카이제곱 검정 ( test)
변수가 명목척도일 때, 또는 데이터의 값이 갯수(count) 일 때 카이제곱 검정을 한다.
범주형 데이터(Categorical data)를 대상으로 검정
카이제곱 검정의 목적
변수가 1 개인 경우 : 변수 내 그룹간의 비율을 비교
그룹이 2 개인 경우 : Binomial test
그룹이 여러개인 경우 : 카이제곱 검정
변수가 2 개인 경우 : 변수 사이의 연관성을 비교
카이제곱 식
= 관찰 빈도(Observed Frequency), 자료의 값
= 기대 빈도(Expected Frequency), 기대 값
df(자유도) = 범주의 개수 - 1
일원 카이제곱 검정 (One-way test)
한개의 명목척도인 변수를 대상으로 검정
한개의 명목척도 변수는 2개 이상의 범주형 데이터를 가진다.
귀무가설 : = 범주형 데이터가 나타날 확률이 다 같다(차이가 없다).
대립가설 : = 범주형 데이터가 나타날 확률이 같지 않다(차이가 있다).
일원 카이제곱 검정의 유의성이 의미하는 것은 무엇인가 다르다 정도이다.
다르다는 의미는 사전에 정해진 기대값과 다르다는 의미이다.
이원 카이제곱 검정 (Two-way test)
두개의 명목척도인 변수를 대상으로 검정
귀무가설 : = 변수1과 변수2 사이에 연관성이 없다.
대립가설 : = 변수1과 변수2 사이에 연관성이 있다.
-
동질성 검증
변인의 분포가 이항분포나 정규분포와 동일하다라는 가설을 설정하여 이는 어떤 모집단의 표본이 그 모집단을대표하고 있는지를 검증하는데 사용 -
독립성 검증
변인이 두 개 이상일 때 사용되며, 기대빈도는 두변인의 상관관계가 없는 독립성을 기대하는 것을 의미하며 관찰빈도와의 차이를 통해 기대빈도의 진위여부를 확인
분할표(Contingency table)
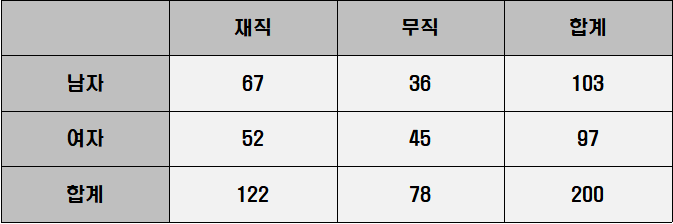
위의 데이터표의 검정
귀무가설 : = 성별과 재직여부에는 관련성이 없다. or 차이가 없다.
대립가설 : = 성별과 재직여부에는 관련성이 있다. or 차이가 있다.
데이터의 빈도만 작성된 단순한 표(python의 cross-table)
분할표는 두개의 변수를 행과 열로 나누어 빈도를 정리
분할표를 통한 이원 카이제곱 검정의 목적은 두 변수의 연관성의 확인이다.
이원 카이제곱의 기대값의 식
이원 카이제곱 식
이원 카이제곱의 자유도
각각의 범주 - 1의 곱
