분포 기반의 단어 표현(Distributed Representation)
분포 기반의 단어 표현은 벡터로 표현하고 하는 타겟 단어가 주변 단어에 의해 결정된다. 비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진 다는 분포가설을 바탕으로 한다. 대표적인 기술로는 Word2Vec, FastText가 있다.
임베딩(Embedding)
원-핫 인코딩의 치명적인 단점은 단어 간의 유사도(코사인 유사도)를 구할 수 없다는 것인데, 이 단점을 해결하기 위해 등장한 것이 임베딩이다. 단어의 고정 길이의 벡터, 즉 차원이 일정한 벡터로 나타내기 때문에 Embedding이라는 이름이 붙여졌다.
임베딩을 거친 단어 벡터는 원-핫 인코딩과는 다른 형태인 연속적인 값을 가지게 된다.
one-hot encoding
embedding
Word2Vec
2013년에 고안된 Word2Vec은 단어를 벡터로 나타내는 방법으로 가장 널리 사용되는 임베딩 방법 중 하나이다. Word2Vec은 특정 단어 양 옆에 있는 단어(Window size로 옆 단어의 범위를 설정)와의 관계를 활용하기 때문에 분포가설을 잘 반영하고 있다.
Word2Vec에는 CBow와 Skip-gram 두가지 방법이 있다.
CBow와 Skip-gram의 차이점은 Cbow는 주변단어의 정보를 통해 중심단어를 예측하는 것이고, Skip-gram은 중심단어의 정보를 기반으로 주변단어의 정보를 예측하는 것이다.
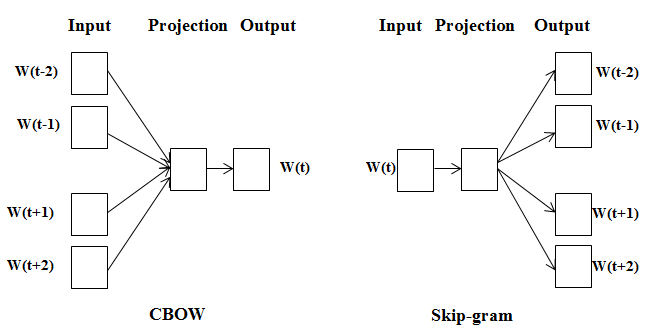
더 많은 정보를 바탕으로 특정 단어를 예측하기 때문에 CBow의 성능이 더 좋을 것으로 생각하기 쉽지만, 역전파 관점에서 보게 되면 Skip-gram에서 더 많은 학습이 일어나기 떄문에 Skip-gram의 성능이 조금 더 좋게 나타나고, 리소스 또한 더 크다.
gensim 패키지를 통한 word2Vec 실습
import gensim.downloader as api
# 구글 뉴스 말뭉치로 학습된 Word2Vec api
wv = api.load('word2vec-google-news-300')
# 구글 뉴스 말뭉치를 통해 학습된 word2vec 단어 확인
for idx, word in enumerate(wv.index_to_key):
if idx == 10:
break
print(f"word #{idx}/{len(wv.index_to_key)} is '{word}'")word #0/3000000 is '</s>'
word #1/3000000 is 'in'
word #2/3000000 is 'for'
word #3/3000000 is 'that'
word #4/3000000 is 'is'
word #5/3000000 is 'on'
word #6/3000000 is '##'
word #7/3000000 is 'The'
word #8/3000000 is 'with'
word #9/3000000 is 'said'# 임베딩 벡터의 차원과 값 queen 예시
vec_queen = wv['queen']
print(f"Embedding dimesion is : {vec_queen.shape}\n")
print(f"Embedding vector of 'queen' is \n\n {vec_queen}")Embedding dimesion is : (300,)
Embedding vector of 'queen' is
[ 0.00524902 -0.14355469 -0.06933594 0.12353516 0.13183594 -0.08886719
-0.07128906 -0.21679688 -0.19726562 0.05566406 -0.07568359 -0.38085938
0.10400391 -0.00081635 0.1328125 0.11279297 0.07275391 -0.046875
0.06591797 0.09423828 0.19042969 0.13671875 -0.23632812 -0.11865234
0.06542969 -0.05322266 -0.30859375 0.09179688 0.18847656 -0.16699219
-0.15625 -0.13085938 -0.08251953 0.21289062 -0.35546875 -0.13183594
0.09619141 0.26367188 -0.09472656 0.18359375 0.10693359 -0.41601562
0.26953125 -0.02770996 0.17578125 -0.11279297 -0.00411987 0.14550781
0.15625 0.26757812 -0.01794434 0.09863281 0.05297852 -0.03125
-0.16308594 -0.05810547 -0.34375 -0.17285156 0.11425781 -0.09033203
0.13476562 0.27929688 -0.04980469 0.12988281 0.17578125 -0.22167969
-0.01190186 0.140625 -0.18164062 0.11865234 0.16113281 0.21484375
-0.21191406 0.12695312 -0.10009766 0.13671875 0.12695312 0.01531982
0.10449219 -0.02783203 -0.06030273 0.0222168 0.18164062 -0.06738281
0.04907227 0.15429688 -0.25 0.13964844 0.29492188 0.10644531
0.3359375 -0.22265625 -0.125 -0.05297852 0.19238281 0.06835938
0.06982422 -0.05200195 0.14453125 0.00448608 -0.01013184 -0.1484375
0.21777344 -0.1953125 -0.390625 0.07763672 -0.57421875 -0.07910156
-0.04052734 -0.1875 0.25390625 0.15722656 0.125 0.140625
0.20117188 -0.05859375 0.16894531 -0.28125 0.171875 0.19140625
0.12109375 -0.15039062 -0.00695801 -0.23730469 0.13964844 -0.00836182
-0.04711914 0.14648438 -0.05688477 0.10205078 0.08447266 0.21191406
-0.01831055 0.50390625 -0.04858398 0.22167969 -0.25585938 0.03417969
0.15820312 -0.03369141 0.06738281 -0.25195312 0.04614258 -0.07275391
0.07958984 0.04223633 -0.00128937 0.20214844 -0.13085938 -0.06030273
0.0378418 0.13574219 0.11181641 -0.24609375 -0.23925781 -0.23632812
-0.04321289 -0.02905273 0.23535156 -0.00390625 -0.05029297 0.18457031
0.50390625 -0.00668335 -0.03466797 -0.07568359 0.06152344 -0.31445312
-0.03759766 0.23632812 -0.12792969 0.15429688 0.296875 0.02709961
-0.17089844 -0.22460938 0.00241089 0.10595703 -0.03320312 0.0145874
-0.21582031 0.24707031 -0.07421875 -0.10205078 0.16894531 -0.05029297
0.20800781 -0.03857422 -0.22265625 0.27539062 -0.05957031 -0.01757812
0.01794434 0.08886719 0.12890625 0.18261719 0.14453125 0.10400391
-0.1328125 -0.32617188 0.00386047 -0.11376953 -0.05053711 -0.13085938
0.02209473 -0.14648438 0.10742188 0.23046875 0.15234375 0.22753906
0.04833984 0.06787109 -0.06787109 -0.2578125 0.11230469 0.00363159
-0.12011719 -0.21289062 0.11230469 0.12158203 0.06835938 0.04907227
0.2734375 -0.00302124 -0.00378418 0.00193787 0.1875 -0.29101562
0.09033203 0.26367188 -0.25585938 -0.28710938 -0.40820312 0.10546875
0.39648438 -0.07275391 -0.04321289 -0.06347656 -0.00060272 -0.11523438
0.31445312 -0.22265625 0.13574219 -0.01965332 0.15332031 0.00360107
-0.12011719 0.06494141 0.16210938 -0.16699219 0.03271484 -0.00350952
0.18847656 0.19335938 0.1328125 0.06787109 -0.34179688 -0.08349609
-0.29492188 -0.02099609 0.08886719 0.32421875 -0.36914062 -0.0859375
-0.04956055 0.13183594 0.04418945 0.359375 0.21484375 0.265625
-0.2734375 0.23535156 0.11425781 0.08789062 0.1875 -0.33203125
0.15136719 -0.03613281 -0.11914062 0.27734375 0.10839844 -0.07275391
0.23242188 0.00219727 0.23828125 -0.24902344 -0.12353516 -0.15917969
-0.00601196 0.14550781 -0.00460815 -0.22558594 -0.37890625 -0.37695312
-0.08251953 -0.04125977 0.16796875 -0.046875 0.16308594 0.15429688]# 유사도 확인
pairs = [
('car', 'minivan'),
('car', 'bicycle'),
('car', 'airplane'),
('car', 'monster'),
('car', 'democracy')
]
for w1, w2 in pairs:
print(f'{w1} ======= {w2}\t {wv.similarity(w1, w2):.2f}')car ======= minivan 0.69
car ======= bicycle 0.54
car ======= airplane 0.42
car ======= monster 0.10
car ======= democracy 0.08# car, minivan 벡터를 더한 벡터와 가장 유사한 5개의 단어
for i, (word, similarity) in enumerate(wv.most_similar(positive=['car', 'minivan'], topn=5)):
print(f"Top {i+1} : {word}, {similarity}")Top 1 : SUV, 0.853219211101532
Top 2 : vehicle, 0.8175785541534424
Top 3 : pickup_truck, 0.7763689160346985
Top 4 : Jeep, 0.7567334175109863
Top 5 : Ford_Explorer, 0.756571888923645# positive의 단어벡터를 더하고 negative 단어벡터를 뺀 값과 가장 유사한 단어
print(wv.most_similar(positive=['king', 'women'], negative=['men'], topn=1))
print(wv.most_similar(positive=['walking', 'swam'], negative=['walked'], topn=1))[('queen', 0.6525817513465881)]
[('swimming', 0.7448816895484924)]# 관계없는 단어 추출
print(wv.doesnt_match(['fire', 'water', 'land', 'sea', 'air', 'car']))carWord2Vec의 한계점
unk = 'cameroon'
try:
vec_unk = wv[unk]
except KeyError:
print(f"The word #{unk} does not appear in this model")The word #cameroon does not appear in this model학습되지 않은 단어는 에러가 발생한다.
FastText
fastText 는 Word2Vec 방식에 철자(Character) 기반의 임베딩 방식을 더해준 새로운 임베딩 방식이다.
OOV(Out of Vocabulary) 문제
위의 Word2Vec 실습을 통해서 확인했다시피 Word2Vec은 학습되지 않은 말뭉치에 대해서 임베딩 벡터를 출력하려다 보니 에러가 발생했다. Word2Vec은 말뭉치에 등장하지 않은 단어에 대해서는 임베딩 벡터를 만들지 못한다는 단점이 있다. 이러한 말뭉치에 등장하지 않는 단어가 등장하는 문제를 OOV 문제라고 한다.
철자 단위 임베딩(Character level Embedding)
FastText는 철자 수준의 임베딩을 보조 정보로 사용함으로써 OOV문제를 해결했다.
character n-gram(단어를 n개의 철자 단위로 끊음)을 이용하게 되는데 FastText는 3-6개로 묶은 정보 단위를 사용한다. 3-6개 단위로 묶기 이전에 모델이 접두사와 접미사를 인식할 수 있도록 단어 앞 뒤로 "<", ">"를 붙여준다.
만약 eating이라는 단어에 철자 단위 임베딩을 적용한다면 3-gram은 다음과 같다.

위와 같이 우측으로 1씩 슬라이드 하며 단어의 끝까지 추출하여 다음과 같은 6개의 철자 단위가 나온다.

위와 같은 방식을 3-6개까지 진행한 뒤 임베딩 벡터를 생성하고 원래 eating의 임베딩 벡터와 함께 사용한다.
| word | Length(n) | Character n-grams |
|---|---|---|
| eating | 3 | <ea, eat, ati, tin, ing, ng> |
| eating | 4 | <eat, eati, atin, ting, ing> |
| eating | 5 | <eati, eatin, ating, ting> |
| eating | 6 | <eatin, eating, ating> |
총 18개의 Character-level n-gram을 얻을 수 있고 이렇게 얻어진 n-gram들의 임베딩 벡터를 모두 구하게 된다.
gensim 패키지를 통한 FastText 실습
from pprint import pprint as print
from gensim.models.fasttext import FastText
from gensim.test.utils import datapath
# Set file names for train and test data
corpus_file = datapath('lee_background.cor')
model = FastText(vector_size=100)
# build the vocabulary
model.build_vocab(corpus_file=corpus_file)
# train the model
model.train(
corpus_file=corpus_file, epochs=model.epochs,
total_examples=model.corpus_count, total_words=model.corpus_total_words,
)
print(model)<gensim.models.fasttext.FastText object at 0x000001B78BEC51F0>ft = model.wv
print(ft)
#
# FastText models support vector lookups for out-of-vocabulary words by summing up character ngrams belonging to the word.
# night와 nights가 모델에 있는 단어인지 확인
print(f"night => {'night' in ft.key_to_index}")
print(f"nights => {'nights' in ft.key_to_index}")<gensim.models.fasttext.FastTextKeyedVectors object at 0x000001B78BEC5220>
'night => True'
'nights => False'# 임베딩 벡터 확인
print(ft['night'])array([-0.20463593, 0.18443085, -0.26853317, -0.08688911, 0.06378575,
0.37377924, 0.30063277, 0.49444968, 0.25394002, -0.2311205 ,
0.02913288, -0.15705667, -0.23076217, 0.5116651 , -0.38772947,
-0.5542293 , 0.18766813, -0.23624967, -0.42022046, -0.538799 ,
-0.4625825 , -0.05752243, -0.457674 , -0.11660901, -0.19904055,
-0.3248947 , -0.6830404 , -0.11595102, -0.32427755, 0.2682462 ,
-0.32188955, 0.3108555 , 0.8356222 , -0.26182908, 0.18470214,
0.3963227 , 0.39649194, -0.1015866 , -0.37272444, -0.34553406,
0.46362668, -0.42487824, 0.03368492, -0.4027351 , -0.52044946,
-0.30578727, -0.06675274, 0.13024303, 0.36339226, -0.00631065,
0.3541524 , -0.43579 , 0.29340118, -0.4063173 , -0.19859204,
-0.19062924, -0.1648312 , -0.12934631, 0.0420457 , -0.3588241 ,
-0.3417488 , -0.43260136, -0.189408 , 0.34960446, -0.12073563,
0.6878519 , 0.06363328, 0.06985023, 0.42564437, 0.24282329,
-0.2489152 , 0.38069293, 0.5063448 , -0.6416133 , 0.34418976,
-0.09538002, 0.27110898, -0.03438103, 0.05406643, 0.37707585,
0.18503168, -0.48799106, -0.81518 , -0.15139884, -0.12481003,
-0.78079444, 0.48810068, 0.19047275, -0.02043972, -0.273127 ,
-0.00531006, 0.41134417, -0.12888683, 0.06549346, -0.201821 ,
0.59561217, -0.21664988, -0.30355778, -0.02301619, -0.22459905],
dtype=float32)print(ft['nights'])array([-0.17837374, 0.16099885, -0.23322892, -0.07525793, 0.05415221,
0.32325736, 0.2623552 , 0.43116784, 0.22090767, -0.20229244,
0.02703131, -0.13482958, -0.20143989, 0.44208398, -0.3379631 ,
-0.4817595 , 0.16235192, -0.20476565, -0.36373928, -0.46885708,
-0.3987025 , -0.05105125, -0.39728764, -0.10266577, -0.17146415,
-0.2806086 , -0.5916139 , -0.09842386, -0.2812483 , 0.23437892,
-0.27751267, 0.26937318, 0.7236302 , -0.22689036, 0.1604436 ,
0.34345305, 0.34552574, -0.08816183, -0.3237392 , -0.3004986 ,
0.4015698 , -0.36788142, 0.02874494, -0.34902132, -0.45254353,
-0.26417267, -0.05500818, 0.11365659, 0.3168112 , -0.0043913 ,
0.3089629 , -0.3785041 , 0.25532627, -0.35258764, -0.17195195,
-0.16423629, -0.1450355 , -0.11049549, 0.03781502, -0.3088066 ,
-0.29559785, -0.37578645, -0.1640433 , 0.30291757, -0.10422365,
0.5980513 , 0.0553609 , 0.05799852, 0.3691768 , 0.21192758,
-0.21650054, 0.32848534, 0.44062513, -0.5567908 , 0.30025744,
-0.08175257, 0.23470055, -0.03067187, 0.04671163, 0.32733598,
0.16112725, -0.42395744, -0.7069276 , -0.13247272, -0.10732234,
-0.67887306, 0.423607 , 0.16550173, -0.01570405, -0.23772489,
-0.00453051, 0.3558751 , -0.11238657, 0.0575321 , -0.17564988,
0.5172094 , -0.18944909, -0.2598488 , -0.01965485, -0.1958198 ],
dtype=float32)nights라는 단어가 없음에도 임베딩 벡터를 생성한다.
# 두 단어의 유사도를 확인
print(ft.similarity("night", "nights"))0.9999918# nights와 비슷한 단어 Top10
print(ft.most_similar("nights"))[('night', 0.9999919533729553),
('flights', 0.999987781047821),
('rights', 0.9999877214431763),
('overnight', 0.999987006187439),
('fighters', 0.9999857544898987),
('fighting', 0.9999855756759644),
('fight', 0.9999851584434509),
('entered', 0.9999850988388062),
('fighter', 0.9999850988388062),
('eight', 0.9999845027923584)]# 단어 중 가장 관련없는 단어 추출
print(ft.doesnt_match("night noon fight morning".split()))'noon'FastText는 단어의 의미보다는 결과에 비중이 있다는 것을 확인할 수 있다.
