
회귀 모델 만들기
분류 모델 만들기
클러스터링 모델 만들기
데이터 정규화를 하는 이유
소감
<회귀 모델 만들기>
‘회귀’란 항목의 ‘특징’을 기반으로 숫자 ‘레이블’을 예측하는 데 사용되는 기계 학습의 한 가지 형태이다.
예를 들면, 차량에는 브랜드, 연료타입, 몸체타입, 엔진위치, 바퀴타입, 가격 등등 여러데이터들이 있다.
여기서 가격데이터를 측정하기위해 나머지 조건들을 적절히 정리하여 모델링하여 조건식을 만들어 이를 바탕으로 조건들을 입력했을때, 가격데이터가 측정되는 식이다.
모델링을 위한 데이터 셋 준비과정
머신러닝을 위해 작업할 데이터들을 정리한다.
-
원시데이터
말그대로 일단 편집하지않고 가져오는 원 데이터이다.
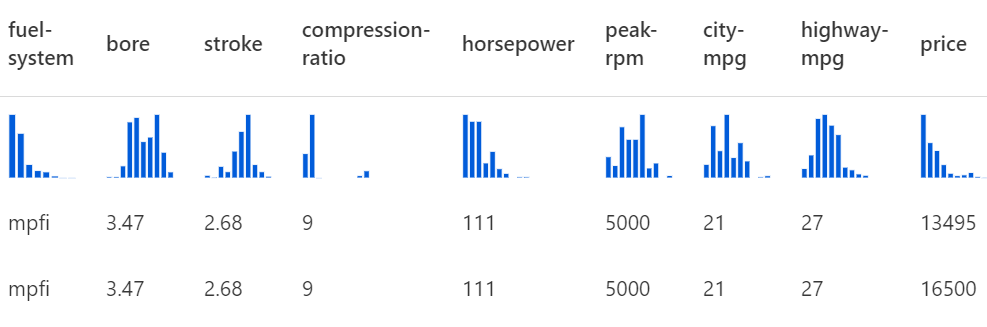
-
데이터 세트의 열 선택
모델링에 필요한 열을 선택한다.
정규화된 손실 열을 제외시키고, 작업에 필요한 열로만 정리한다. -
누락 데이터 정리
특정 열(머신러닝에 꼭 필요한 열)에 데이터가 누락되어있을경우, 머신러닝의 정확도를 위해 해당 행을 정리한다. -
데이터 정규화
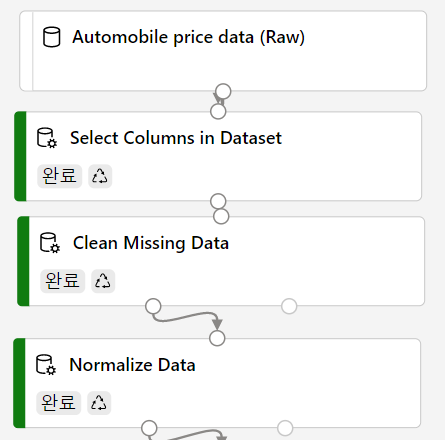
데이터 셋에 학습모듈을 추가
준비된 데이터 셋에 본격적인 머신러닝을 위한 모델 셋을 추가한다.
-
데이터 분할 모듈
데이터행을 분할시킨다. 이때 비율을 0.7로 머신러닝할 데이터와 모델의 평가를 위한 예시 데이터로 나누기 위해서이다. -
모델 학습 모듈
레이블 열 을 가격 으로 설정 -
모델 평가 모듈
Linear Regression 회귀 모델을 사용한다.
모델 채점 모듈로 모듈의 평가결과를 확인한다.
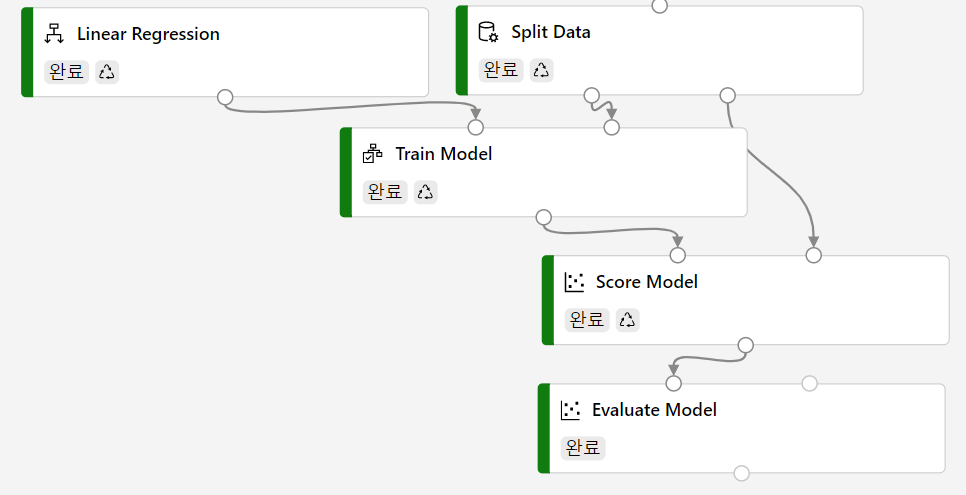
유추 파이프라인
해당 학습 파이프라인에서 실시간 유추 파이프라인을 추가한다. 배포를 위해 원시데이터의 입력 셀을 제거하고 마지막에 모델평가가 아닌, python 스크립트 실행을 추가하여 결과를 출력할 수 있게금 한다.
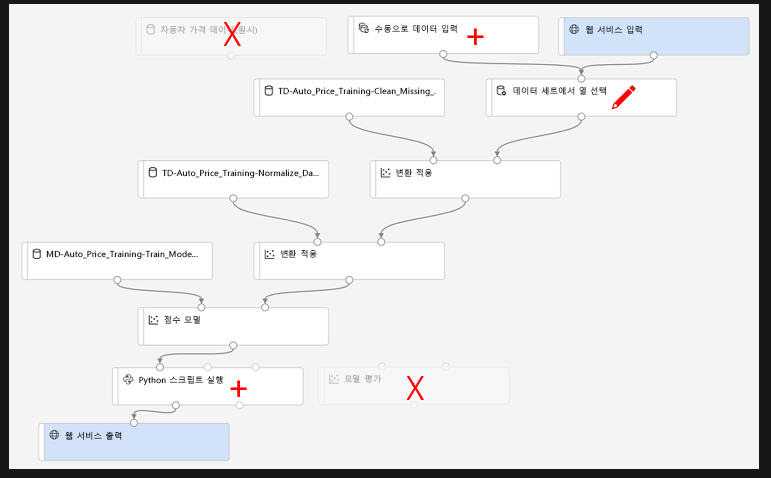
서비스 배포
실시간 유추 파이프라인을 배포하고 해당 REST엔드포인트와 기본키를 이용하여, Notebooks에서 실행시켜본다.
- 결과 확인
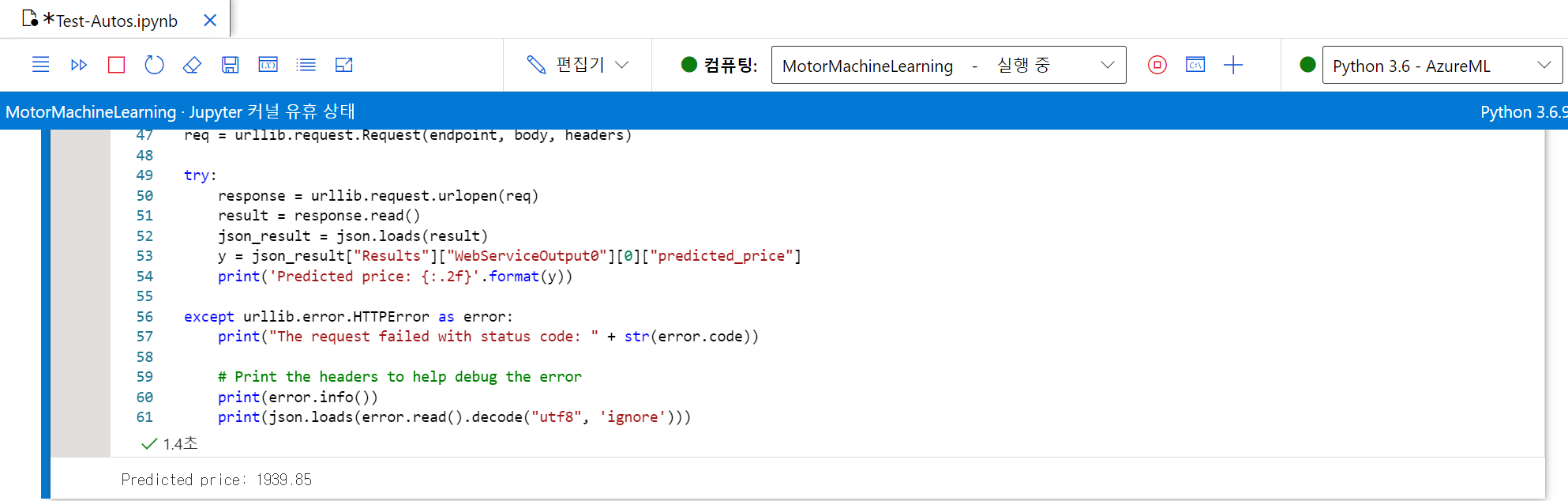
<분류 모델 만들기>
그 문제에서 추측하고 싶은 결과가 이름 혹은 문자일 때,
항목이 속한 범주 또는 클래스를 예측하는 데 사용되는 기계 학습의 한 형태이다.
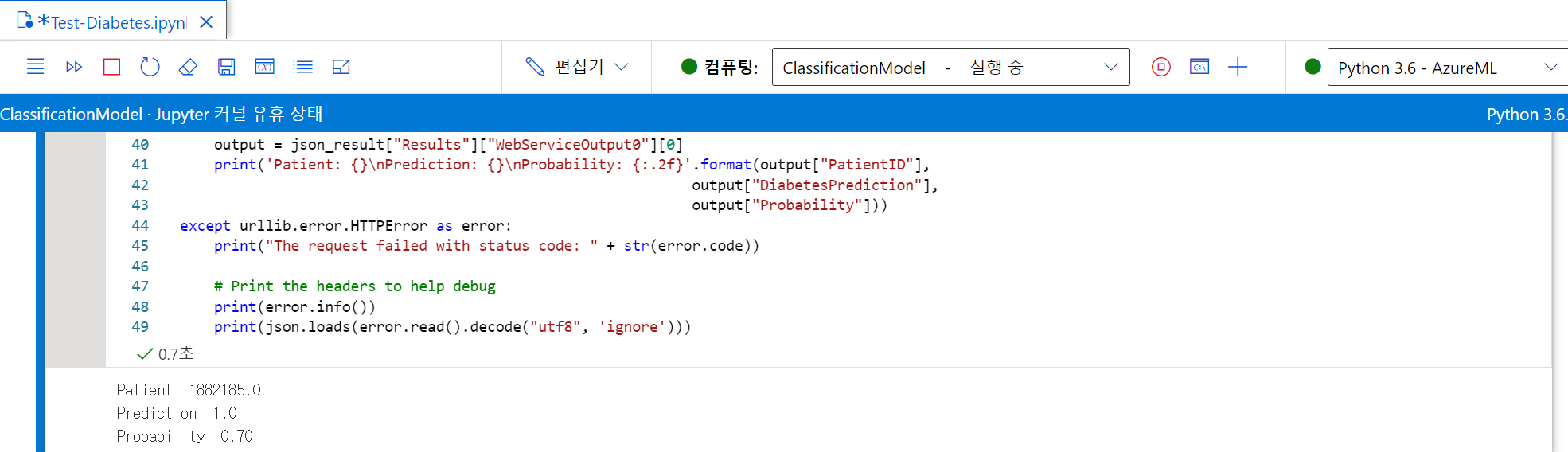
예를 들면, 진료소는 환자가 당뇨병이 걸릴 위험이 있는지를 예측하기 위하여 환자의 특성 (나이, 체중, 혈압 등)을 이용할 수 있다. 이 경우 환자의 특성이 특징이며, 레이블은 각각 당뇨병이 없거나 있는 환자를 나타내는 0 또는 1 이라는 분류이다.
모델링을 위한 데이터 셋 준비과정
머신러닝을 위해 작업할 데이터들을 정리한다.
-
원시데이터
당뇨병환자와 정상인 관련 데이터를 원시데이터로 사용한다.
https://aka.ms/diabetes-data -
그외는 회귀분석과 같다.
데이터 셋에 학습모듈을 추가
-
모델 평가 모듈
Two-Class Logistic Regression 모델을 사용한다. -
그외는 회귀분석과 같다.
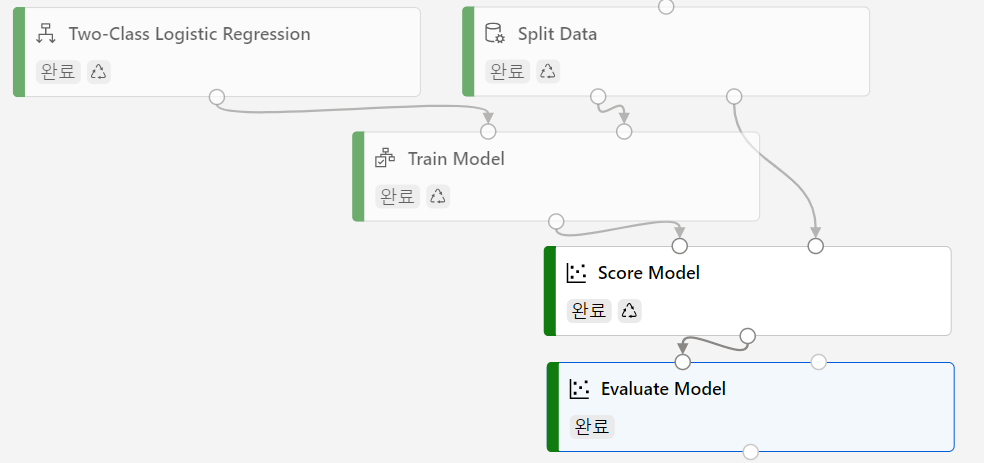
유추 파이프라인
해당 학습 파이프라인에서 실시간 유추 파이프라인을 추가한다. 배포를 위해 원시데이터의 입력 셀을 제거하고 마지막에 모델평가가 아닌, python 스크립트 실행을 추가하여 결과를 출력할 수 있게금 한다.
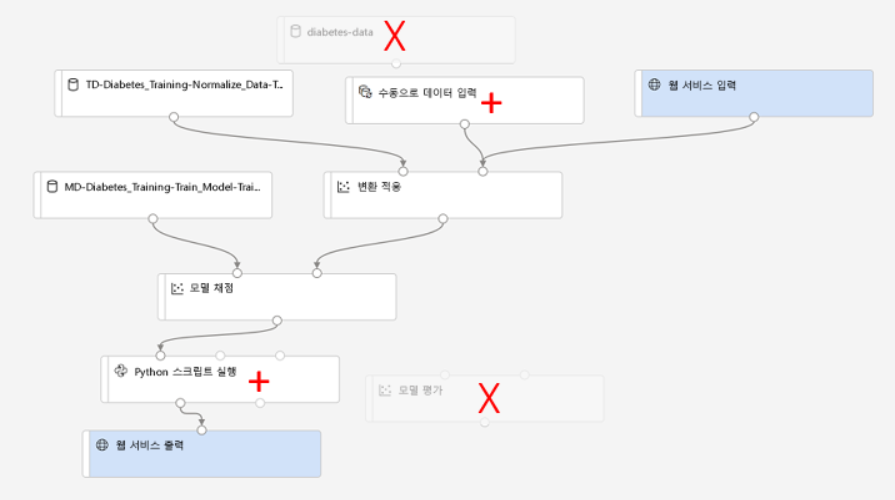
서비스 배포
실시간 유추 파이프라인을 배포하고 해당 REST엔드포인트와 기본키를 이용하여, Notebooks에서 실행시켜본다.
- 결과 확인
<클러스터링 모델 만들기>
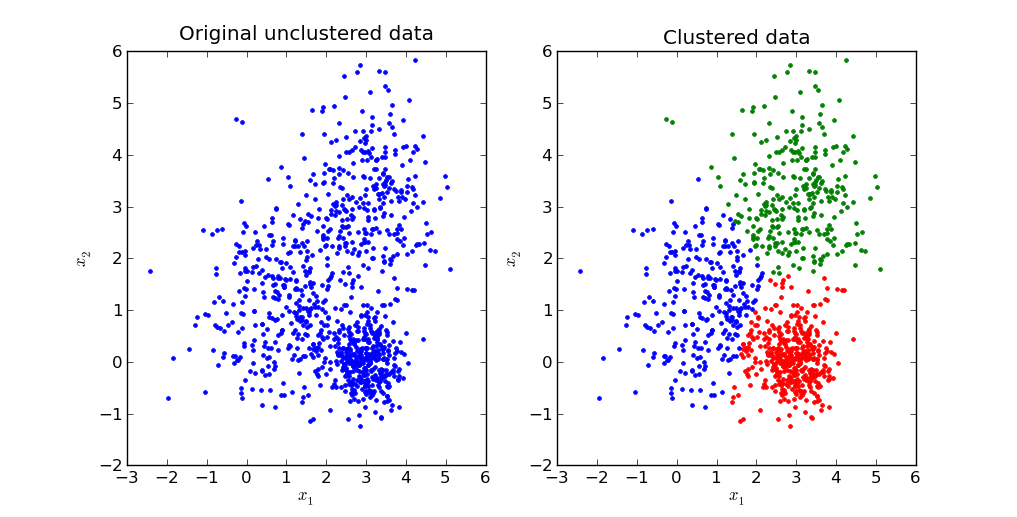
유사한 항목을 해당 특징에 따라 클러스터로 그룹화하는 데 사용되는 기계 학습의 한 형태이다.
예를 들어 연구원은 펭귄을 측정하고 비율의 유사성에 따라 그룹화할 수 있습니다.
모델링을 위한 데이터 셋 준비과정
머신러닝을 위해 작업할 데이터들을 정리한다.
-
원시데이터
펭귄의 종과 종별 데이터
https://aka.ms/penguin-data -
데이터 세트에서 열 선택
측정값만을 사용해 클러스터링 모델하기 때문에 '종' 열은 제외 시킨다. -
그외는 회귀분석과 같다.
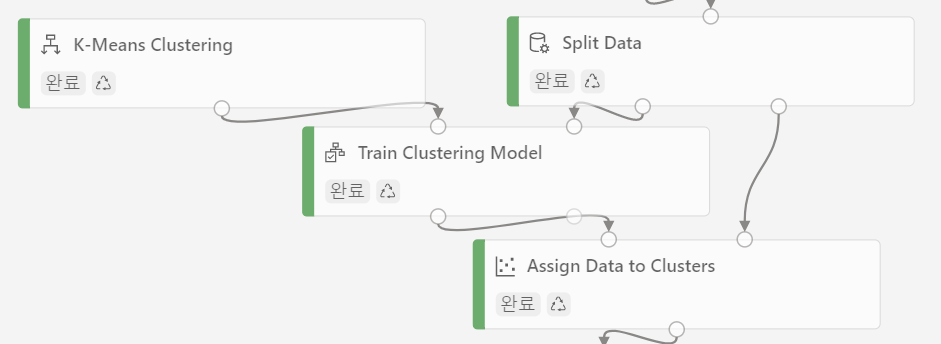
데이터 셋에 학습모듈을 추가
- 모델 평가 모듈
K-Means Clustering 모델을 사용한다.
‘가장 가까운’ 내부 거리를 가지는 클러스터를 고르는 것
- 그외는 회귀분석과 같다.
유추 파이프라인
해당 학습 파이프라인에서 실시간 유추 파이프라인을 추가한다.
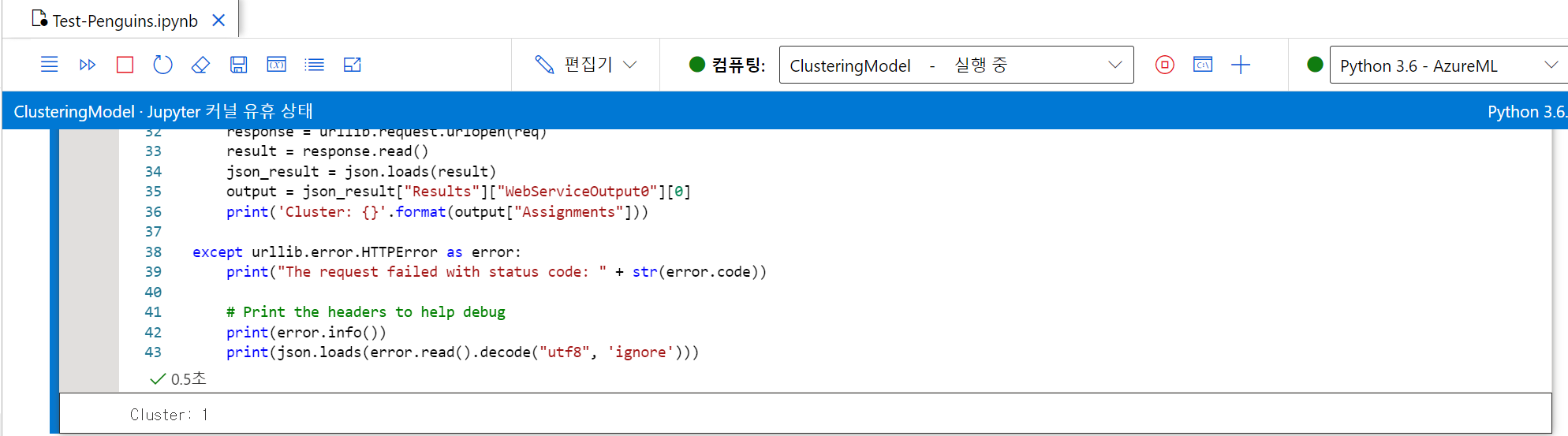
서비스 배포
실시간 유추 파이프라인을 배포하고 해당 REST엔드포인트와 기본키를 이용하여, Notebooks에서 실행시켜본다.
- 결과 확인
<데이터 정규화를 하는 이유>
- 편중을 최소화 하기 위해
예를 들어 Age 값의 범위는 21~77인 반면, DiabetesPedigree 값의 범위는 0.078~2.3016입니다. 기계 학습 모델을 학습할 때 큰 값에 결과 예측 함수가 좌지우지되어서 작은 규모에 대한 특징의 영향을 줄이는 경우가 간혹 있을 수 있습니다. 일반적으로 데이터 과학자는 숫자 열을 비슷한 기준에 기초하도록 정규화하여 편중을 최소화합니다.
<소감>
확실히 저번에 생활코딩에서 했던 머신러닝 야학이 도움이 크긴컸다. 용어나 전체적인 흐름을 다시 잡는데 큰 도움이 됬다. 근데 포스팅을 하긴했는데 자세히 못해서 좀 아쉬움이 남는다.
