분산분석 ANOVA 란?
분산의 개념을 이용하여 분석하는 방법으로, 분산을 계산할 때 처럼 편차의 각각의 제곱합을 해당 자유도로 나누어서 얻게되는 값을 이용하여 수준평균들간의 차이가 존재하는지 판단한다.
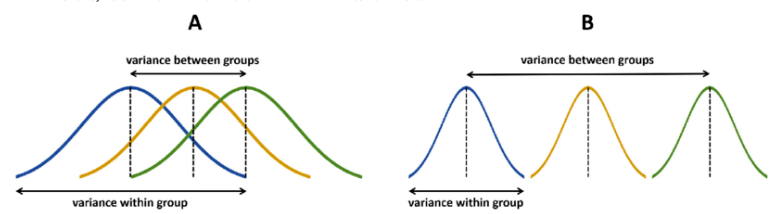
[이미지 출처]https://bioinformaticsandme.tistory.com/198
분산 분석의 조건
- 정규성 : 모집단의 분포가 정규분포여야 함
- 등분산성 : 모집단 간의 분산이 동일해야 함
- 독립성 : 모집단 간의 오차는 서로 독립이어야 함
🤔언제 분산분석 (ANOVA)를 이용하는가?
독립변수가 이산형/범주형(Discrete/Categorical) 자료이면서,
종속변수가 연속형(Continuous) 자료인 3개 이상의 집단 간 평균 비교분석에 사용된다.
다수 집단 비교를 할 때, t-test를 사용할수도 있지만, 다중검정문제로 인해 1종 오류가 증가하게 되므로 분산분석을 사용하게 됨.
분산분석에 사용되는 변수의 종류
- 독립변수 (Independent variable)
논리적 인과관계에서 원인이 되는 변수
예측변수(predictor variable) 설명변수(explanatory variable)라고 하기도 함
독립변수의 예 : 성별, 직군, 인종, 동물의 종류, 혈액형 등
- 종속변수 (Dependent variable)
연구/조사자가 독립변수의 변화에 따라 어떻게 변하는지 알고 싶은 변수
반응변수(response variable), 결과변수(outcome variable)라고 하기도함
종속변수의 예 : 키, 몸무게, 성능결과, 생산량, 임금 등
- 통제변수 (Control variable)
연구/조사의 주된 관심사가 되는 변수가 아닌 경우
주된 관심사에서 벗어난 독립변수
독립변수 이외에 종속변수에 영향을 미치는 독립변수이다.
일원 분산 분석 (One way ANOVA)
독립변수의 수에 따라 일원 분산 분석, 이원 분산 분석 등 나뉘게 되는데 독립변수의 수가 하나일 때, 즉 영향을 미치는 3개 이상의 집단을 가진 독립변수(범주형)가 하나일 때 일원 분산 분석을 사용한다.
일원 분산 분석의 식
= 독립변수의 그룹을 대표하는 문자
= 그룹내의 ID
= 평균
= 독립변수
= 우리의 모델로는 설명되지 않는 오차
종속변수 = 평균 + 독립변수 + 오차종속변수의 결과가 100% 독립변수의 영향이라고 볼 수 없다.
가설 식
- 귀무가설
독립변수에 따라 종속변수는 유의한 차이가 없다.
즉, 독립변수와 종속변수 간에는 관련성이 없다.
- 대립가설
독립변수에 따라 종속변수는 유의한 차이가 있다.
즉, 독립변수와 종속변수 간에는 관련성이 있다.
F-value F값이란
두 개의 분산의 비율
🚩첫 번째 분산
전체 평균으로부터 각 그룹의 평균까지의 거리
Between Variance라고 함
🤔첫 번째 분산인 Between Variance가 크다는 것은?
전체 평균으로부터 각 그룹의 평균값이 멀리 떨어져 있다.
따라서 적어도 어떤 그룹 한 개는 다른 그룹과 평균이 다를 수 있다.
🚩두 번째 분산
그룹내의 분산 (전체 그룹의 분산의 합산)
Within Variance의 의미
t-test의 t-value 계산시의 분모의 표준편차와 같은 의미
random한 (즉 무의미한) 변화의 정도임
Between Variance가 Within Variance보다 충분히 커야 Between Variance가 통계적으로 크다고 말할 수 있고, 이것을 적어도 어느 한 그룹의 평균값이 전체 평균과는 다르다고 할 수 있다.
F-value
분자부분의 분산을 비교대상인 분모부분의 분산과 비교하여 비율로써 나타낸 값
MS = 제곱합 (Mean Squred)
ex)
group = 독립변수
days = 종속변수
1그룹 : 약1
2그룹 : 약2
3그룹 : 플라시보
id days group group mean between within 1 5.3 1 6.000 0.194 0.490 2 6.0 1 6.000 0.194 0.000 3 6.7 1 6.000 0.194 0.490 4 5.5 2 5.950 0.240 0.203 5 6.2 2 5.950 0.240 0.063 6 6.4 2 5.950 0.240 0.203 7 5.7 2 5.950 0.240 0.063 8 7.5 3 7.533 1.195 0.001 9 7.2 3 7.533 1.195 0.111 10 7.9 3 7.533 1.195 0.134
전체평균으로부터 각 그룹의 평균까지의 거리의 분산 between variance
group1 =
group2 =
group3 =
자유도
group이 3개 이므로
그룹내의 분산 within variance
자유도
두개의 자유도를 합치면?
t-test의 자유도와 동일
결국 F-value
[유튜브 참고]
https://www.youtube.com/watch?v=HlSyvMRLu4w&list=PLalb9l0_6WArk6oZej3KzduU8TRQA9gcV&index=2
사후검정 (Post Hoc Test)
ANOVA를 통한 결과가 대립가설을 채택해 유의하다는 결과가 나오면 ANOVA의 결과만으로는 어떤 그룹이 다른지 알 수 없기 때문에 사후검정을 하게된다.
사후검정은 일종의 여러 다발의 t-test라고 보면 된다.
각 그룹의 평균이 다른 그룹의 평균과 같은지 다른지 개별 비교가 가능하다.
사후검정의 종류
- Fisher's LSD
- Bonferroni
- Sheffe
- Turkey
- Duncan
등이 있다.
