
1. 데이터 확인
1-1. 데이터 형태

16598개의 데이터가 있었고, 9개의 컬럼이 있었다.
1-2. 결측치 및 타입 확인
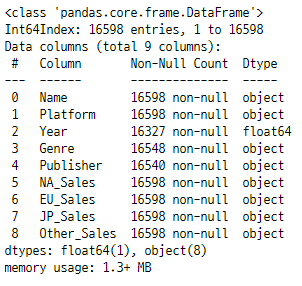
Year, Genre, Publisher에 결측치가 있는 것을 확인했고, Sales의 데이터가 float형이 아니라 object형이므로 이상치가 있을 것으로 예상했다.
1-3. Year 이상수치 확인
# 년도 데이터 이상수치 확인 및 담아두기
year = df.Year.unique()
temp = []
for i in year:
if i <= 1900:
print(i)
temp.append(i)
Year의 데이터를 확인해보니 년도의 뒷자리만 있는 데이터가 있었다.
그래서 게임명을 확인해보고 검색했더니 80이상은 1900년도 이하는 2000년도라는 것을 알 수 있었다.
1-3-1. Year 데이터 통일화
# 데이터 수치 통일화를 위해서 년도 데이터 변경
df.loc[(df.Year.values <= 80), 'Year'] += 2000
df.loc[((df.Year.values >= 80) & (df.Year.values <= 100)), 'Year'] += 1900
# 변경확인
df.Year.value_counts()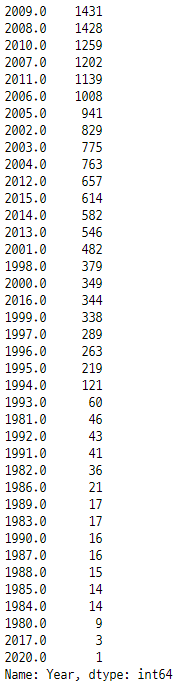
정상적으로 변경된 것을 볼 수 있다.
1-3-2. Year 데이터 결측치 확인
# 년도 결측치 확인
names_list = []
platform_list = []
for x, y in zip(df.loc[(df.Year.isna()), 'Name'], df.loc[(df.Year.isna()), 'Platform']):
names_list.append(x)
platform_list.append(y)
print(names_list[-3:])
print(platform_list[-3:])
#
# out
# ['Madden NFL 11', 'Yoostar on MTV', 'Bejeweled 3']
# ['Wii', 'X360', 'X360']Year가 결측치인 게임 이름과 기기명을 수집해서 채우기 위해 새로운 데이터 프레임을 만들었다.
na_years_df = pd.DataFrame({"Name" : names_list,
"Platform" : platform_list, "Year" : 0})
na_years_df.head()
1-3-3. Year 결측치 수집
from selenium import webdriver
import time
from bs4 import BeautifulSoup
driver = webdriver.Chrome('chromedriver.exe')
# platform name release date로 검색
for name, platform in zip(names_list, platform_list):
driver.get('https://www.google.com/search?q={}'.format(platform + ' ' + name + ' ' + "release date"))
time.sleep(3)
try: # xxxx년 xx월 xx일 데이터 수집
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
date = soup.select('div.Z0LcW.XcVN5d')
year = date[0].text.split(" ")[0].replace("년", '').strip()
na_years_df.loc[na_years_df.Name.values == name, 'Year'] = int(year)
except:
try: # x월 x일 x년 데이터 수집
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
date = soup.select('div.Z0LcW.XcVN5d')
year =date[0].text.split(" ")[-1].strip()
na_years_df.loc[na_years_df.Name.values == name, 'Year'] = int(year)
except: # 못담을 경우 0으로 처리
na_years_df.loc[na_years_df.Name.values == name, 'Year'] = 0
driver.quit()
na_years_df.to_csv('na_years.csv', index=False) # 수집후 저장selenium 패키지를 통해 크롤링 수집했지만 완전히 수집하진 못함.
결국 나머지 데이터에 크롤링 + 수작업을 진행
for x, y in zip(na_years_df.loc[(na_years_df.Year == 0), "Name"],
na_years_df.loc[(na_years_df.Year == 0), "Platform"]):
# platform name release date로 검색
driver.get('https://www.google.com/search?q={}'.format(y+ ' ' + x + ' ' + "release date"))
# 검색해서 띄우고 입력받기
year = int(input('year : '))
# 입력받은 데이터 저장
na_years_df.loc[na_years_df.Name == x, 'Year'] = year# 크롤링한 데이터 결측치 위치에 대체
for x, y, z in zip((na_years_df.Name.values),
(na_years_df.Platform.values),
(na_years_df.Year.values)):
df.loc[((df.Name == x) & (df.Platform == y)), 'Year'] = z
df.Year.isna().sum()
#
# 01-4. Genre 결측치 수집
1-4-1. Genre 결측치 확인
genre_list = df.Genre.unique()
df.loc[df.Genre.isna()]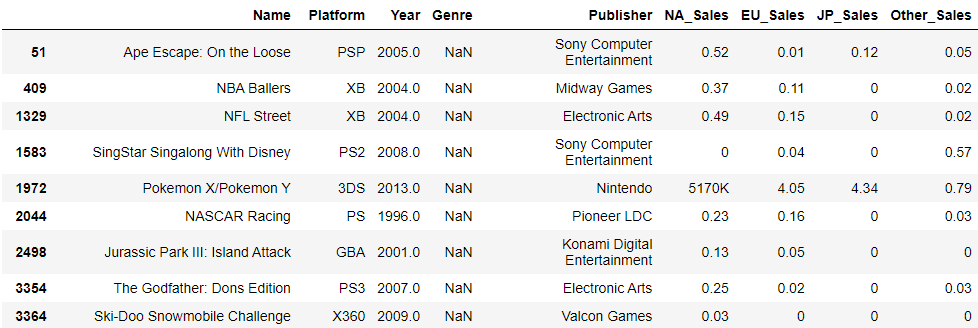
1-4-2. Genre 결측치 Name list 만들고 수집
names_list = []
for name in df.loc[df.Genre.isna(), 'Name']:
names_list.append(name)
names_list[-3:]
#
# ['Cars: Mater-National Championship',
# 'Apache: Air Assault',
# 'Need for Speed Underground 2']driver = webdriver.Chrome('chromedriver.exe')
for x in names_list:
# name genre로 검색
driver.get('https://www.google.com/search?q={}'.format(x + " " + "genre"))
# genre 데이터 입력받기
genre = input('Genre : ')
# 입력받은 데이터 저장
df.loc[((df.Genre.isna()) & (df.Name == x)), 'Genre'] = genre
driver.quit()
df.Genre.isna().sum()
#
# 0df.loc[df.Genre == 'Playing', 'Genre'] = 'Role-Playing'
df.loc[df.Genre == 'Party', 'Genre'] = 'Misc'
df.Genre.value_counts()
1-5. Publisher 결측치 수집
1-5-1. Publisher 결측치 이름 수집
names_list = []
for name in df.loc[df.Publisher.isna(), 'Name']:
names_list.append(name)
names_list[-3:]
#
# ['Dream Dancer',
# 'Bound By Flame',
# 'Super Robot Wars OG Saga: Masou Kishin II - Revelation of Evil God']1-5-2. Publisher 결측치 수집
driver = webdriver.Chrome('chromedriver.exe')
publisher_list = []
for x in names_list:
# name publisher로 검색
driver.get('https://www.google.com/search?q={}'.format(x + " " + "publisher"))
# publisher 입력받기
publisher = input('publisher : ')
# 입력받은 값 리스트에 저장
publisher_list.append(publisher)
driver.quit()# Publisher 결측치 채우기
df.loc[df.Publisher.isna(), 'Publisher'] = publisher_listdf.Publisher.isna().sum()
#
# 0df.info()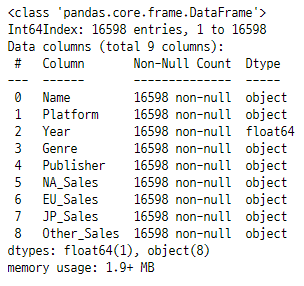
1-6. Sales 데이터 확인
1-6-1. Sales 이상값 확인
df.NA_Sales.value_counts()
수집했을 때 확인해보니 K, M 이 들어간 수치값이 있었다.
그래서 두가지로 분류해서 확인해봤다.
K가 포함된 데이터
df[df.NA_Sales.str.contains('K')]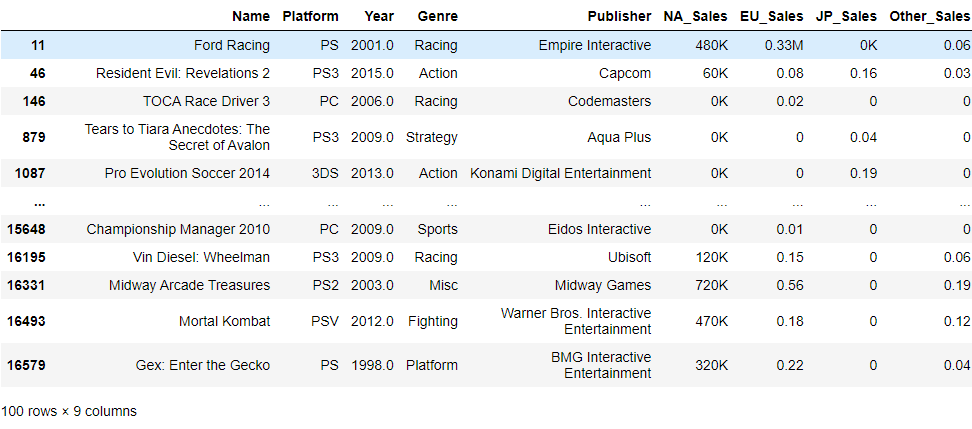
M이 포함된 데이터
df[df.NA_Sales.str.contains('M')]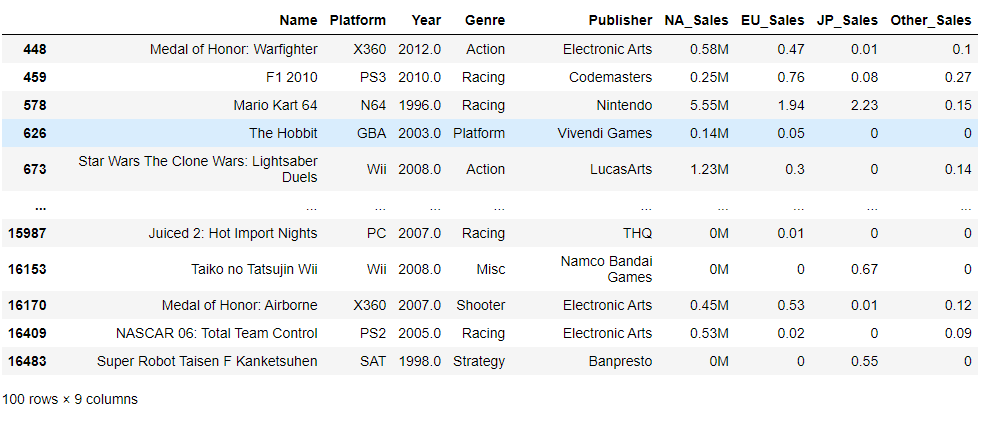
K가 포함된 데이터는 정수, M이 포함된 데이터는 실수인 것을 알 수 있었다.
결국 기준 단위는 백만 단위인 것을 알 수 있었고, 그래서 K를 백만단위로 바꿔주고
M은 M만 제거했다.
Sales 값 전처리
# Sales
sales_col = df.columns[5:]
# K인 곳의 인덱스 저장
loc_k = df[df.NA_Sales.str.contains('K')].index
for col in sales_col:
# k인 데이터 위치 가져오기
na_k = df.loc[df[col].str.contains('K'), col]
# m인 데이터 위치 가져오기
na_m = df.loc[df[col].str.contains('M'), col]
# 1000으로 나누고 K빼고 저장
na_k = na_k.str.replace('K', '').astype(float) / 1000
# M 빼고 저장
na_m = na_m.str.replace('M', '').astype(float)
# 기존 type이 string이기 때문에 변경해서 저장
df.loc[df[col].str.contains('K'), col] = na_k.astype(str)
df.loc[df[col].str.contains('M'), col] = na_m.astype(str)
df.loc[loc_k]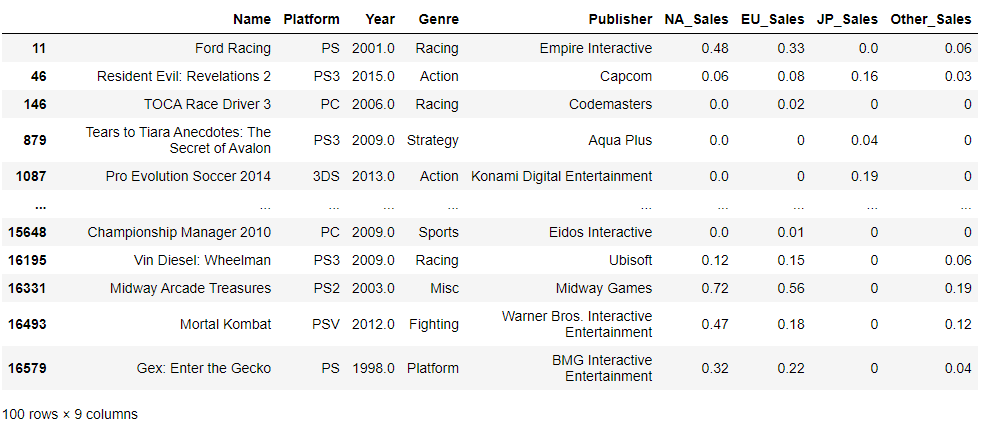
col = df.columns[-4:]
# 실수형으로 변환
df[col] = df[col].astype(float)
df.dtypes
2. 분석을 위한 컬럼 추가
# 전세계 판매금액 컬럼 추가 하기
global_sales = []
for i in df.index:
g_sales = df.loc[i, 'NA_Sales' : 'Other_Sales'].sum()
global_sales.append(round(g_sales, 2))
df['Global_Sales'] = global_sales
df.head(10)

조금씩 천천히