는 Core 구성과 개수가 각자 너무나도 다르기 때문이다
그리고 ARM은 아직 Desktop급 CPU가 없어서 L3 비교에서 제외하였다
| Architecture | L1I-Cache(KB) | L1D-Cache(KB) | L2-Cache(MB per core) |
|---|---|---|---|
| Apple Firstorm | 192 | 128 | 3 |
| Intel Golden Cove | 32 | 48 | 1.25 |
| Razen Zen 3 | 32 | 32 | 0.5 |
| ARM Cortex A77 | 64 | 64 | 0.25 ~ 0.5 (?) |
| Core | P-Core count | E-Core count | L3-Cache(MB shared) |
|---|---|---|---|
| Apple M1 | 4 | 4 | 8 |
| Apple M1 Max | 8 | 2 | 48 |
| Intel i7-12700 | 8 | 4 | (Up to) 30 |
| Razen 5700X | 8 | - | 32 |
L1 Cache와 L2 Cache의 경우 타사 제품들대비 2~4배가량 더 많이 있다
L3 Cache에서는 2~4배까지는 아니지만 그래도 더 많은 Cache를 보여준다
모두 동일한 시기(2021년말 ~ 2022년 중반)에 발표되었다는 점을 고려해볼때 상당한 차이라고 할 수 있다
AMD의 경우 3D Line으로 가면 Ultra와 비슷한 크기의 L3 Cache를 보여주긴한다
하지만 Cache가 CPU의 절재적인 성능 지표라고 할순 없을것이다
그리고 Cache 용량이 큰게 무조건 좋다고 말할수도 없을것이다
Cache Simulator를 돌려보면 용량이 일정수준을 넘어서는 순간 성능 향상이 미미해진다
이는 실제 CPU에서도 비슷한 양상을 보이며, 과도하게 큰 Cache는 자리만 차지하는 쓰래기가 된다
그러면 도대체 둘 중 누가 맞는것일까
이미 수년에서 수십년간 입지를 다져온 회사들중 틀린 답안이라는건 존재하지 않는다
이들 모두 엄청난 돈을 들이부어 가장 효율적인 설계를 찾고자 노력하기 때문이다
모든것에는 이유가 있기 마련이고 Apple Silicon의 경우 그 거대한 덩치에 있다고 생각한다
Bigger and Wider
Instruction이 Fetch 되는 Decoder 부터 살펴본다면 심상치 않은 숫자를 맞이할 수 있다
8-Wide Decoder는 역사상 손가락에 꼽힐정도로 넓은 Decoder에 속한다
그리고 이 넓은 Decoder를 사용하기 위해서는 Reorder Buffer 또한 커야할 것이다
이에 답하듯, Reorder Buffer 또한 620 entries라는 엄청난 크기를 보여준다
Integer Register File 또한 거의 380 entries에 달하는 거대한 크기를 자랑한다
FP/SIMD Register File도 이에 걸맞는 430 entries를 보여준다
Scheduler 또한 범상치 않은 entries를 가지고 있다
쉽게 말해 모든 부분이 거대하다는 뜻이다
이것이 도대체 얼마나 넓은건가 궁금할수도 있을것이다
그래서 동시대 인텔이 사용중이던 microarchitecture를 가져와봤다
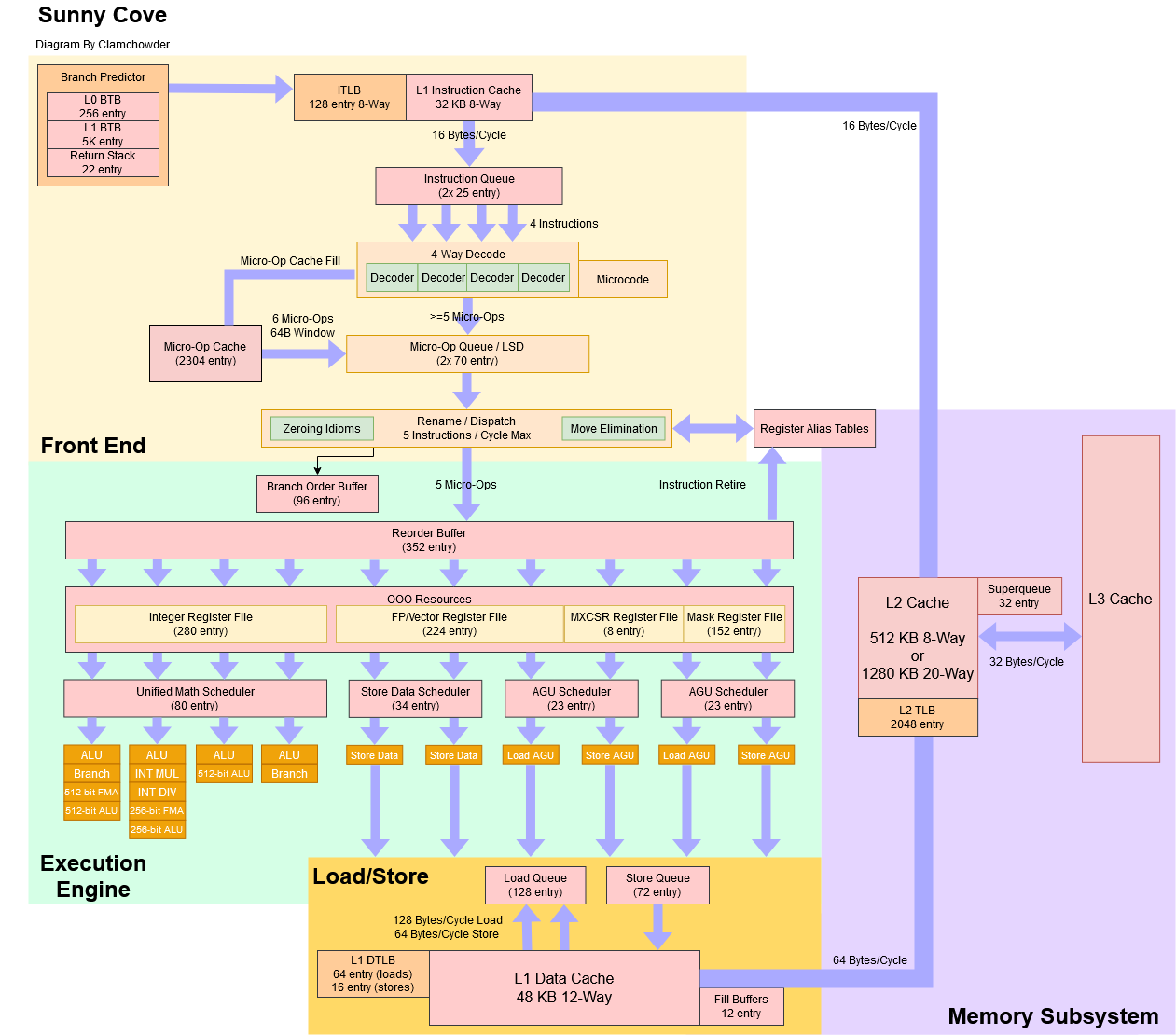
https://chipsandcheese.com/2022/06/07/sunny-cove-intels-lost-generation/
사실 발표는 2019년도긴한데, 인텔 11세대(21년도 3월 출시)에 들어간 architecture라 들고왔다
잘보면 5-way Decoder를 사용한다
사실 이것도 지난 수년동안 4-way Decoder을 사용하다가 10nm로 넘어가면서 확장한것이라고 한다
그리고 Decoder에 이어 Reorder Buffer도 350 entires에 그치는 모양이다
마찬가지로 Integer PRF와 FP/Vector PRF도 각각 280/220 entries에 머무르고 있다
M1의 모든 부분들이 Intel에 비해 1.5배 ~ 2배는 더 커보인다
이러한 Wide pipeline을 놓고 AnandTech에서는 "Humongous"라는 표현을 사용했을 정도다
물론 Intel도 가만히 있지는 않았고 이듬해에 12세대를 출시하며 6-way Decoder를 도입하였다
그렇다면 이러한 Wider pipeline이 성능과 효율에 어떤 영향을 주는 것일까
사실 이 부분에서는 명쾌한 답변을 얻기란 힘들다
앞에서도 말했지만 CPU라는 물건이 그렇게 쉽게 계산되는 물건은 아니기 때문이다
그래도 외국 커뮤니티를 탐방하며 꽤 그럴듯한 답변들을 얻을 수 있었다
https://news.ycombinator.com/item?id=25163883
- 한번에 더 많은 instruction을 Fetch 할 수 있다
- 더 많은 instruction을 CPU가 볼 수 있기에 Branch prediction에 유리하다
- 더 많은 instruction을 한번에 fetch함으로써 Parallel execution에 유리하다
그리고 개인적인 생각으로는 이러한 유리한 위치를 바탕으로 효율성 또한 향상시킬 수 있다고 보았다
굳이 클럭을 올리려 발악하지 않아도 충분히 성능을 챙길 수 있기 때문이다
다만, 이걸 위해서는 모든게 거대해져야 한다는 문제가 발생한다
어찌되었건 Apple Silicon은 모든것을 거대하게 키워서 성공했다
그렇다면 Intel 또한 이러한 거대한 Pipeline의 도입으로 성능을 향상시킬 수 있지 않을까
해당 이유에 대해서 정확하게 알기는 힘들지만 못했다고 보는편이 맞지않을까 싶다
그리고 그 이유는 미세공정을 살펴보면 알 수 있다
https://www.reddit.com/r/intel/comments/13t1xir/why_many_decoders_are_not_possible_in_x86_or_amd/
Semiconductor process
애플은 자체적으로 CPU를 설계하기 시작하면서 항상 최선단 공정을 사용해왔다
물론 애플의 엄청난 물량과 자본이 있기에 가능한일이기도하다
그리고 이러한 공정 우위는 애플에게 더 높은 집적도를 주었다
이러한 직접도의 우위가 여실히 나타나는 제품군이 바로 Apple Silicon이다
약 120mm2의 Die size에 16B transistor을 때려박는데 성공했다
동일시기에 Intel 14nm++ 공정으로 출시했던 i9-11900를 살펴본다면 270mm2에 6B로 추정된다
2공정 차이로 인해(인텔의 주장에 따르면) 거의 6배에 달하는 집적도의 차이를 보여준다
물론 M1은 SoC이기에 저 모든 transistor가 CPU로 향하는것은 아니다
Intel i9-11900의 경우 Core당 약 4.7%의 공간을 차지하고, M1은 약 1.9% 정도라고 한다
이를 토대로 계산해보면 Intel의 경우 0.28B가 나오고, 0.3B가 나오게 된다

https://youtu.be/8bf3ORrE5hQ?t=736&si=f-OzrxjhsWQS2Iio
https://www.techinsights.com/blog/two-new-apple-socs-two-market-events-apple-a14-and-m1

https://youtu.be/rBTb1tM0SDY?si=6ZWg3pvouOFuYTl5&t=235
https://realhardwarereviews.com/i9-11900k-i5-11600k-review/2/
이렇게만 본다면 약 7% 정도의 차이밖에 안난다고 볼 수도 있을 것이다
그런데 영상을 잘보면 11900의 계산에서는 L2-Cache가 포함된 수치이고, M1은 제외된 수치다
11900에서 L2-Cache가 어림잡아 10~20% 정도 차지하는것을 고려해볼때 무시못할 수치이다
물론 이와 같은 계산은 오차 위에 오차를 쌓는 굉장히 무식한 행동이다
그냥 재미로 이정도 차이가 나는구나를 봐주면 될 것 같다
어찌되었건 이러한 공정우위는 집적도의 향상을 가져올 수 있었다
그 말인즉슨, 애플은 더 넓은 Pipeline을 넣을 수 있었다는 것이다
어쩌면 애플에게는 성능과 효율성이라는 두가지 키워드중 선택할 수 있는 기회가 주어졌을지도 모른다
그리고 만약 애플이 성능이라는 키워드에 집중했다면 어떠한 결과가 나왔을지는 아무도 모른다
물론 애플은 성능보다는 효율성을 택하며 더 많은 집적도로 더 높은 효율성을 선보였다
There's no such thing as unicorn
지금까지 고려한 사항들을 쭉 훑어본다면 놀랍게도 M1의 마법은 더 이상 보이지않는다
단지 애플이라는 거대 기업이 엄청난 돈과 시간을 쏟아부워 만들어낸 최고수준의 결과물만 보일 뿐이다
물론 M1을 위한 노력들이 이러한 미세공정이나 microarchitecture에만 존재하는 것은 아니다
SoC의 모든 부분에서 쥐어짜낸 사실을 본다면 애플의 설계자들이 정말 경이로울 정도다
그리고 그들이 최고의 경험을 선사하기 위해 다양한 조합을 섞었다는 사실도 잊어서는 안될 것이다
하지만 그 과정에서 정말 새롭고 혁신적인 개념이 등장하지는 않는다
다시 돌아와 이글의 처음 질문에 대답할 차례인것 같다
과연 ARM은 x86 보다 좋을까?
정답은 "어떤 설계를 하느냐에 달려있다"이다
(igormp님과 Nystemy님의 답변을 참고하면 좋다)
https://linustechtips.com/topic/1295196-is-arm-really-more-efficient-than-x86-64-or-is-it-much-more-about-optimization-from-top-to-bottom/
이제 CPU는 더 이상 천재적인 발상 혹은 설계로 판가름 할 수 없게 되었다
모든것이 유기적으로 연결된 어쩌면 세상에서 가장 복잡한 기계일지도 모른다
그리고 설계하는 사람의 목적에 따라 모든 부분을 효율적으로 설계할수도, 성능에 집중할수도 있다
모든것은 물리법칙 아래 존재하며, 적당한 타협선을 찾아야한다
이러한 타협선은 ISA나 어떤 개념에 의해 제한받는 것이 아니다
만약 다른 진영에서 도입한 개념이 좋다면 자신들도 나름의 솔루션으로 도입하면 그만이다
물론 기술자들이 갈려나겠지만..지금까지 CPU가 그렇게 발전해왔다..
물론 ARM과 Intel이라는 기업의 관점에서 본다면 이야기가 상당히 쉬워진다
ARM은 효율에 집중하고 있는 형태이고, Intel은 그 반대이다
대신 이들은 하나에 키워드에 집중하는 만큼 다른 키워드를 희생해야했다
애플이라는 기업은 이들처럼 어느하나 키워드를 희생시키기 싫었던것 같다
그래서 그들은 엄청난 돈을 쏟아부워 남들보다 한발자국 앞서서 나아갔다
그리고 그 결과가 현재 우리가 마주한 Apple Silicon일 것이다
자료조사하다가 발견한 사실 중 재밌는게 있어서 남겨본다
인텔 12세대 CPU에서 35W의 전력소모로 M1 Max와 비슷한 성능을 보여준 사례가 있다
환경이나 조건이 굉장히 다르기에 어떻다 할 순 없겠지만 상당히 흥미로운 결과이긴했다
https://www.reddit.com/r/hardware/comments/qo41ss/this_intel_12th_generation_cpu_is_a_bit_strong/
위 링크 중 2017년도 Chandler Carruth님 강연 영상 마지막에 흥미로운 질문이 등장한다
그리고 모두가 알다싶이 2018년도에 인텔 게이트가 터졌다
그래서 첫번째 댓글을 보면 마지막 질문에 대한 아쉬움을 표현한다
그래서인지는 몰라도, 2018년도에 Chandler Carruth님의 인텔 게이트 강연 영상을 하셨다
그리고 해당 영상 초반에 17년도 마지막 질문에 대한 아쉬움을 표현한다
자료조사하면서 참고한 글/영상들
https://www.itworld.co.kr/news/308527
https://linustechtips.com/topic/1295196-is-arm-really-more-efficient-than-x86-64-or-is-it-much-more-about-optimization-from-top-to-bottom/
https://www.extremetech.com/extreme/323245-risc-vs-cisc-why-its-the-wrong-lens-to-compare-modern-x86-arm-cpus
https://www.extremetech.com/extreme/188396-the-final-isa-showdown-is-arm-x86-or-mips-intrinsically-more-power-efficient
https://www.youtube.com/watch?v=4b9i2Ndxr7I&list=PL5Q2soXY2Zi97Ya5DEUpMpO2bbAoaG7c6&index=17&t=3244s
https://www.youtube.com/watch?v=8bf3ORrE5hQ&t=736s
https://eclecticlight.co/2021/12/07/comparing-performance-of-m1-chips-4-icestorm/
https://www.anandtech.com/show/16226/apple-silicon-m1-a14-deep-dive/2
https://news.ycombinator.com/item?id=25163883
https://www.reddit.com/r/intel/comments/13t1xir/why_many_decoders_are_not_possible_in_x86_or_amd/
https://www.youtube.com/watch?v=-2B-KKQeQ0M&t=362s

좋은 글 잘 보고 갑니다.