
1. 맥주 리뷰 수집
맥주 리뷰를 수집하기 위해서 사이트를 찾아본 결과 Beeradvocate라는 맥주 커뮤니티 사이트를 찾을 수 있었고 여기서 리뷰들을 확인해보니 흥미롭게도 같은 맥주일 경우 단어들의 구성이 비슷하게 이루어진 것을 확인할 수 있었다.
리뷰가 주관적일 수 있지만 비교적 섬세하게 작성한 리뷰들이 많았기 때문에 아이템 기반 추천시스템을 구현하기 괜찮을 것이라고 판단했다.
맥주 데이터는 전에 수집해두었던 맥주 데이터를 기반으로 이름 검색을 통해 수집하였다.
전에 수집해 두었던 데이터는 다음과 같다.

이중 Beeradvocate 사이트에서 190개의 맥주 데이터를 수집할 수 있었다.
수집 코드는 다음과 같다.
import requests
import re
from bs4 import BeautifulSoup
import pandas as pd
import os
def beer_review_crawling(beer_name_list, save_path):
'''
Crawling from 'https://www.beeradvocate.com'
Parameter : beer_name_list : list of beer names, save_path : save path to collected review
'''
err_cnt = 0
err_bnames = []
scores_list = []
url = 'https://www.beeradvocate.com'
for bname in beer_name_list:
search_name = bname.replace(' ', '+')
res = requests.get(url + f'/search/?q={search_name}')
html = res.content
bs = BeautifulSoup(html, 'html.parser')
try:
beer_url = bs.select_one('div#ba-content > div > div > a')['href']
beer_res = requests.get(url + beer_url)
beer_bs = BeautifulSoup(beer_res.content, 'html.parser')
reviews = beer_bs.find_all('div', {'id' : 'rating_fullview_content_2'})
except:
reviews = bs.find_all('div', {'id' : 'rating_fullview_content_2'})
if reviews:
review_cnt = 0
for review in reviews:
try:
rev = review.text
s = re.search('%', rev).end()
e = re.search('overall:', rev).start() - 2
scores = rev[s:e]
scores = scores.split('|')
beer_reviews = {'name' : bname}
for sc in scores:
sc = sc.strip()
sc = sc.split(':')
sense = sc[0].strip()
score = float(sc[1].strip())
beer_reviews[sense] = score
# collect review
r_s = re.search('overall: [0-9][.]?[0-9]?[0-9]?', rev).end()
beer_reviews['review'] = rev[r_s:]
scores_list.append(beer_reviews)
review_cnt += 1
except:
pass
print(f"{review_cnt} of {bname} review are collected.")
else:
err_cnt += 1
err_bnames.append(bname)
print(f"{bname} is not collected")
print(err_bnames, 'are not collected')
print(f'not collected total : {err_cnt}')
with open(save_path + '/err_collected_beers.txt', 'w') as f:
f.write('\n'.join(err_bnames))
df = pd.DataFrame(scores_list)
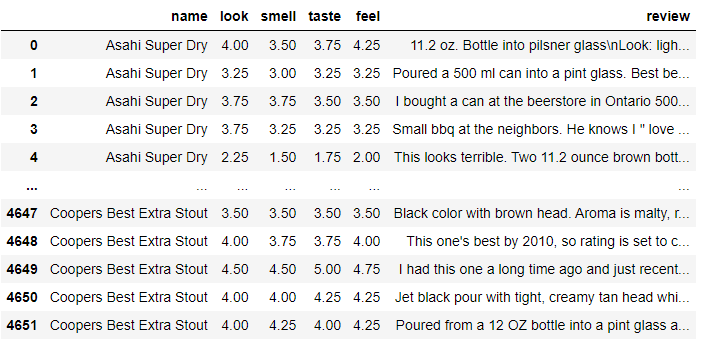
df.to_csv(save_path + '/beer_scores.csv', index=False)수집된 데이터
2. 리뷰 데이터 분석
2-1. 토큰화
좋은 맥주를 추천하기보다 비슷한 맛의 맥주를 추천하는 것을 목적으로 하기 때문에 각 감각에 대한 점수들을 수집했지만 사용하지는 않았다.
리뷰 예시

맥주 리뷰들을 살펴보니 많은 수의 리뷰들이 다음과 같이 시각, 후각, 미각, 촉각에 입각하여 작성된 리뷰를 확인할 수 있었다. 그러므로 각 맥주들의 감각들을 표현하는 단어가 많이 분포되어 있을 것으로 확인하고 빈도 기반 단어 분석을 위해 토큰화를 진행하였다.
import spacy
def text_tokenize(text):
nlp = spacy.load('en_core_web_sm')
stop_words = nlp.Defaults.stop_words.union('i', 'I', '\n', '\n\n')
tokens = []
doc = nlp(text)
for token in doc:
if (token.text.lower() not in stop_words) & (token.is_punct == False): # 불용어, 구두점 검출
tokens.append(token.lemma_) # 표제어 추출하여 담기
return tokens
2-2. 토큰 정제
이후 토큰화된 단어를 살펴보니 "500" "ml", "11.2", "oz", "2012"와 같이 숫자로 표기된 토큰과 "ago"와 같이 짧은 단어들을 확인할 수 있었다.
필요한 단어들은 "smoky", "light", "brown" 과 같은 맥주를 형용하는 단어들이기에 토큰들중 숫자로 표기된 것과 단어의 길이가 3이하인 토큰들을 삭제하는 과정을 거쳤다.
import re
def token_cleaning(token):
comp = re.compile('[^A-Za-z]') # 영어로 된 단어만 검출
clean = []
for t in token:
t = comp.sub('', t)
if len(t) > 4:
clean.append(t.lower()) # 검출된 단어 소문자로 통합하여 저장
return clean2-3. 토큰 통합
이후 이름으로 그룹화 하여 토큰들을 통합해 주었다.
token_df = df.groupby('name')['clean_token'].sum().reset_index()
new_beers_df = new_beers_df.merge(token_df, on='name')
new_beers_df.head()❗ 그룹화하다가 알게 된 사실
리스트를 groupby().sum()을 통해서도 list.extend와 같은 효과를 볼 수 있었다는 것
2-4. 토큰 분석
맥주들의 리뷰 토큰을 확인해보기 위해서 각 맥주별 토큰 빈도수 상위 20개를 뽑아 확인해본 결과 자주 등장하지만 맥주를 설명하지 않는 "taste", "flavor", "bottle"과 같은 단어들이 존재하는 것을 확인할 수 있었다.
그래서 이런 단어들을 제외하고 맥주별 토큰 상위 20개를 확인해보았다.
# 자주 등장하는 단어 상위 20개 중 특징에 해당하지 않는 단어들을 검출함
stop_words = ['taste', 'flavor', 'bottle', 'color', 'mouthfeel', 'glass', 'lacing', 'finger',
'little', 'finish', 'interesting', 'aftertaste', 'overall', 'slight', 'colour',
'flavour', 'style', 'aroma', 'smell', 'review', 'leave', 'decent']
cleared = []
most_tokens = []
for token in new_beers_df['clean_token']:
for t in token:
if t in stop_words:
continue
else:
cleared.append(t)
cnt = Counter(cleared).most_common(20)
for c in cnt:
text, _ = c
most_tokens.append(text)
res = Counter(most_tokens)
exp_tokens = sorted(res.items(), key=lambda x : x[1])
exp_tokens # 설명 가능한 토큰들의 집합[('lightly', 1),
('different', 1),
('think', 1),
('heavy', 1),
('woody', 1),
('schlenkerla', 1),
('clove', 1),
('toffee', 1),
('pretty', 1),
('porter', 1),
('marzen', 2),
('weizen', 2),
('rauchbier', 2),
('bacon', 2),
('alcohol', 2),
('banana', 3),
('bodied', 3),
('roasted', 5),
('clean', 7),
('bread', 10),
('wheat', 10),
('black', 11),
('grain', 13),
('great', 42),
('citrus', 43),
('amber', 52),
('smoke', 57),
('malty', 57),
('yeast', 72),
('chocolate', 92),
('crisp', 98),
('fruit', 125),
('golden', 136),
('bitter', 162),
('orange', 173),
('sweetness', 176),
('slightly', 183),
('clear', 184),
('lager', 185),
('drink', 186),
('white', 189),
('bitterness', 190),
('medium', 190),
('light', 191),
('brown', 191),
('sweet', 191),
('carbonation', 191),
('caramel', 191),
('smooth', 191)]이후 빈도수가 2개 이하인 토큰들은 가중치로 사용하기엔 무리가 있다고 판단하여 삭제하였다.
2-5. 토큰 가중치 데이터 생성
제거 후 총 34개의 가중치 토큰들을 얻을 수 있었고 각 맥주별 가중치 토큰들의 빈도수를 종합하여 새로운 가중치 데이터를 만들 수 있었다.
# 토큰들을 통해 각 맥주별 토큰 빈도수 체크
token_count = []
for i in range(len(new_beers_df)):
exp_token_dict = {}
exp_token_dict = {k : 0 for k in exp_token_list}
tokens = new_beers_df['clean_token'][i]
for token in tokens:
if token in exp_token_list:
exp_token_dict[token] += 1
token_count.append(exp_token_dict)
token_count_df = pd.DataFrame(token_count, index=new_beers_df.name)
token_count_df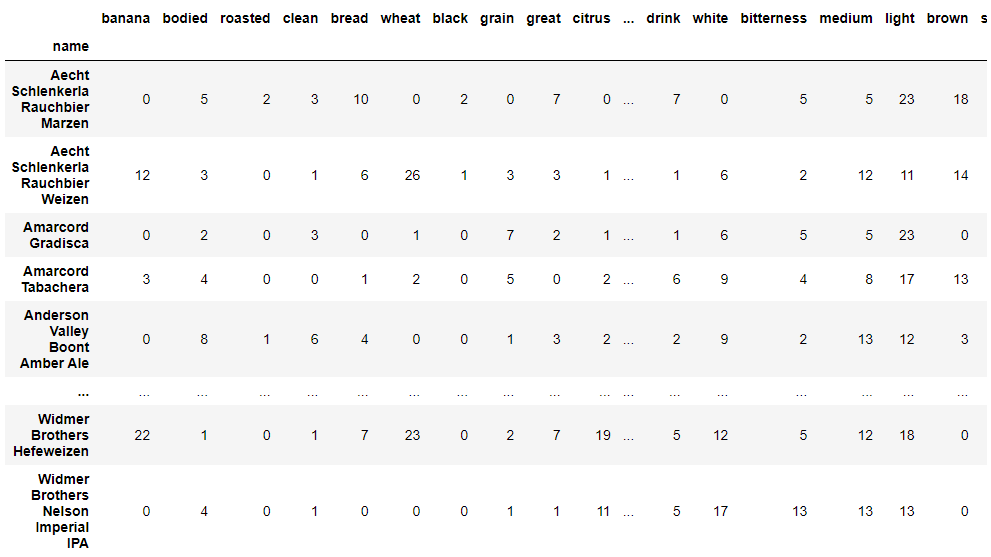
혹시나 맥주 중 설명할 단어가 없는지 체크하였지만 없었고 각 요소들을 가중치로 변경하여 유사도를 확인하기 위해서 0~1의 범위로 스케일링을 진행하였다.
# 각 요소들을 가중치로 변환하기 위해 스케일러 적용
scaler = MinMaxScaler()
beers_df = pd.DataFrame(scaler.fit_transform(token_count_df),
columns=token_count_df.columns,
index = token_count_df.index)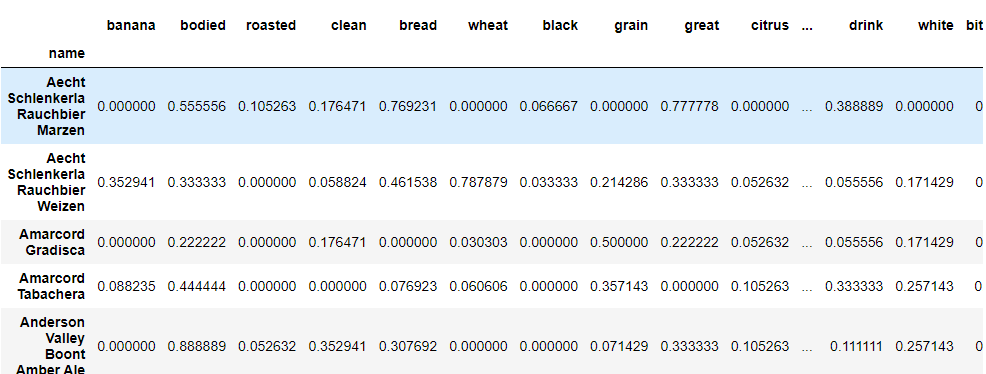
3. 추천 알고리즘
추천 알고리즘으로 코사인 유사도를 선택했다.
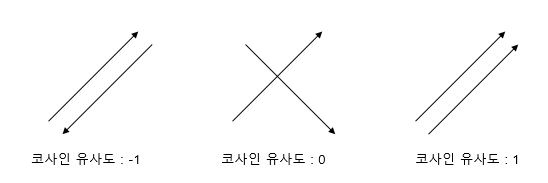
코사인 유사도란?
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미한다. 두 벡터의 방향이 완전히 동일한 경우 1, 90도인 경우 0, 180도인 경우 -1의 값을 가진다. 1에 가까울수록 유사도가 높다고 판단할 수 있다.
from sklearn.metrics.pairwise import cosine_similarity
# 코사인 유사도
cosine_sim = cosine_similarity(matrix, matrix)
# 맥주의 이름을 담은 데이터
indices = pd.Series(data=last_beers_df.index, index=last_beers_df.name)
# 유사도가 높은 상위 3가지 맥주의 이름을 반환해주는 함수
def get_recommendations(name, cosine_sim=cosine_sim):
# 다른 맥주와의 유사도 가져오기
idx = indices[name]
# 해당 맥주와의 유사도 구하기
sim_scores = list(enumerate(cosine_sim[idx]))
# 유사도에 따라 맥주 정렬
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 가장 유사한 맥주 3개 가져오기
sim_scores = sim_scores[1:4]
# 가장 유사한 맥주 3개의 인덱스 가져오기
beer_indices = [i[0] for i in sim_scores]
return indices.iloc[beer_indices].index.tolist()위의 함수를 통해 호가든과 코젤을 입력하여 추천된 상위 3개의 맥주들은 다음과 같다.
⏯ 호가든을 입력

🔙 호가든에 대해 추천된 출력

⏯ 코젤을 입력

🔙 코젤에 대해 추천된 출력

결론
맥주 리뷰를 통해 만든 단어 가중치 행렬을 코사인 유사도를 사용하여 맥주 추천시스템을 구현해보았다.
비교적 섬세하고 자세히 적혀있는 리뷰가 많아서인지 주관적인 리뷰에도 불구하고 비슷한 맛을 가지고 있는 맥주들을 추천해주는 것을 볼 수 있었다.
