부분의존도그림 PDP (Partial Dependence Plots)
높은 성능을 내는 모델을 만들기 위해 복잡도가 높은 모델을 쓰게 된다.
복잡도가 높은 모델은 단순모델에 비해 성능은 좋지만 이해하기 어렵다.
distance based model 같은 특히 선형모델의 경우에는 회귀계수를 통해서 타겟값에 미치는 계수를 파악할 수 있지만, Tree based model 의 경우엔 Feature Importance 통해서 타겟값에 미치는 중요도는 살펴볼 수 있지만, 특성의 값에 따라서 Target 값에 증가/감소와 같은 영향을 미치는지는 알 수 없다.
이때 PDP 를 사용하면 관심있는 특성이 타겟에 어떻게 영향을 주는지 쉽게 파악할 수 있다.
보스턴 집값예측 데이터를 가지고 PDP 를 확인해보자.
import sklearn
from xgboost import XGBRegressor
from pdpbox.pdp import pdp_isolate, pdp_plot
from sklearn.model_selection import train_test_split
df, target = shap.datasets.boston()
X_train,X_test,y_train,y_test = train_test_split(df, target, test_size=0.2, random_state=2)
model = XGBRegressor().fit(X_train, y_train)
# 확인하고자 하는 특성들 저장
features = ['LSTAT', 'CRIM', 'NOX', 'RM']
# 특성들의 pdp plot 그리기
for feature in features:
isolated = pdp_isolate(model=model,
dataset=X_train,
model_features=X_train.columns,
feature=feature,
grid_type='percentile',
num_grid_points=10)
pdp_plot(isolated, feature_name=feature)
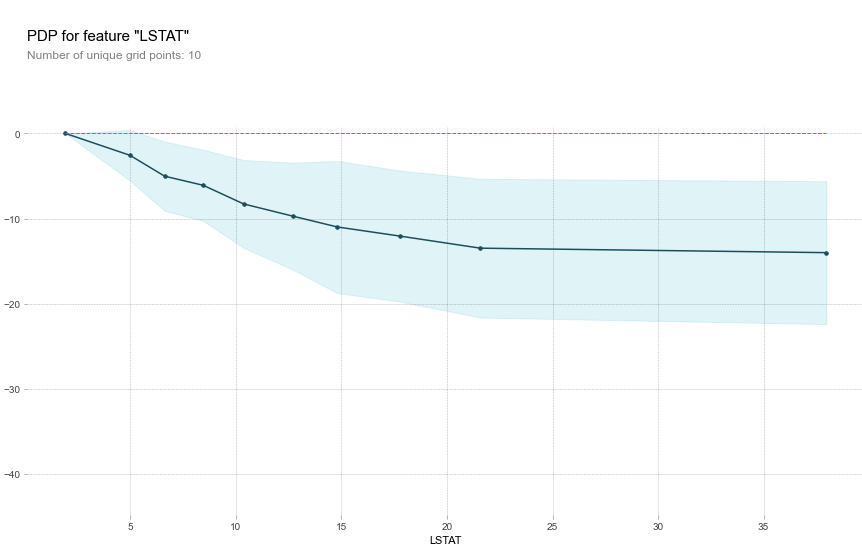

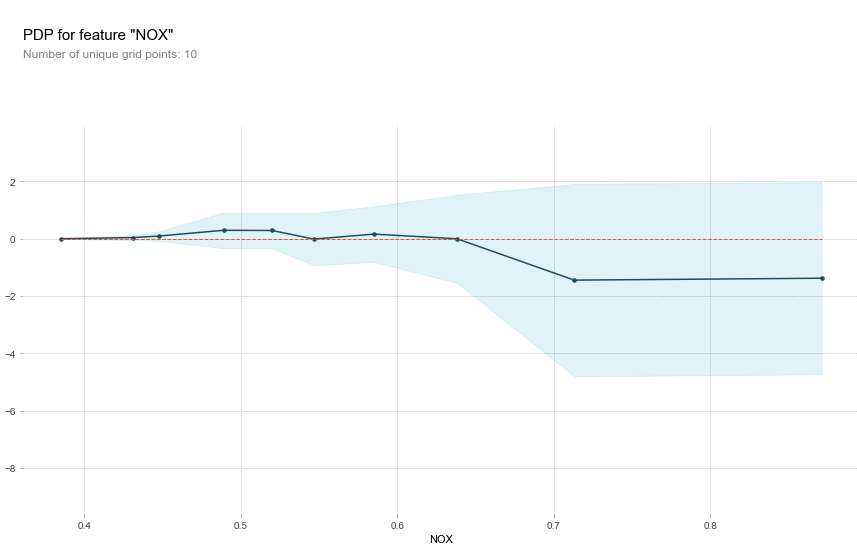
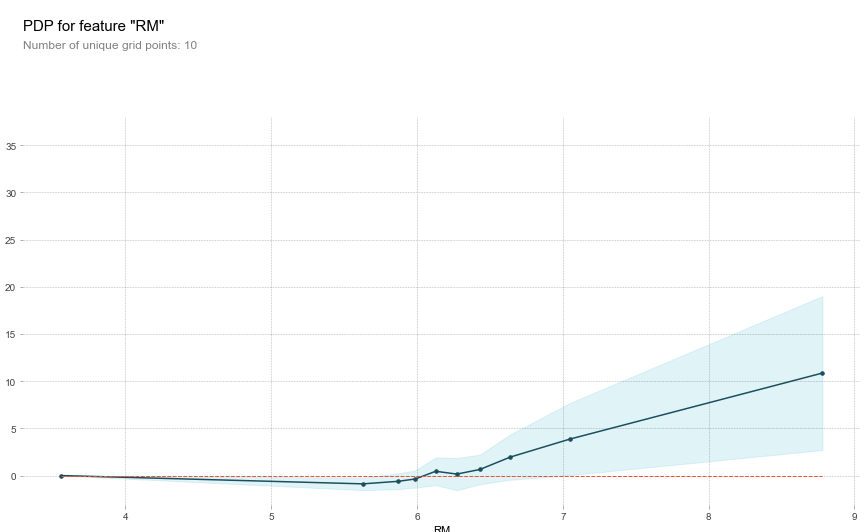
다음의 PDP를 통해서 RM을 제외한 특성들은 음의상관관계가 있다는 것을 알 수 있었다. 두가지 특성을 동시에 비교할 수도 있다.
from pdpbox.pdp import pdp_interact, pdp_interact_plot
# CRIM과 RM특성에 대한 target의 영향
features = ['CRIM', 'RM']
interaction = pdp_interact(
model=model,
dataset=X_train,
model_features=X_train.columns,
features=features
)
pdp_interact_plot(interaction, plot_type='grid', feature_names=features);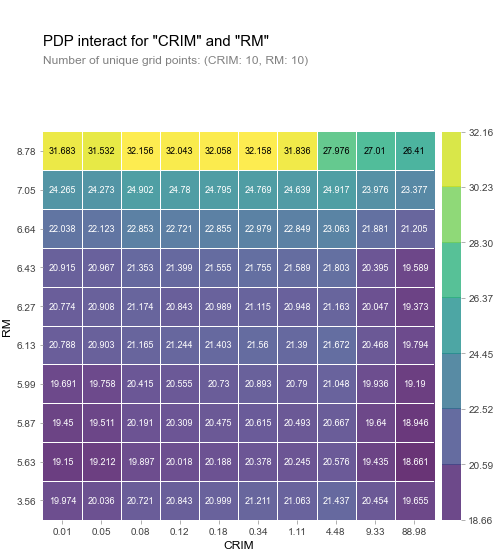
Shap
어떤 머신러닝 모델이든지 단일 관측치로부터 특성들의 기여도(feature attribution)를 계산하기 위한 방법이다.
Shapley value는 원래 게임이론에서 나온 개념이지만 복잡한 머신러닝 모델의 예측을 설명하기 위한 매우 유용한 방법이다.

위에서 사용했던 보스턴 집값 예측 데이터를 그대로 사용하겠다.
import shap
shap.initjs();
df, target = shap.datasets.boston()
X_train,X_test,y_train,y_test = train_test_split(df, target, test_size=0.2, random_state=2)
model = XGBRegressor().fit(X_train, y_train)
explainer = shap.TreeExplainer(model)
## Draw SHAP plots ###
shap_values = explainer.shap_values(X_train.iloc[[0]])
shap.force_plot(base_value=explainer.expected_value,
shap_values = shap_values,
features=X_train.iloc[[0]])
위와 같이 어떤 한 target의 영향력을 확인할 수도 있고, iloc[:30]과 같은 형식으로 지정해주면 각 값에 어떤 특성의 영향을 확인할 수 있다.
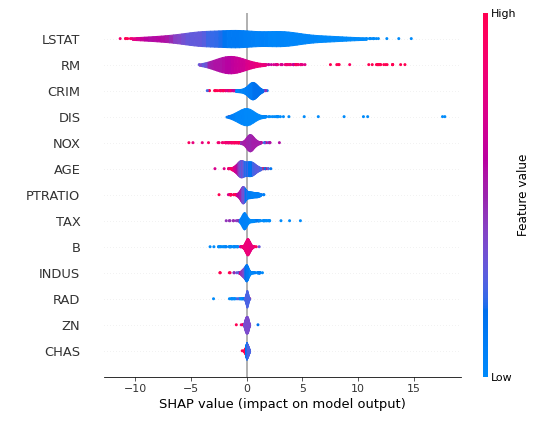
또한 Summary plot을 통해 Feature importance와 비슷한 target에 대한 영향도도 확인할 수 있다.
shap_values = explainer.shap_values(X_train)
shap.summary_plot(shap_values, X_train, plot_type='bar')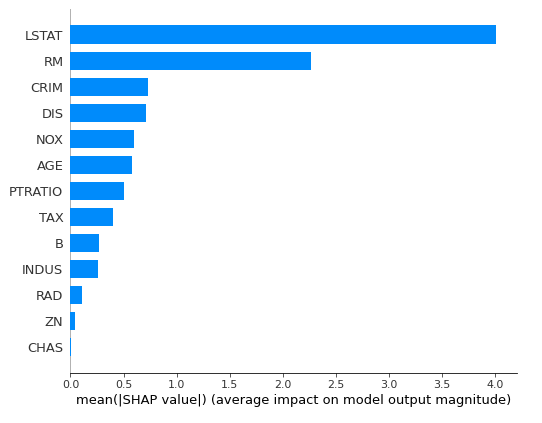
plot_type매개변수를 통해 'vilolin' 적용시 violin plot으로 전체적인 영향도도 확인할 수 있다.
shap_values = explainer.shap_values(X_train)
shap.summary_plot(shap_values, X_train, plot_type='violin')