
초록스터디 강의 자료 정리
객체지향 ←→ 관계형 데이터 구조 | Spring ←→ RDB
객체지향
- 시스템을 구성하는 객체들에게 적절한 책임과 역할을 할당함
- 상속
- 연관 관계 객체 그래프: Member → Team → League
class Member { Long id; String name; Team team; } class Team { Long id; String name; League league; } class League { Long id; String name; }
관계형 데이터베이스 구조
- 데이터를 정규화 하여 저장
Member, Team, League 저장
CREATE TABLE member (
id unsigned BIGINT PRIMARY KEY,
name VARCHAR(255),
-- team TEAM ... 는 불가능
team_id BIGINT
)
CREATE TABLE team (
id unsigned BIGINT PRIMARY KEY,
name VARCHAR(255),
// league LEAGUE ... 는 불가능
league_id BIGINT
)
// ...
객체를 활용하는 애플리케이션을 기준으로 DB를 구성할 순 없음.
적당히 모방하여 RDBMS에 맞게 구성 해야함 (ex. type → 연관관계 FK 사용)
객체
Member royce = new Member("Royce")
// 객체 그래프 매핑
League league = royce.getTeam().getLeague() // member -> team -> league 접근 가능// 쿼리를 언제까지..
SELECT * FROM member WHERE id = ?;
SELECT * FROM team WHERE id = ?;
SELECT * FROM league WHERE id = ?;class Member {
Long id;
String name;
String email;
String role;
}
// 조회 쿼리
String sql = "SELECT id, name, email, role FROM member WHERE id = ?";
connection.prepareStatement(sql);
// 객체 변경 사항 발생
class Member {
Long id;
String nickName;
String email;
String role;
String ageband;
}
// 모든 쿼리 수정...public Member findById(Long id) {
return jdbcTemplate.queryForObject(
"SELECT id, name, email, role FROM member WHERE id = ?",
(rs, rowNum) -> new Member(
rs.getLong("id"),
rs.getString("name"),
rs.getString("email"),
rs.getString("role")
), id
);
}
Member memberA = findById(1L);
Member memberB = findById(1L);
memberA.equals(memberB) // false
// 하지만, DB에선 PK가 같으면 동일함!ORM, JPA
Object-Relational Mapping
객체와 관계형 데이터베이스의 데이터를 자동으로 매핑해주는 기술
ex) Member 객체를 기준으로 데이터베이스에 맞게 매핑
// AS-IS
String sql = "SELECT id, name, email, role FROM member WHERE id = ?";
connection.prepareStatement(sql);
// TO-BE
Member member = memberRepository.findById(id);jdbcTemplate을 활용해도 rowMapper를 통해 객체 기준으로 접근이 가능하다. (혹은 MyBatis)
but, ORM은 개발자가 작성하는 SQL까지도 분리 시켜준다.
Nest에는 TypeORM, python의 SQLAlchemy 등 프레임워크 마다 ORM기술을 다양하게 지원하고 있다.
Java에서는 → JPA (Java Persistence API)
ORM, JPA(Hibernate)
Hibernate는 JPA의 구현체이다
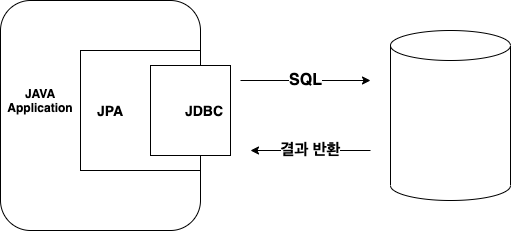
Your relational data. Objectively. - Hibernate ORM
[10분 테코톡] ⏰ 아마찌의 ORM vs SQL Mapper vs JDBC
Spring Data JPA
SQL 구문 작성 없이 연결된 DB에 대해 데이터 접근 및 조작이 가능하다!
EntityManager em = entityMangagerFactory.createEntityManger();
// insert
em.persist(member);
// select
Member member = em.find(Member.class, 1);
// update
member.setName("kokodak");
// delete
em.remove(member);EntityManager 클래스를 통해 SQL 구문 작성 없이 객체를 기준으로 데이터 조작이 가능해졌다.
Spring Data JPA를 통해 더 간략하게 활용해보자.
Spring Data JPA
Spring Data JPA :: Spring Data JPA
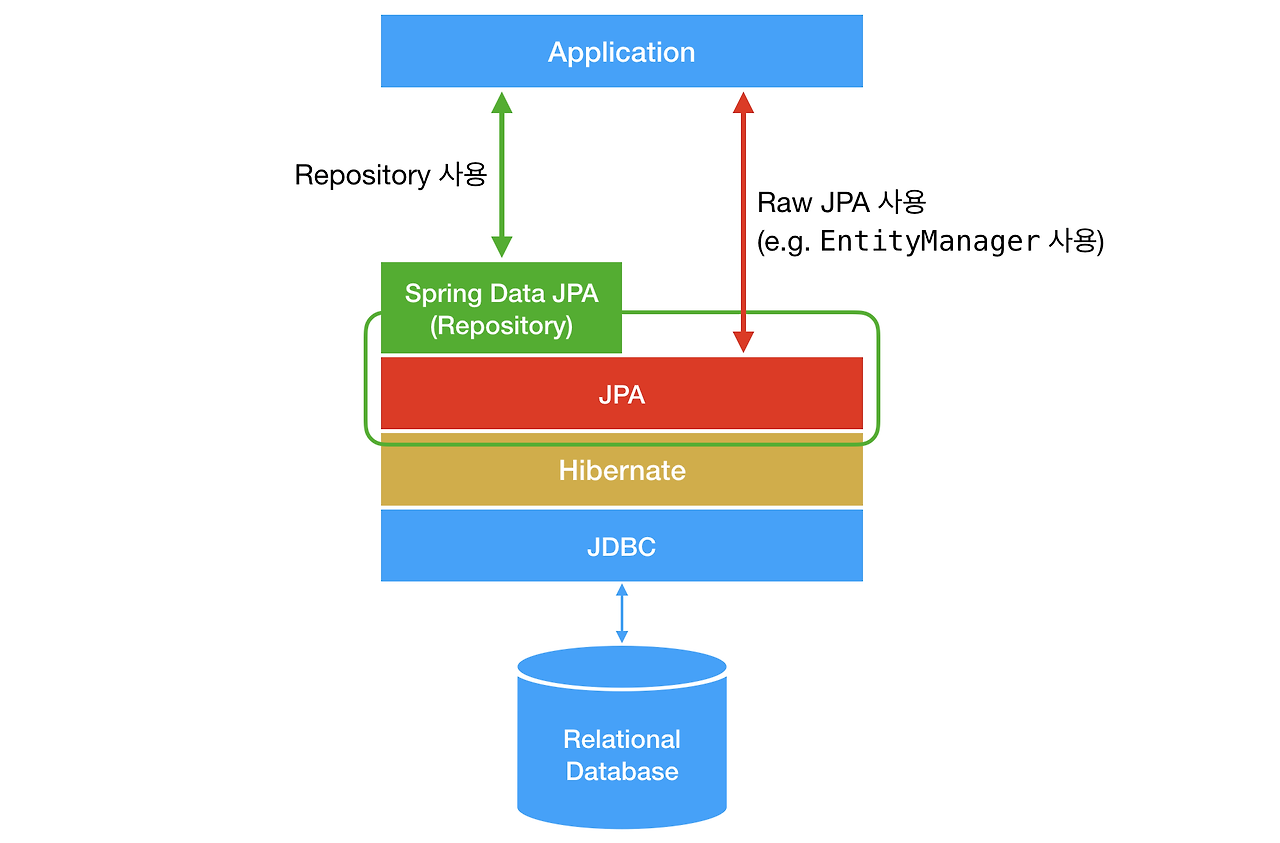
JPA와 다른 기술이 아닌, JPA에 대한 리포지토리 지원을 제공한다. 애플리케이션을 쉽게 개발할 수 있다고 한다.
JPA를 사용할 때, 영속화가 필요한 객체마다 findById(), findAll(), delete(), save(), … 등의 메서드를 매번 정의해야하는 반복 작업이 존재한다.
Spring data JPA를 활용하여 더 효율적으로 사용하자.
// AS-IS
class MemberRepository {
EntityManager em = entityMangagerFactory.createEntityManger();
// select
public Member findById(Long id) {
Member member = em.find(Member.class, id);
}
// insert
public void save(Member member) {
em.persist(member);
}
// update ...
// delete ...
}
class TeamRepository {
// findById()
// save()
// ...
}// TO-BE
interface MemberRepository extends JpaRepository<Member, Long> {
Member findByNmae(string name); // query method
}JPA Query Methods :: Spring Data JPA
메서드 이름을 기반으로 쿼리를 만들어준다!
Spring data JDBC 도 있다. 이 역시 Repository 지원을 제공하지만 JPA기술이 적용 되진 않는다.
Spring Data JDBC and R2DBC :: Spring Data Relational
영속성 컨텍스트
객체를 완전 자동으로 참고하여 Sql을 작성해주진 않는다. 몇가지 설정들이 필요한데, 우선 객체를 엔티티로 정의하는 방법에 대해 알아야 한다.
@Entity // -- 1
public class Member {
@Id // -- 2
@GeneratedValue(strategy = GenerationType.IDENTITY) // -- 3
private Long id;
@Column(name = "name", nullable = false, length=20, unique=false) // -- 4
private String name;
protected Member() { // -- 5
}
}-
엔티티 클래스임을 지정. 테이블과 매핑한다.
-
기본 키를 애플리케이션에서 엔티티클래스에 직접 set하여 사용. (DB의 PK를 매핑해줌)
-
Id 생성 전략 지정 (
IDENTITY는 DB에 생성 전략을 사용) -
컬럼에 대한 설정 정의
-
파라미터가 없는 기본 생성자 필수!
- 더 많은 Entity 정의 어노테이션s Defining JPA Entities | Baeldung Spring JPA 관련 주요 Annotation 및 설정
@Entity 를 사용하여 테이블과 매핑 될 수 있도록 설정하였다.
ddl-auto: validate를 설정하여 테이블과의 매핑을 검증 할 수 있다.
또, Entity는 EntityManager 를 통해 저장/조회 시, 영속성 컨텍스트에 보관하고 관리한다.
영속성 컨텍스트는 엔티티를 저장하는 환경 (DB와 다름)
Member member1 = new Member("member1");
memberRepository.save(member1);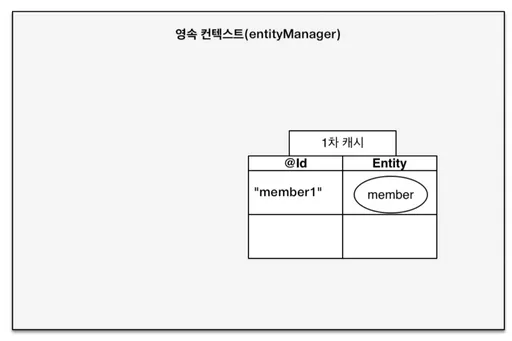
memberRepository.findById("member1");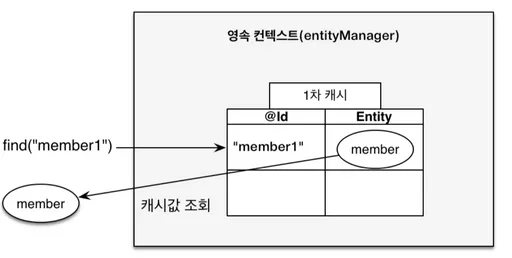
// DB에는 존재
memberRepository.findById("member2");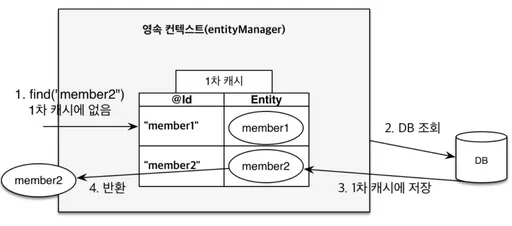
영속성 컨텍스트의 역할
- 1차 캐시
- 동일성 보장
- 트랜잭션을 지원하는 쓰기 지연
- 변경 감지
- 지연 로딩
- …
트랜잭션을 지원하는 쓰기 지연
쓰기 지연 SQL 저장소에 트랜잭션에서 수행된 쿼리를 저장한다.
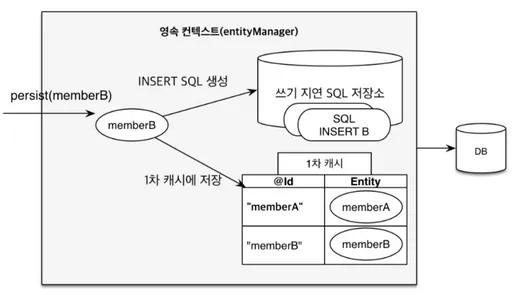
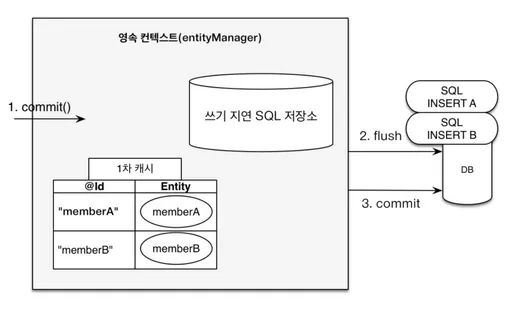
commit 시, DB에 적용
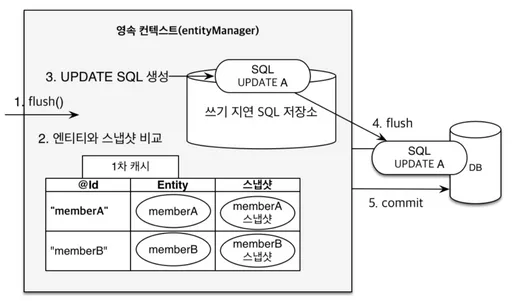
변경 감지
update는 없음!
엔티티의 생명주기
- 비영속(new/transient): 영속성 컨텍스트와 전혀 관계가 없는 상태
- 영속(managed): 영속성 컨텍스트에 저장된 상태
- 준영속(detached): 영속성 컨텍스트에 저장되었다가 분리된 상태
EM의 관리를 받지 못함 (Transaction이 끝나는 경우)
merge(병합)에 대해 알아보면 좋다. - 삭제(removed): 삭제된 상태
어렵다… 다 알고 써야할까?
쓰면서 알아가면 된다고 생각
연관관계 매핑
엔티티들은 대부분 다른 엔티티와 연관 관계가 있다.
객체는 참조(주소)를 사용해서 관계를 맺고, 테이블은 외래 키를 사용해서 관계를 맺는다.
키워드
- 방향: 단방향, 양방향이 있다. 방향은 객체 관계에만 존재하고 테이블 관계는 항상 양방향이다.
- 테이블은 외래 키 하나로 양 쪽 테이블 조인이 가능
- 객체는 참조용 필드가 없으면 참조 불가 (방향성 존재)
- 다중성: 다대일(N:1), 일대다(1:N), 일대일(1:1), 다대다(N:M)
- 연관 관계의 주인: 객체를 양방향 연관 관계로 만들면 연관 관계의 주인을 정해야 한다.
데이터 관계도
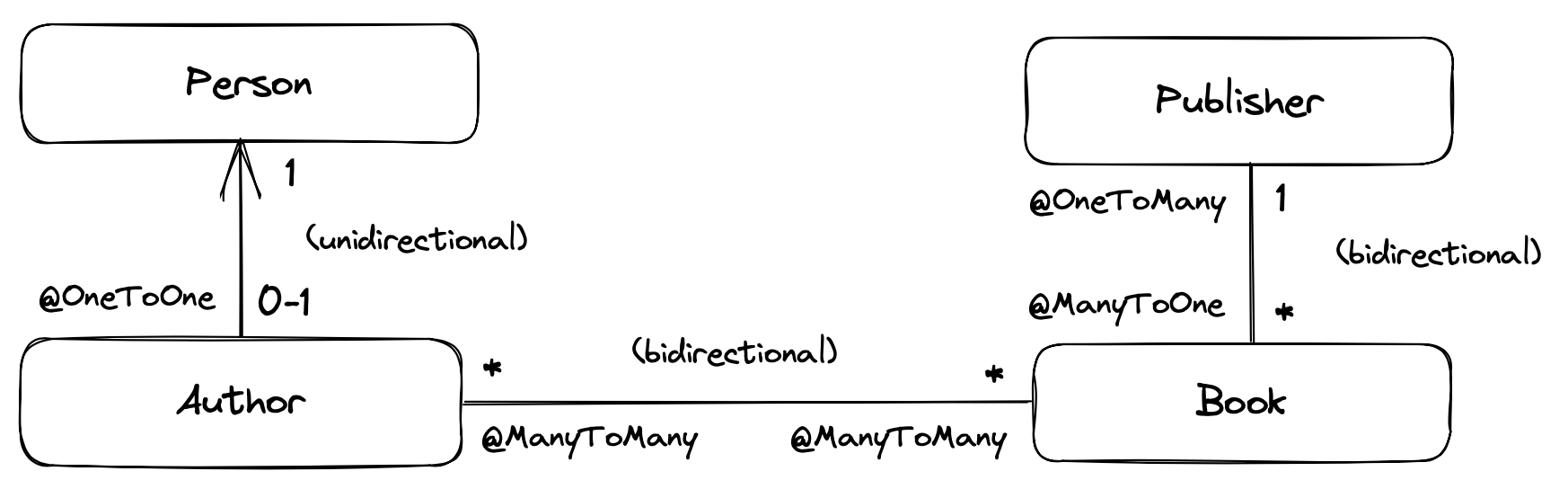
- 일대일 관계 (1:1) Person - Author 단방향: Author.person() 으로 접근 가능. table은 조인을 통해 양쪽에서 접근 가능
양방향@Entity class Author { @Id @GeneratedValue Long id; @OneToOne Person person; } @Entity class Person { @Id @GeneratedValue Long id; }@Entity class Author { @Id @GeneratedValue Long id; @OneToOne Person person; } @Entity class Person { @Id @GeneratedValue Long id; @OneToOne(mappedBy = "author) Author author; } - 일대다 관계 (1:N) Publisher(1) - Book(N) 테이블 구조에서는 다(N)인 Book에서 publisher 테이블의 PK를 외래 키로 갖도록 설계 하는 것이 일반적임 Publisher
Bookid name 1 pub
이 경우, 객체 설계는 단방향, 양방향으로 설계 할 수 있다.id name publisher_id 1 book1 1 2 book2 1 3 book3 1
만약, Application에서 Publisher를 기준으로 book을 조회하는 경우가 많다면? 양방향 다대일 연관관계 매핑@Entity class Book { @Id @GeneratedValue Long id; @ManyToOne Publisher publisher; // ... } // Book -> Publisher (as publisher_id)
Publisher → Book 양방향 관계를 설정하고 매핑 정보를 사용하기 위해@Entity class Publisher { @Id @GeneratedValue Long id; @OneToMany(mappedBy="publisher") Set<Book> books; // ... }mappedBy를 사용해야 한다. 연관관계 주인 ⇒ DB 외래키 관리자 (현재는 Book)-
연관 관계의 주인만이 데이터베이스 연관 관계와 매핑되고 외래 키를 등록, 수정, 삭제할 수 있다.
-
주인이 아닌 쪽은 읽기만 할 수 있다. (Publisher)
-
- 다대다 관계 (N:M)
@ManyToMany로 지정@Entity class Book { @Id @GeneratedValue Long id; @ManyToMany Set<Author> authors; // ... }@Entity class Author { // ... @ManyToMany(mappedBy="authors") Set<Book> books; // ... }@ManyToMany로 Entity를 정의하면다대다임을 표현할 수 있지만, 관계형 데이터베이스에는 해당 개념을 표현하지 못함. 이를 해결하기 위해연결 테이블(중간 테이블)을 사용하여 관계를 표현해야 함.@ManyToMany를 통해서도 설정이 가능하지만, 이렇게 구성하면연결 테이블에 컬럼을 추가할 수 없음 따라서, 연결 테이블 역할을 할 수 있는 엔티티 클래스를 도입하여 해결.@Entity class BookAuthor { @Id @GeneratedValue Long id; @ManyToOne Book book; @ManyToOne Author author; }@Entity class Book { @Id @GeneratedValue Long id; @OneToMany(mappedBy = "book") Set<BookAuthor> authors; // ... }@Entity class Author { // ... @OneToMany(mappedBy="author") Set<BookAuthor> books; // ... }Authorid name 1 Lulu Miller 2 George Orwell BookAuthor(연결 테이블)id author_id book_id 1 1 1 2 2 2 3 2 3 Bookid name 1 물고기는 존재하지 않는다 2 1984 3 동물농장
장단점
장점
-
생산성 증가
보일러플레이트 쿼리를 작성하지 않아도 됨 (+ 레포지토리 메서드) -
컴파일 체크
문자열로 작성하는 SQL은 컴파일체크를 지원하지 않음 (ex.“SELECT * FROM memeeeber WHERE member_id = 3”)
JPA를 통해 제공되는 메서드를 문자열로 작성하는 SQL 쿼리보다 신뢰할 수 있음. -
변경 대처 가능
객체의 필드에 대한 수정이 발생하면, 관련된 모든 쿼리에서 수정이 요구됨
엔티티를 기준으로 쿼리를 생성해주기 때문에 알아서 변경 사항이 반영됨 -
DB 벤더사로부터의 유연성
H2,MySql,Postgreql,Oracle등 다양한 DB 벤더마다 고유한 문법이 존재함
JPA(PI)는 추상화된 Data access 계층을 제공하기 때문에 벤더사 마다의 고유한 문법(방언)에 종속적이지 않음
단점
- 내부적인 동작이 많아 성능적인 이슈가 발생할 수 있음
명확한 개념인지를 통해 대응이 가능해야함 - 러닝커브
- JPA로 해결 되지 않는 복잡한 쿼리는 결국 JPQL 혹은 native query (SQL)로 해결해야 함

정리를 짱 잘해주셨네요! 팬이에요