표본추출 (sampling)
전체 모집단으로부터 표본을 선택하는 것
표본이 모집단의 특성을 대표할 수 있는가에 대한 것이 중점
표본추출을 하는 이유❓
광범위한 조사대상 전체를 조사하기 보다는, 모집단을 대표할 수 있는 표본을 선택하
여 조사하여 시간과 비용의 효율성과 효과성을 위함
표본추출의 방법
1. 단순 임의 추출 (simple random sampling)
모집단으로부터 샘플을 균등하게 임의로 추출하는 방법
- 복원추출 : 추출했던 것을 원래대로 돌려놓고 다시 추출하는 방법(중복 가능)
- 비복원추출 : 추출했던 것을 원래대로 돌려놓지 않고 다시 추출하는 방법(중복 불가능)
2. 체계적 추출 (systematic sampling)
무작위로 배열된 표본에서 시간적 혹은 공간적으로 일정한 간격을 두고 표본을 추출하는 방법
- [3, 6, 9, 12 ...] 배열에서 일정한 step을 선택하여 추출
3. 층화 임의 추출 (stratified random sampling)
모집단이 몇 개의 계층(stratum)으로 구성되어 있을 때 각 계층 원소로부터 임의 추출하는 방법
- 성별, 연령대별, 국가별 등
4. 군집 추출 (cluster sampling)
모집단이 여러 군집을 이룰 때, 우선 군집을 선택하고 그 집단에서 표본을 추출
- 지역 급식 실태조사 -> 지역의 학교 몇 곳을 모집단으로 추출 -> 모집단 학교의 급식 실태 조사
통계적 가설 검정 (Testing a Statistical Hypothesis)
증명되지 않은 주장이나 가설을 표본 통계량에 입각하여 주장이나 가설의 진위 여부를 판단, 증명, 검정하는 통계적 추론 방식
귀무가설 (Null hypothesis)과 대립가설 (Alternative hypothesis)
귀무가설이란?
영가설이라고도 하며, 모집단의 특성에 대해 옳다고 제안하는 잠정적인 주장
두집단을 비교시 같거나 차이가 없다로 해석함
기본적으로 참으로 추정되며, 거부하기 위해서 증거가 필요함
귀무가설 식
= 모집단의 평균
= 표본의 평균
대립가설이란?
귀무가설에 대립하는 주장
귀무가설을 기각함으로써 받아들여지는 반증의 과정을 통해 받아들여짐
대립가설 식
귀무가설과 대립가설의 예
대한민국 남자의 평균키는 172이다.
귀무가설 : 경기도 남자의 평균키는 172일 것이다.
대립가설 : 경기도 남자의 평균키는 172가 아닐 것이다.
공장의 생산라인의 용기의 무게는 32g으로 제작되게 되어있다. 용기들을 주기적으로 표본추출하여 용량이 정확한지 점검한다. 귀무가설 : 용기의 평균무게는 32g일 것이다. 대립가설 : 용기의 평균무게는 32g이 아닐 것이다.단측검정 예시
귀무가설 : 모집단의 평균은 표본의 평균보다 클 것이다.
대립가설 : 모집단의 평균은 표본의 평균보다 작거나 같을 것이다.
통계적 가설 검정의 오류 (Error of Testing Statistical Hypothesis)
혼동 행렬 (Confusion Matrix)
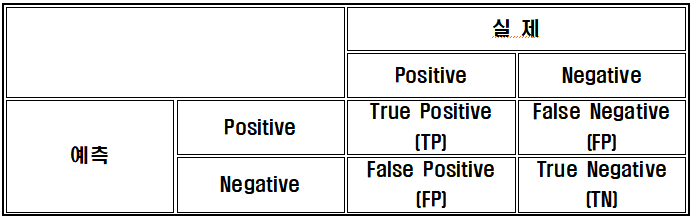
1종 오류(FP) : 귀무가설이 참인데도 불구하고 귀무가설을 기각하고 대립가설을 채택하는 오류
2종 오류(FN) : 귀무가설이 거짓인데도 불구하고 귀무가설을 채택하는 오류

= 1종 오류
= 2종 오류
귀무가설 : = 빵을 훔치지 않았다.
대립가설 : = 빵을 훔쳤다.1종오류 예시 : 빵을 훔치지 않았지만, 훔쳤다고 판정하는 것
2종오류 예시 : 빵을 훔쳤지만, 훔치지지 않았다고 판정하는 것
신뢰도 (Confidence Level)
📌모수가 신뢰구간 안에 포함될 확률(95%, 99%등을 사용)
신뢰도 95%
= 모수가 신뢰구간 안에 포함될 확률 95%
= 귀무가설이 틀렸지만 우연히 성립할 확률 5%
유의 수준 (alpha)
유의수준은 = alpha = 로 많이 표기함
귀무가설이 실제 옳음에도 틀릴 수 있는 확률(위험부담)
신뢰도가 95%의 경우 5%
일반적으로 5%이하로 설정함
= 1종 오류의 기준을 의미하기도 함
P-value < -> 귀무가설 기각
P-value > -> 귀무가설 채택
임계값 (critical value)
주어진 유의 수준에서 귀무가설의 채택과 기각에 관련된 의사결정을 할 때 기준이 되는 값
t-검정통계량의 절대값이 임계값보다 크면 귀무가설을 기각할 수 있다.
기각역 (Rejection Region)
확률분포에서 귀무가설을 기각하는 영역
기각역에 검정통계량이 위치하면 귀무가설을 기각한다.
양측검정인 경우 기각역은 유의수준() / 2 이고, 단측검정인 경우 기각역은 유의수준()과 같다.
[참고]
https://kkokkilkon.tistory.com/36
📌P-value (Probability value)
P-value 는, 주어진 가설에 대해서
"얼마나 근거가 있는지"에 대한 값을 0과 1사이의 값으로 scale한 지표
= 귀무가설이 참인 경우 결과를 얻을 수 있는 확률
-
P-value < 0.01 (1%)
귀무가설이 틀렸다 (깐깐한 기준) -
P-value < 0.05 (5%)
귀무가설이 틀렸다 (일반적인 기준) -
0.05 (5%) <= P-value <= 0.1 (10%)
귀무가설이 틀릴수도 있고 맞을수도 있다. -
P-value > 0.1 (10%)
귀무가설이 옳을 확률 10% 이상 -> 귀무가설이 맞다 -> 틀리지 않았을 것이다 -
P-value : 0.85 (85%)
귀무가설은 틀리지 않았다
P-value값이 값보다 낮을 때는 귀무가설을 기각하고 대립가설을 채택할 수 있다.
