
1. concat() 함수
df_cc = pd.concat([df1, df2])기본적인 파라미터
axis = 접합할 기준을 선택한다. axis=0(row)행 기준, axis=1(column)열 기준
join = 'outer'(default) 합집합, 'inner' 교집합 default값은 'outer' 이다.
ignore_index = False(default) True로 할시 기존 index를 무시하고 새로운 인덱스로 정렬해준다.
keys = None(default) 계층적 index를 사용하려면 튜플로 입력
names = None(default) index이름 부여시 튜플로 입력
등이 있다.
pd.concat_docs
2. melt()함수
df_tidy = df.melt(id_vars='종목명',
value_vars=['매출액','자산총계', 'EPS(원)'],
var_name='Feature', value_name= 'Value')기본적인 파라미터 설정 내용
id_vars = 기준이되는 열을 선택한다.
value_vars = 해당 특성별로 하나의 관측 데이터가 나열되게 된다.
var_name = 변수열의 이름을 정한다. default = variable
value_name = value열의 이름을 정한다. default = value
3. merge()함수
df = pd.merge(left, right, how=('left', 'right', 'inner', 'outer'),
on='key')기본적인 파라미터
left = 기준이되는 데이터 프레임을 입력한다.
right = merge하기 위한 데이터 프레임을 입력한다.
how = 'left' = left의 key를 기준으로 한다.
'right' = right의 key를 기준으로 한다.
'inner' = 교집합
'outer' = 합집합
on = 기준이 되는 key를 입력한다.
pd.merge_docs
4. pivot_table()함수
df = df.pivot_table(values=[column_list], index='테마', aggfunc='mean')기본 파라미터
values = 출력될 값
index = 기준이 되는 인덱스 리스트로 할당할 수 있는데 앞부터 기준이 됨
columns = 기준이 되는 열 리스트로 할당할 수 있는데 앞부터 기준이 됨
agg_func = 'mean', 'sum', 'min', 'max' 등 적용할 함수를 파라미터에 할당
margins = False(default) True일시 행, 열 각각의 합산값을 추가로 출력한다.
pd.pivot_table_docs
❗group by와 pivot_table의 차이점❗
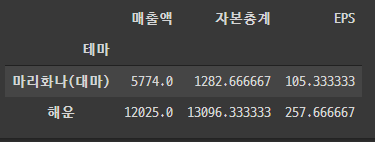
df = df.pivot_table(values=['매출액', '자본총계', 'EPS'], index='테마', aggfunc='mean')
theme_df.groupby('테마').mean()
두가지 함수의 차이점은 pivot_table의 column은 순서가 역순으로 변하였고, groupby의 column은 순서가 변하지 않았다는 점이다. 혹시나 column의 순서가 중요하다면 참조하는 것이 좋겠다.

5. 특정 컬럼을 제외한 Drop의 사용
col_list = df.columns #컬럼 리스트를 가져온다. col_list = col_list.drop(['매출액', '자산총계','EPS(원)']) #특정열을 제외한다. df.drop(columns=col_list, inplace=True) #위에 기재한 열을 제외한 나머지를 Drop한다.일반적으로 df.columns를 하게되면 판다스라이브러리의 pandas.core.indexes.base.Index라는 형태의 타입을 반환하게 된다.
리스트 형태로 받고자 한다면 df.columns.tolist() 함수를 이용하자.
5-1 loc함수를 활용하여 원하는 컬럼만 가져오기
df = df.loc[:, ['col1', 'col2', 'col3']].copy() # 행은 전부 가져오고, 열은 리스트로 조건을 준다음 # copy를 통해 새로운 메모리의 데이터 프레임을 할당해준다.
6. 컬럼의 순서 바꾸기
cols = df.columns.tolist()
cols = cols[::-1] #역순으로 바꾸기
df_cp = df[cols].copy() #컬럼 역순으로 바꾼 카피본 생성