.png)
결정트리(Decision Tree)는 분류(DecisionTreeClassifier)와 회귀(DecisionTreeRegressor)에 모두 사용이 가능하다.
또한 결정트리는 강력한 머신러닝 알고리즘 중 하나인 랜덤 포레스트의 기본 구성 요소이기도 하다.
의사 결정 트리는 데이터의 규칙을 학습을 통해 찾아내어 Tree 기반의 분류 규칙을 만든다.
의사 결정 트리는 데이터의 스케일링이 필요 없으며 비선형적인 관계를 처리가능하고 해석이 쉽다는 것이 특징이다. (단점으로는 선형적 관계는 잘 다루지 못한다.)
이용되는 디폴트 알고리즘은 CART(Classification and Regression Tree)로 gini 계수로 결정을 내린다. 각 특징들을 반복적으로 접근하여 잘못된 분류에 대한 가장 낮은 확률값을 도출하는 특징 값을 찾는다.
분류
결정 트리 학습 및 시각화
학습
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris() # iris 데이터를 사용하였다.
X = iris.data[:, 2:]
y= iris.target
# 학습
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X,y)시각화
!apt-get -qq install -y graphviz && pip install -q pydot
import pydot
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file="iris_tree.dot",
feature_names = iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
(graph,) = pydot.graph_from_dot_file('iris_tree.dot', encoding='utf8')
# dot 파일을 png로 저장
graph.write_png('iris_tree.png')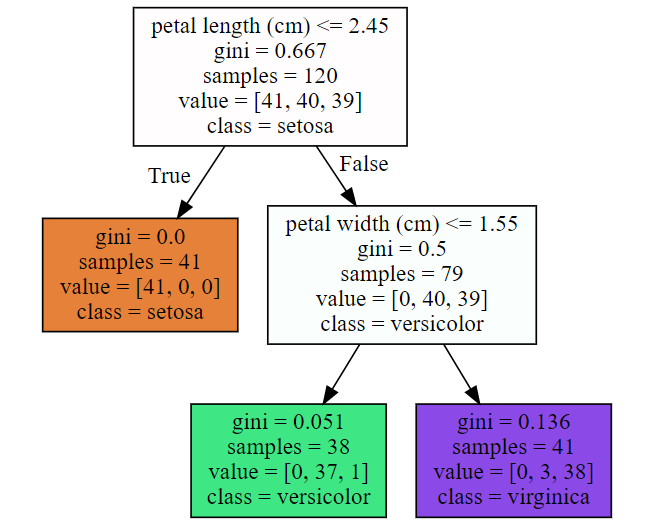
예측
맨 꼭대기 노드인 루트 노드에서 꽃잎의 길이가 2.45cm보다 짧은지 검사한다.
- True라면 왼쪽의 자식 노드로 이동한다. 왼쪽의 자식 노드는 자식 노드를 가지지 않는 리프 노드이므로 추가적인 검사를 진행하지 않고 setosa라고 예측한다.
- False라면 이 노드는 리프 노드가 아니라서 꽃잎의 너비가 1.55cm보다 작은지 검사한다.
노드의 sample속성은 적용된 train sample의 개수이다.
노드의 value속성은 각 클래스에 속하는 train sample의 개수이다.
노드의 gini속성은 불순도를 측정값이다. 한 노드의 모든 샘플이 모두 같은 클래스에 속해있다면 이 노드를 순수(gini=0)하다고 할 수 있다.
지니 불순도
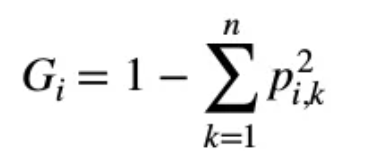
위 그림의 초록색 노드의 gini 계수는 다음과 같다.
1 - (0/38)^2 - (37/38)^2 - (1/38)^2 = 0.051
pred = tree_clf.predict(X_test)
확률 추정
proba_pred = tree_clf.predict_proba(X_test)CART 알고리즘

훈련 세트를 하나의 특성의 임곗값을(꽃잎의 길이 < 2.45) 사용해 두 개의 서브셋으로 나눈다.
특성과 임계값은 가장 순수한 서브셋을 나눌 수 있는 것을 선택한ㄷ.
이런식으로 계속 반복하고 최대 깊이가 되면 중지하거나 불순도를 줄이는 분할을 찾을 수 없을 때 멈추게 된다. (탐욕적 알고리즘)
지니 계수 or 엔트로피
default값은 지니 계수이지만 criterion매개 변수를 'entropy'로 지정하여 엔트로피 불순도를 사용할 수 있다.
엔트로피에 대해 알아보기에 앞서 정보이론에 대해 소개하겠다.
정보이론은 데이터를 정량화하기 위한 응용수학의 분야 중 하나로, 정보이론에서 말하는 정보량은 불확실성의 정도를 의미한다.
정보량이 높다는 것은 어떤 일이 일어날 확률이 낮다 ➡ 불확실하다.
이 때, 정보량이 높은 문장이 맞을수록 해당 정보의 중요도가 높아진다.
엔트로피는 이 정보량의 평균을 말한다.
즉, 엔트로피는 불확실성 측정의 척도이다.
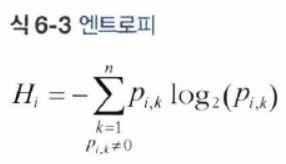
규제 매개변수
결정트리에 제한을 두지 않으면 트리가 과대적합 되기가 쉽다.
이런 과대적합을 피하기 위해 max_depth 매개변수로 결정 트리의 최대 깊이를 제어할 필요가 있다.
보통 min_으로 시작하는 매개변수를 증가시키거나, max_로 시작하는 매개변수를 감소시키면 모델에 대한 규제가 커진다.
max_depth: 결정 트리의 최대 깊이
max_depth를 감소시키면 모델에 대한 규제가 커진다. (즉, 과대적합 위험 감소)
min_samples_split: 분할되기 위해 노드가 가져야 하는 최소 샘플 개수
min_samples_split을 증가시키면 모델에 대한 규제가 커진다. (즉, 과대적합 위험 감소)
min_samples_leaf: 리프 노드가 가지고 있어야 할 최소 샘플 개수
min_samples_leaf를 증가시키면 모델에 대한 규제가 커진다. (즉, 과대적합 위험 감소)
min_weight_fraction_leaf: min_samples_leaf와 같지만, 가중치가 부여된 전체 샘플 수에서의 비율
min_weight_fraction_leaf를 증가시키면 모델에 대한 규제가 커진다. (즉, 과대적합 위험 감소)
max_leaf_nodes: 리프 노드의 최대 개수
max_leaf_nodes를 감소시키면 모델에 대한 규제가 커진다. (즉, 과대적합 위험 감소)
max_features: 각 노드에서 분할에 사용할 특성의 최대 개수
max_features를 감소시키면 모델에 대한 규제가 커진다. (즉, 과대적합 위험 감소)
규제 매개변수가 없을 때
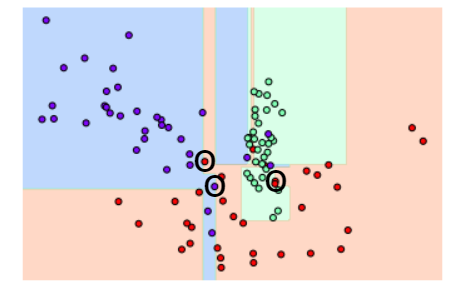
규제 매개변수 min_samples_leaf를 적용했을 때
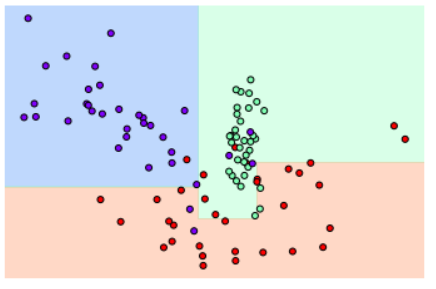
이상치 하나하나에 크게 반응하지 않으면서 좀 더 일반화된 분류 규칙을 찾아낸다.
회귀
앞서 말했듯이 결정트리는 회귀에도 사용할 수 있다. (DecisionTreeRegressor을 사용)
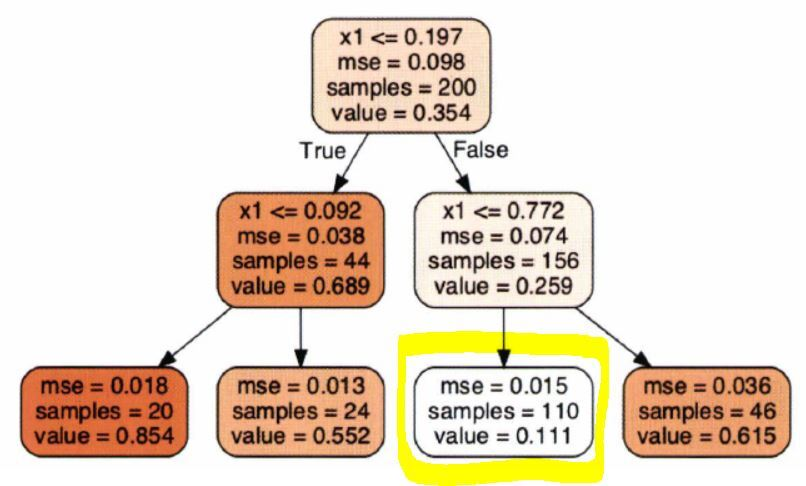
위 회귀 결정 트리에서 x1 = 0.6인 샘플의 타겟값를 예측한다고 가정한다면 결국 노란 네모 박스 안의 노드로 도착하게 된다.
해당 리프 노드에 있는 110개의 훈련 샘플의 평균 target값이 예측값이 된다.
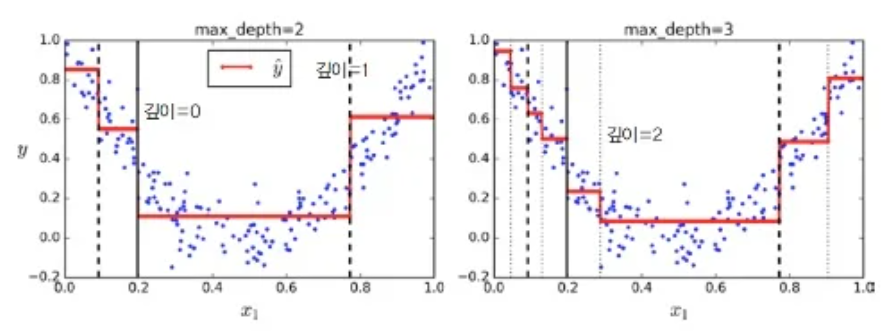
각 영역의 예측값은 그 영역에 있는 target값의 평균이 되고
예측값과 가능한 많은 샘플이 가까이 있도록 영역을 분할한다.
 회귀 결정 트리에서 CART 알고리즘은 불순도를 최소화하는 방향이 아닌 MSE를 최소화하도록 분할한다.
회귀 결정 트리에서 CART 알고리즘은 불순도를 최소화하는 방향이 아닌 MSE를 최소화하도록 분할한다.
단점
결정 트리 모델의 주된 문제점은 훈련 데이터에 있는 작은 변화에도 매우 민감하다는 점이다.
이 문제점을 해결하는 방법은 PCA(주성분 분석) 기법을 사용하는 것이다.
- 랜덤포레스트는 많은 트리에서 만든 예측을 평균하여 불안정성을 극복한다.
