Tree
자료구조 표현
자료구조라고 하면, 보통 데이터 저장방식이나 검색 및 삭제의 방식에 따라 정의되는 경우가 많다.
"구조"라고 하면 앞서 말한 내용들에 초점이 맞춰져 있기 때문이다.
하지만, 자료구조는 근본적으로 어떤 데이터의 "표현"을 위한 도구이다.
그런 도구가 저장이나 삭제, 검색등의 기능을 제공하는 것으로 이해하는 것이 맞다고 한다.
트리
트리는 계층적 관계를 표현하는 자료구조이다
어떤 계층을 표현하고 있다면, 모두 트리라고 이해할 수 있다. 실생활에서도 집안의 족보나 조직도, 혹은 컴퓨터의 디렉토리 구조 또한 트리라고 할 수 있다.
ex). 디렉토리 구조

트리 용어
트리 구조에서 사용되는 용어들은 다음과 같다.
-
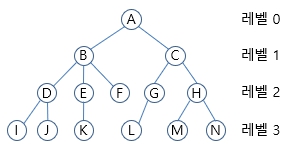
노드 (Node)
트리를 구성하는 요소
A B C D E F G H I J K L M N
-
간선 (Edge)
노드와 노드를 연결하는 연결선
-
루트 노드 (Root Node)
트리 구조에서 최상위에 존재하는 노드
A
-
단말 노드 (Terminal Node)
아래로 또 다른 노드(자식)가 없는 노드
I, J, K, L, M, N
-
내부 노드 (Internal Node)
단말 노드가 아닌 노드
A, B, C, D, E, F, G, H
-
서브 트리 (Subtree)
트리의 트리
A의 서브 트리는 B를 루트로 하는 트리
-
자식, 부모, 형제 (Child, Parent, Sibling)
노드 B
자식 노드 : D, E, F
부모 노드 : A
형제 노드 : C
-
경로 (Path)
한 노드에서 다른 노드로 이동할 때, 거치는 노드들의 순서
I -> E의 경로
I - D - B - E
-
경로 길이 (Length)
경로에서 거치는 노드의 갯수
I -> E의 길이 : 4
-
깊이 (Depth)
루트로부터 해당 노드까지의 경로 길이
K 노드의 깊이
A -> B -> E -> K
깊이 : 4
-
높이 (Height)
단말 노드로부터 해당 노드까지의 경로 길이
G노드의 높이
L -> G
높이 : 2
-
레벨 (Level)
깊이가 동일한 노드들
레벨 1: A
레벨 2: B, C
레벨 3: D, E, F, G, H
이진 트리
- 루트 노드를 중심으로 두 개의 서브트리로 나뉘어진다
- 나뉘어진 두 서브 트리도 모두 이진 트리이어야 한다.
이진 트리 설명에 이진 트리라는 단어가 등장한다. 이진 트리가 재귀적이라는 것을 알 수 있다.

이진 트리에서는 공집합 트리라는 것이 존재한다.
공집합 노드는 노드가 위치할 수 있는 곳에 노드가 없는 곳을 말한다.
만약 노드의 자식이 한 개만 존재하더라도, 다른 한 쪽엔 공집합 노드가 있다고 이해하고 이진 트리라고 인정하는 것이다.
![자료구조 - [Tree]이진 트리](https://t1.daumcdn.net/cfile/tistory/2626C63F57221B4602)
포화 이진 트리 / 완전 이진 트리
이진 트리를 다음과 같이 나눌 수 있다
포화 이진 트리는 모든 레벨이 이진트리로 꽉 차서, 노드를 추가하려면 레벨이 늘어나는 경우이다.
말은 어렵지만 그림으로 보면 쉽게 이해가 가능하다

완전 이진 트리는 레벨이 모두 차있진 않지만, 모든 노드의 자식들이 채워진 이진 트리를 말한다

이진 트리의 구현
배열을 이용하면 우선순위 트리(Heap)에 유용하지만, 일반적으로 계층과 간선을 표현하기엔 연결리스트를 이용한다.
#ifndef DATASTRUCTURE_BINARYTREE_H
#define DATASTRUCTURE_BINARYTREE_H
typedef int BTData; //data Type
typedef struct _bTreeNode {
BTData data;
struct _bTreeNode *left; //왼쪽 노드
struct _bTreeNode *right; //오른쪽 노드
} BTreeNode;
//Tree는 이전 자료구조와는 다르게 Tree라는 구조체를 따로 선언하지 않음
//BTreeNode의 선언이 곧 Tree이기 때문.
BTreeNode *MakeBTreeNode(void);
BTData GetData(BTreeNode *bt);
void SetData(BTreeNode *bt, BTData data);
BTreeNode *GetLeftSubTree(BTreeNode *bt);
BTreeNode *GetRightSubTree(BTreeNode *bt);
void MakeLeftSubTree(BTreeNode *main, BTreeNode *sub);
void MakeRightSubTree(BTreeNode *main, BTreeNode *sub);
//순회 방식 설정
typedef void VisitFuncPtr(BTData data);
//전위 순회
void PreorderTraverses(BTreeNode *bt, VisitFuncPtr action);
//준위 순회
void InorderTraverses(BTreeNode *bt, VisitFuncPtr action);
//후위 순회
void PostorderTraverses(BTreeNode *bt, VisitFuncPtr action);
//노드 삭제
//서브트리의 모든 노드를 제거하기 위해 순회하며 제거하는 로직 필요
void DeleteTree(BTreeNode *bt);
#endif //DATASTRUCTURE_BINARYTREE_HTree라는 구조체를 따로 선언하진 않는다. 왼쪽, 오른쪽 자식을 가리키는 노드가 곧 하나의 트리이기 때문이다.
여기서 살펴볼 점은 순회 방식이다.
이진 트리를 어디서부터, 어떻게 순회(방문)할지에 따라 순회방식이 나뉜다.
-
중위 순회 : 왼쪽 아래부터 시계방향으로 순회
순회 결과 : (D -> B -> E) -> A -> (F -> C -> G)
-
후위 순회 : 왼쪽 아래부터 반시계 방향으로 순회
순회 결과 : (D -> E -> B) -> (F -> G -> C) -> A
-
전위 순회 : 루트 노드부터 반시계 방향으로 순회
순회 결과 : A -> (B -> D -> F) -> (C -> F -> G)
//전위 순회
// 1 2 4 3
void PreorderTraverses(BTreeNode *bt, VisitFuncPtr action) {
if(bt == NULL)
return;
action(bt->data);
PreorderTraverses(bt->left, action);
PreorderTraverses(bt->right, action);
}
//중위 순회
//4 2 1 3
void InorderTraverses(BTreeNode *bt, VisitFuncPtr action) {
if(bt == NULL)
return;
InorderTraverses(bt->left, action);
action(bt->data);
InorderTraverses(bt->right, action);
}
//후위 순회
//4 2 3 1
void PostorderTraverses(BTreeNode *bt, VisitFuncPtr action) {
if(bt == NULL)
return;
PostorderTraverses(bt->left, action);
PostorderTraverses(bt->right, action);
action(bt->data);
}